
Gesundheitsdaten gehören zu den sensibelsten Informationen in der medizinischen Forschung. Entsprechend streng sind die rechtlichen Anforderungen an ihre Verarbeitung nach der Datenschutz-Grundverordnung. Dennoch besteht in der Praxis häufig Unsicherheit darüber, wie Daten datenschutzrechtlich korrekt einzuordnen sind.
Insbesondere die Begriffe Anonymisierung und Pseudonymisierung werden oft synonym verwendet. Dabei unterscheiden sie sich grundlegend in ihrer rechtlichen und praktischen Bedeutung. Wer diese Unterschiede nicht klar versteht, riskiert Fehlentscheidungen in Studienplanung und Datenmanagement.
Dieser Beitrag erläutert die Unterschiede zwischen Anonymisierung und Pseudonymisierung bei Gesundheitsdaten und ordnet ihre Bedeutung für die medizinische Forschung systematisch ein.
Anonymisierung bei Gesundheitsdaten
Definition und rechtliche Grundlage
Anonymisierung entfernt den Personenbezug eines Datensatzes dauerhaft und irreversibel. Daten gelten nur dann als anonymisiert, wenn sich die betroffene Person weder direkt noch indirekt identifizieren lässt. Entscheidend ist dabei nicht allein der einzelne Datensatz, sondern der gesamte Verarbeitungskontext.
Die Datenschutz-Grundverordnung definiert Anonymisierung nicht ausdrücklich. Sie stellt jedoch klar, dass anonymisierte Informationen nicht in ihren Anwendungsbereich fallen. Erwägungsgrund 26 erläutert, dass Daten nur dann als anonym gelten, wenn eine Identifizierung auch unter Einbeziehung zusätzlicher Informationen praktisch ausgeschlossen ist.
Praktische Umsetzung
In der Praxis reicht es nicht aus, direkte Identifikatoren wie Name oder Versicherungsnummer zu entfernen. Auch sogenannte Quasi-Identifikatoren können eine Person identifizierbar machen, wenn sie in Kombination auftreten. Hierzu zählen beispielsweise Alter, Geschlecht, Postleitzahl, Diagnose oder Behandlungszeitraum.
Um eine Re-Identifizierung zu verhindern, setzen Verantwortliche mehrere kombinierte Maßnahmen ein:
- Entfernung direkter Identifikatoren
- Generalisierung einzelner Merkmale, etwa Zusammenfassung von Alterswerten in Gruppen
- Reduktion geografischer Detailtiefe
- Aggregation oder Unterdrückung seltener Merkmalskombinationen
- statistische Maskierung einzelner Werte
In der Datenwissenschaft beschreibt unter anderem das Konzept der k-Anonymität dieses Prinzip. Ziel ist es, die Einzigartigkeit einzelner Datensätze so weit zu reduzieren, dass eine Identifizierung realistisch nicht mehr möglich ist.
Grenzen und methodische Folgen
Gerade bei Gesundheitsdaten ist eine vollständige Anonymisierung anspruchsvoll. Medizinische Datensätze enthalten häufig detaillierte klinische Informationen, die in Kombination eine Identifizierung begünstigen können. Seltene Erkrankungen oder kleine Studienpopulationen erhöhen dieses Risiko zusätzlich.
Zudem führt eine irreversible Anonymisierung dazu, dass kein Rückbezug mehr möglich ist. Follow-up-Erhebungen, Sicherheitsmeldungen oder Datenkorrekturen lassen sich dann nicht mehr individuell zuordnen. Für viele klinische Studien wäre dies praktisch nicht umsetzbar.
Je stärker Daten anonymisiert werden, desto größer wird häufig der Informationsverlust für statistische Analysen. Eine echte Anonymisierung erfordert daher eine bewusste Abwägung zwischen Datenschutz und wissenschaftlicher Aussagekraft.
Pseudonymisierung bei Gesundheitsdaten
Definition und rechtliche Grundlage
Pseudonymisierung ersetzt Identitätsmerkmale, erhält jedoch die Möglichkeit eines späteren Rückbezugs. Im Unterschied zur Anonymisierung bleibt die Zuordnung jedoch grundsätzlich möglich, da ein separater Identifikationsschlüssel existiert.
Die Datenschutz-Grundverordnung definiert Pseudonymisierung ausdrücklich als eine Schutzmaßnahme. Gleichzeitig stellt sie klar, dass pseudonymisierte Daten weiterhin als personenbezogene Daten gelten. Der Personenbezug entfällt also nicht.
Praktische Umsetzung
In klinischen Studien ersetzen Verantwortliche direkte personenbezogene Identifikatoren wie Name, Geburtsdatum oder Krankenversicherungsnummer durch eine zufällig generierte Studien-ID. Diese Kennung enthält keine sprechenden Informationen und erlaubt für sich genommen keinen Rückschluss auf die Identität der betroffenen Person.
Auch zentrumsbezogene Angaben erscheinen im Analysedatensatz in codierter Form. Anstelle des Kliniknamens wird beispielsweise ein neutraler Zentrumscode wie „Site-03“ verwendet. Die Zuordnung zwischen Studien-ID, Zentrumscode und realer Identität wird getrennt in einer geschützten Schlüsseldatei gespeichert.
Der für statistische Auswertungen verwendete Datensatz enthält somit ausschließlich codierte Informationen:
| Studien-ID | Zentrumscode | Alter | Geschlecht | Biomarker vor Therapie | Biomarker nach Therapie |
| SUBJ-00125 | Site-03 | 46 | weiblich | 8,4 | 6,9 |
| SUBJ-00126 | Site-03 | 52 | männlich | 7,8 | 7,2 |
| SUBJ-00480 | Site-07 | 49 | weiblich | 9,1 | 7,5 |
Dieser Datensatz ermöglicht eine wissenschaftliche Analyse, ohne direkte Identitätsmerkmale offenzulegen.
Die personenbezogene Zuordnung wird separat verwahrt:
| Studien-ID | Name | Geburtsdatum | Adresse |
| SUBJ-00125 | Maria Beispiel | 14.03.1978 | Musterstraße 1 |
| SUBJ-00126 | Thomas Muster | 22.09.1972 | Beispielweg 4 |
| SUBJ-00480 | Anna Demo | 03.01.1977 | Klinikstraße 12 |
Nur autorisierte Personen dürfen auf diese Zuordnungstabelle zugreifen. In vielen Studien übernimmt eine unabhängige Stelle oder eine Trusted Third Party das Identitätsmanagement, um die organisatorische Trennung zusätzlich abzusichern.
Auch die Zuordnung der Studienzentren erfolgt getrennt:
| Zentrumscode | Klinikname | Ort |
| Site-03 | Universitätsklinikum | Hamburg |
| Site-07 | Klinikum Nord | Frankfurt am Main |
Durch diese dreistufige Struktur reduzieren Verantwortliche die Identifikationswahrscheinlichkeit erheblich. Der Personenbezug bleibt jedoch bestehen, da eine Rekonstruktion über die getrennt gespeicherten Zuordnungen grundsätzlich möglich ist. Genau deshalb gelten pseudonymisierte Gesundheitsdaten weiterhin als personenbezogene Daten.
Grenzen und verbleibender Personenbezug
Der entscheidende Unterschied zur Anonymisierung liegt im fortbestehenden Personenbezug. Solange eine Schlüsseldatei existiert, bleibt eine Identifizierung grundsätzlich möglich. Entscheidend ist, dass eine Re-Identifizierung mit vertretbarem Aufwand möglich bleibt, auch wenn die auswertenden Personen keinen direkten Zugriff auf die Schlüsseldatei besitzen. Dieser Umstand führt dazu, dass pseudonymisierte Daten weiterhin als personenbezogen gelten und vollständig der DSGVO unterfallen.
Die Grenze der Pseudonymisierung liegt daher weniger in der technischen Struktur als in der organisatorischen Verantwortung. Verantwortliche müssen sicherstellen, dass die Zuordnungsschlüssel getrennt gespeichert, der Zugriff strikt begrenzt und die Prozesse transparent dokumentiert werden.
Die Pseudonymisierung schafft somit keinen anonymen Raum, sondern ein kontrolliertes Datenumfeld. Sie reduziert Risiken, ersetzt jedoch nicht die datenschutzrechtliche Verantwortung.
Warum die Unterscheidung in der medizinischen Forschung entscheidend ist
In der Forschungspraxis wirken sich die Unterschiede zwischen Anonymisierung und Pseudonymisierung insbesondere in drei Bereichen aus: rechtlich, organisatorisch und wissenschaftlich.
Rechtliche Einordnung
Maßgeblich ist zunächst, ob im Rahmen eines Forschungsprojekts personenbezogene Gesundheitsdaten erhoben oder verarbeitet werden. In diesem Moment findet die Datenschutz-Grundverordnung Anwendung. Die spätere Datenstruktur entscheidet anschließend darüber, ob dieser Personenbezug fortbesteht oder endet.
Werden personenbezogene Daten erhoben, ist eine datenschutzrechtliche Grundlage erforderlich. Eine spätere Anonymisierung ersetzt diese ursprüngliche Rechtmäßigkeit nicht. Ebenso führt eine Pseudonymisierung nicht dazu, dass regulatorische Anforderungen entfallen. Sie reduziert das Risiko, während die datenschutzrechtliche Verantwortung bestehen bleibt.
Wird ein Datensatz vollständig und irreversibel anonymisiert, entfällt der Personenbezug für diese konkreten Daten. Bleibt hingegen ein Rückbezug über eine getrennt gespeicherte Schlüsseldatei möglich, handelt es sich weiterhin um personenbezogene Daten in pseudonymisierter Form. In diesem Fall gelten die datenschutzrechtlichen Pflichten fort, auch wenn Identitäten im Analysesystem nicht sichtbar sind.
Organisatorische Auswirkungen
Darüber hinaus wirkt sich die gewählte Datenstruktur auf organisatorische Prozesse aus. Bei pseudonymisierten Daten müssen Zugriffsbeschränkungen, Schlüsselverwaltung und Dokumentation klar geregelt sein. Bei tatsächlich anonymisierten Daten entfällt dieser personenbezogene Bezug, allerdings um den Preis der fehlenden Rückverfolgbarkeit.
Wissenschaftliche Konsequenzen
Auch für die wissenschaftliche Nutzbarkeit ist die Unterscheidung wesentlich. Eine vollständige Anonymisierung schließt jede spätere Zuordnung aus. Follow-up-Erhebungen oder Korrekturen lassen sich dann nicht mehr einer bestimmten Person zuordnen. Pseudonymisierung ermöglicht hingegen eine kontrollierte Nachverfolgbarkeit, ohne Identitäten im Analysesystem offenzulegen.
Die begriffliche Präzision ist daher keine formale Detailfrage. Sie bildet die Grundlage für ein konsistentes Studiendesign, eine rechtlich tragfähige Datenverarbeitung und eine langfristig nutzbare Forschungsstrategie.
Die folgende Abbildung verdeutlicht das Spannungsfeld zwischen Personenbezug und wissenschaftlicher Nachverfolgbarkeit in der Forschungspraxis.
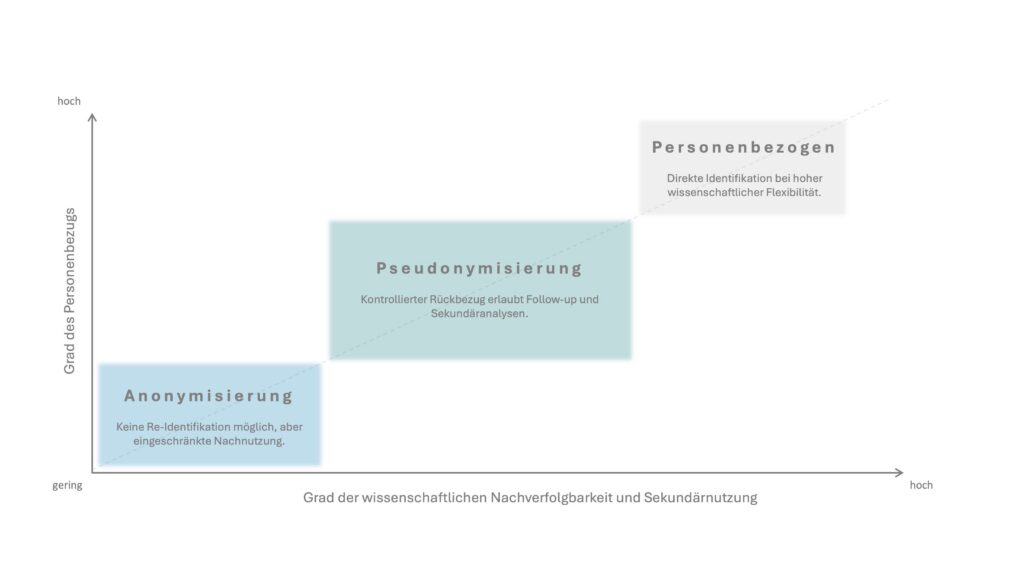
Es handelt sich folglich um keine rein technischen Varianten, sondern um unterschiedliche strategische Entscheidungen im Studiendesign.
Fazit
Der zentrale Unterschied zwischen Anonymisierung und Pseudonymisierung liegt darin, ob ein Personenbezug weiterhin besteht. Eine echte Anonymisierung schließt jede Identifizierbarkeit dauerhaft aus. Eine Pseudonymisierung trennt Identitätsdaten organisatorisch und technisch vom Analysedatensatz, ermöglicht jedoch grundsätzlich einen Rückbezug.
Solange ein solcher Rückbezug möglich bleibt, gelten die Daten weiterhin als personenbezogen. Entsprechend bestehen die datenschutzrechtlichen Anforderungen fort. Erst wenn eine Identifizierung auch mittelbar ausgeschlossen ist, entfällt der Personenbezug für diesen Datensatz.
Die wesentlichen Unterschiede zwischen Anonymisierung und Pseudonymisierung lassen sich wie folgt zusammenfassen:
| Anonymisierung | Pseudonymisierung | |
| Personenbezug | entfällt vollständig | bleibt bestehen |
| Rückbezug möglich | nein | ja |
| Datenschutzrechtliche Einordnung | kein Personenbezug mehr | weiterhin personenbezogen |
| Follow-up möglich | nein | ja |
| Schlüsselverwaltung | nicht erforderlich | erforderlich |
Für die klinische Forschung bedeutet dies: Pseudonymisierung ermöglicht wissenschaftliche Nachverfolgbarkeit bei reduziertem Identifikationsrisiko, während Anonymisierung einen vollständigen, aber irreversiblen Schutz bietet. Die bewusste Entscheidung zwischen beiden Konzepten ist daher ein wesentlicher Bestandteil einer tragfähigen Datenstrategie. Eine frühzeitige datenschutzrechtliche und methodische Einordnung schafft Planungssicherheit und verhindert spätere Anpassungen im Studiendesign.
Weiterführende Literatur:
European Data Protection Board (2025). Guidelines 01/2025 on Pseudonymisation. Abrufbar unter https://www.edpb.europa.eu/our-work-tools/documents/public-consultations/2025/guidelines-012025-pseudonymisation_de