

Data Mining wird auch als intelligente Datenanalyse bezeichnet. Bei der Data Mining Beratung identifizieren wir für Sie Muster und Regeln in grossen Datenmengen durch statistische Verfahren, künstliche Intelligenz (z.B. neuronale Netze) und Visualisierungstechniken. Dabei analysiert man nicht nur Daten aus der Vergangenheit, sondern trifft auch Vorhersagen für die Zukunft.
Unser Data Mining Service im Detail
Wir unterstützen gerne Sie mit folgenden Dienstleistungen:
- Data-Mining-Beratung: Wir unterstützen Sie in allen Phasen der Planung und Durchführung Ihres speziellen Data Mining-Projektes.
- Predictive Modeling: Aufgrund der Data Mining-Ergebnisse erstellen wir Prognosen. Zielführendes Vorgehen verlangt hierbei hohe Expertise und geht weit über eine einfache Extrapolation in die Zukunft hinaus.
- Big Data Mining: Damit Ihr Data Mining auch bei hohen und komplexen Datenmengen noch effizient funktioniert, helfen wir bei der Skalierung Ihrer Verfahren.
- Data Mining Deployment: Das Data Mining dient nicht nur dem Wissenszuwachs, sondern vor allem einem praktischen Zweck: Die gewonnenen Ergebnisse müssen nutzbringend angewendet werden, beispielsweise durch Segmentierung der Kunden in Kategorien, oder um eine angemessene Reaktion auf künftige Entwicklungen zu fundieren. Wir helfen Ihnen gerne, ein erfolgssicheres Konzept zu erstellen und umzusetzen.
- Visualisierung & Aufbereitung: Data Mining produziert grosse Mengen an Ergebnissen. Wir übernehmen deren übersichtliche, anschauliche und zielgruppengerechte Darstellung, bspw. mit Qlikview.
Sollten Sie Unterstützung bei einem Data Mining Projekt benötigen, helfen Ihnen unsere Statistiker gerne weiter. Nutzen Sie hierzu einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Welche Erfahrungen haben unsere Kunden mit Novustat gesammelt?
Google Rating
- Ich habe ausschließlich positive Erfahrungen mit Novustat gemacht. Angefangen mit einer freundlichen Erstberatung erfolgte … Mehr im gesamten Prozess eine kompetente Betreuung meines Anliegens. Selbst auf kurzfristige Änderungen wurde schnell reagiert. Generell ist die Erreichbarkeit besonders hervorzuheben, da mein Ansprechpartner teilweise wenige Minuten nach Kontaktaufnahme auf meine Fragen geantwortet hat. Das Projekt konnte zu meiner vollen Zufriedenheit abgeschlossen werden. Dementsprechend ist Novustat eine klare Empfehlung meinerseits!
- Meine Auswertungsdaten habe ich recht spontan erhalten und bin umso dankbarer, dass die Novustat Statistik-Beratung so kurzfristig … Mehr übernommen hat! Alle meine Zusatzfragen und -analysen wurden zu meiner Zufriedenheit geklärt und auch für Nachfragen & Erklärungen wurde sich viel Zeit genommen. So ist für mich alles verständlich und nachvollziehbar und ich bin sehr dankbar für ihre Flexibilität und Auswertung!
- Wirklich schnelle und professionelle Hilfe. Sofort nach Anfrage wurde mir weitergeholfen, sodass keine Zeit verloren ging … Mehr und ich konnte mich jederzeit mit Fragen an meinen Bearbeiter wenden und kurzfristig Gesprächstermine ausmachen. Sehr zu empfehlen!




Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Gerne können Sie sich unser Video zu unseren Unterstützungsmöglichkeiten auch bei Youtube anschauen.
Was ist Data Mining?
Data Mining ist ein Oberbegriff für Verfahren, die aus Daten Wissen erzeugen um fundierte Entscheidungen zu treffen. Seinen Einsatz findet es in der Grundlagenforschung genauso wie in der Marktforschung, Produktionsoptimierung oder bei Big Data im Gesundheitswesen. Eben überall dort, wo grosse Datenmengen (Big Data) erzeugt werden.
Diese Verfahren sind effizienter als die klassischen statistischen Auswertungen und können Korrelationen zwischen allen Daten suchen, Cluster von irgendwie ähnlichen Datensätzen entdecken und zeitliche oder geografische Muster finden. Hierzu werden effiziente Machine Learning Algorithmen, Verfahren der Datenvisualisierung und künstliche Intelligenz zum Einsatz gebracht.
Wozu Data Mining?
Heutzutage liegen Daten zumeist digital vor und Geschäftsprozesse werden elektronisch unterstützt und dokumentiert. Dadurch sammeln sich grosse Mengen an Daten an. Daten sind der Rohstoff unserer Wissensgesellschaft und stellen einen Schatz an Wissen dar, der nur mit Data Mining Methoden gehoben werden kann.
Data Mining dient dazu, um aus Daten Wissen zu erzeugen. Daten sind Zahlen, Wörter, Bilder, Fakten. Erst durch eine vernetzte Auswertung dieser Daten entsteht nützliches, zweckbezogenes Wissen, das hilft, Entscheidungen zu treffen oder anderweitig genutzt werden kann. Es geht dabei darum, Fakten zu beschreiben, Zusammenhänge zu erklären und zukünftige Entwicklungen vorzusagen. Im Gegensatz zu statistischen Verfahren, die Hypothesen prüfen (validieren), kann Data Mining zusätzlich auch Hypothesen erzeugen.
Anwendungsgebiete
Data Mining ist verbreitet in der Marktforschung, im Marketing, Vertrieb und in der Produktion, kann aber überall hilfreich sein, wo viele Daten anfallen. So zeigt beispielsweise der Vergleich verschiedener Krankenhäuser auf, welches in welchem Bereich am besten ist oder wo auch konkret Schwierigkeiten auftreten. Typische Fragestellungen, die das Data Mining behandelt, sind: Welche Produkte werden oft zusammen gekauft? (Beispielsweise: Bisquit-Tortenboden, Erdbeeren und Sahne.) Welche Faktoren sind ausschlaggebend für die Kundentreue? Gesucht werden oft auch wenn-dann-Regeln, Zusammenhänge in der Form von Entscheidungsbäumen oder Regeln in Aussagen- oder Prädikatenlogik.
Dieses Wissen unterstützt die Planung von Cross Selling, die Kundensegmentierung, die Prognose von Vertragslaufzeiten, Betrugserkennung, Business Intelligence und viele andere geschäftliche Tätigkeiten.
Data Mining Definition
Data Mining ist ein Sammelbegriff für verschiedene rechnergestützte Verfahren zur Auswertung grosser Datenmengen. Dabei werden nach Data Mining Definition Hypothesen erzeugt oder Hypothesen geprüft. Das Ziel ist es, Muster und Regeln in grossen Datenmengen zu entdecken, Abhängigkeiten zwischen Daten in Form von Gruppen (Clustern), Formeln, Korrelationen, Regelmässigkeiten (Mustern) und zeitlichen Trends. Zum Einsatz kommen hier statistische und mathematische Verfahren, künstliche Intelligenz (z.B. neuronale Netze) und Visualisierungstechniken.
Typische Fragestellungen im Data Mining
- Welche Faktoren beeinflussen, dass ein Kunde einen Kredit zurückbezahlt?
- Welche Faktoren verursachen eine bestimmte Krankheit oder beschleunigen die Heilung?
- Welches Produkt wird ein bestimmter Kunde wahrscheinlich kaufen?
- Prädiktion von Kundenabwanderung (Churn Management Predictive Analytics)
Solches Wissen unterstützt die Planung von Marketingaktionen, Prognosen, Betrugserkennung, Business Intelligence und viele andere geschäftliche Tätigkeiten.
Unsere Leistungen im Bereich Data Mining Beratung
- Beratung bei der Planung: Was soll mit dem Data Mining Projekt verfolgt werden? Ist das Ziel erreichbar? In welcher Zeit und mit welchem Aufwand? Welche Voraussetzungen müssen dafür gegeben sein?
- Beratung zur Datenerhebung: Wo kann man wie welche Daten erheben? Welche Data Mining Methoden stehen zur Verfügung? Wie müssen Fragen formuliert sein? Welche Kennzahlen eignen sich, um eine bestimmte Frage zu beantworten?
- Beratung bei Datenschutzfragen: Welche Daten dürfen für welchen Zweck ausgewertet werden? Wie anonymisiert man Daten zuverlässig? Wir Programmieren Ihren gerne Ihre Anonymisierungs-Routine.
- Unterstützung bei der Daten-Aufbereitung: Wir helfen Ihnen, Ihre Daten zusammenzuführen und deren Qualität zu verbessern, also bei Bereitstellen, Integration, Migration und Bereinigung.
- Unterstützung bei der Auswertung: Novustats Experten kennen sich mit allen Methoden und Werkzeugen des Data Mining aus und helfen Ihnen beim Aufsetzen und Programmieren der Auswertungen, prüfen Ihren Code auf Fehler oder führen eine Zweitauswertung durch, um Ihre Ergebnisse zu bestätigen.
- Interpretation und Darstellung der Ergebnisse: Gerne helfen wir Ihnen auch bei der Deutung Ihrer Ergebnisse und der zielgruppengerechten Aufbereitung Ihrer Erkenntnisse für Geldgeber, Kunden, Geschäftsleitung oder Öffentlichkeit.
Warum ist häufig im Rahmen von Data Mining Beratung notwendig?
Die Methoden und die Vorgehensweisen der klassischen Statistik genügen nicht fürs Data Mining. Neue Methoden sind für diesen Zweck entwickelt worden wie beispielsweise
- das Clustering,
- Klassifikation,
- Crossvalidation,
- Entscheidungsbaum
- die Segmentierung und
- die Aggregation von Datensätzen
Unter anderem deshalb benötigen die meisten Menschen im Rahmen von Data Mining Beratung von spezialisierten Dienstleistern.
Während klassische statistische Auswertungen sich oft überschaubar in zwei oder drei Dimensionen bewegen und z.B. Korrelationen zwischen zwei Variablen untersuchen bzw. Unterschiede zwischen zwei Gruppen von Probanden, handelt es sich bei den Daten und Auswertungen des Data Mining um mehrdimensionale Probleme.
Für wen eignet sich Data Mining Beratung?
Unsere Statistik Beratung ist universell ausgelegt und bietet Ihnen auf jeden Fall qualifizierte Statistik Hilfe. Unser Service ist für alle Interessenten, insbesondere Firmenkunden geeignet, die sich individuell mit spezifischen Fragen des Data Mining auseinandersetzen wollen, unabhängig vom:
- Wohnort: Für unsere Statistikberatung ist lediglich ein Internetanschluss notwendig
- wissenschaftliche oder betriebliche Anliegen: wir finden den passenden Experten für Ihre Herausforderung!
- Vorwissen: Wir holen sie ab, und passen uns Ihren Bedürfnissen an
- Anwendungsgebiet: Mit unseren Statistikexperten können wir insbesondere finanzwissenschaftliche, ökonomische, biologische, medizinische, psychologische und marketing Anwendungen hervorragend unterstützen und unser Fachwissen anwendungsorientiert einbringen.
Wie wird die Beratung durchgeführt?
Die Data Mining Beratung findet Online mit Bildschirmübertragung statt. Wir verwenden für das Coaching Skype, Zoom bzw. MS Teams. Alternative Medien können beispielsweise bei Firmenkunden verwendet werden, wenn der Kunde das Meeting organisiert. Im Rahmen einer Statistik Beratung beraten sie unsere Experten in Hinblick auf Ihre Problemstellung und zeigen Ihnen Lösungsansätze auf. Eine Auswertung von unserer Seite findet im Rahmen einer Statistik Beratung nicht statt. Diese Leistung kann übrigens auch separat in Anspruch genommen werden.
Sollten Sie Unterstützung in Form einer Data Mining Beratung benötigen, helfen Ihnen unsere Statistiker gerne weiter. Nutzen Sie hierzu einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
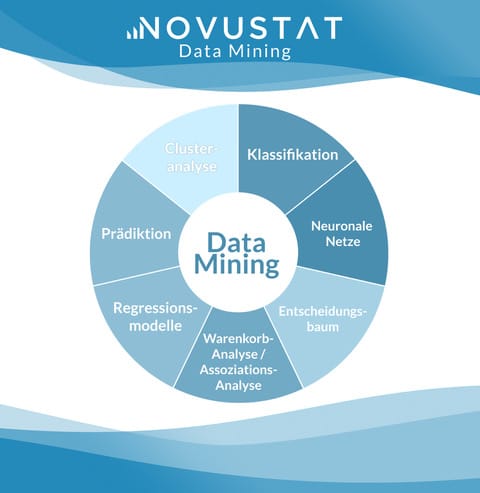
Gängige Data Mining Methoden
Zum Data Mining gehört nicht nur die Auswertung der Daten, sondern auch deren Zusammenführung, Datenbereinigung und sonstige Vorbereitung. Bei der Datenauswertung geht es meist darum, eine konkrete Frage zu beantworten. Exploratives Data Mining ist auch möglich, bei dem man aus den Daten Hypothesen erzeugt.
Verfahren, die häufig angewendet werden, sind unter anderem:
Clustering
Beim Clustering geht es darum, Gruppen von Daten zu finden (so genannte Cluster). Ein Cluster ist eine Menge von Objekten, die untereinander eine hohe Ähnlichkeit bezüglich bestimmten Eigenschaften aufweisen. Hierzu stehen eine Vielzahl an Cluster-Algorithmen zur Verfügung. Die Schwierigkeit besteht darin, die Variablen und Algorithmen zu finden, die zu den Daten und der Fragestellung passen.
Klassifikation
Für die Klassifikation werden die Objekte anhand von Kriterien in Klassen eingeordnet, passend zur gestellten Frage.
Segmentierung
Segmentierung ist eine zweckmässige Klassifikation der Daten. Diese Zweckmässigkeit hängt natürlich von der gestellten Frage ab. Kunden kann man z.B. segmentieren nach der Häufigkeit oder Grösse ihrer Bestellungen, nach ihrer Zahlungszuverlässigkeit, nach Postleitzahl, Alter, usw.
Extraktion
Bei der Extraktion werden die für die gestellte Frage relevanten Daten aus der Gesamtheit der Daten selektiert. Je nach Art der Daten können hier auch linguistische Verfahren für Textdaten sinnvoll sein oder selbstlernende Verfahren (z.B. mit neuronalen Netzen).
Abhängigkeitsanalysen (z.B. Korrelationsanalysen oder Regression)
Hierbei werden Abhängigkeiten zwischen zwei Variablen berechnet, z.B. zwischen Alter und gemachtem Umsatz. Kaufen ältere Kunden mehr von einem bestimmten Produkt oder eher weniger?
Validierung
Zusammenhänge, die man in den Daten gefunden hat, sollte man anschliessend anhand anderer Daten validieren. Dazu teilt man die vorhandenen Daten oft von Anfang an in zwei Gruppen auf: die Trainings- und die Testdaten. Anhand der Trainingsdaten werden z.B. neuronale Netze trainiert und anhand der Testdaten dann geprüft, ob der erlernte Algorithmus funktioniert. Durch diese Validierung kann man vermeiden, dass Muster, die zufällig in einem Teil der Daten auftreten, fälschlicherweise als allgemeingültig angesehen werden.
Werkzeuge im Rahmen der verschiedenen Data Mining Methoden
Entsprechend der Data Mining Methoden kann man auch die Werkzeuge in verschiedene Kategorien einteilen:
- Statistik-Software unterstützt die üblichen statistischen Verfahren wie die Regressions- und Korrelationsanalyse sowie multivariate Analysen, z.B. Mining mit R oder SPSS Auswertung.
- Künstliche Intelligenz erlaubt die Muster- und Regelerkennung, insbesondere Software für maschinelles Lernen wie RapidMiner oder TensorFlow.
- Cluster-Analyse-Werkzeuge finden Cluster in den Daten.
- Werkzeuge zur Sprachverarbeitung analysieren natürlich-sprachliche Texte.
- Daten-Visualisierungswerkzeuge stellen Daten und deren Eigenschaften grafisch dar.
Nähere Informationen zu diesen Werkzeugtypen und zugehörigen Werkzeugen finden Sie hier.
Die optimalen Data Mining Methoden für Ihre Daten
Natürlich sollte die Data Mining Methode sowie Werkzeuge passend zu Ihrer Fragestellung ausgesucht werden. Wir unterstützen Sie bei der Auswahl des bestmöglichen Verfahrens bzw wenden es in Ihrem Auftrag an.
Die Phasen
Daten werden iterativ exploriert. Das heisst, man tastet sich an die Ergebnisse heran. Man unterscheidet dabei folgende Phasen, welche beliebig oft wiederholt werden können:
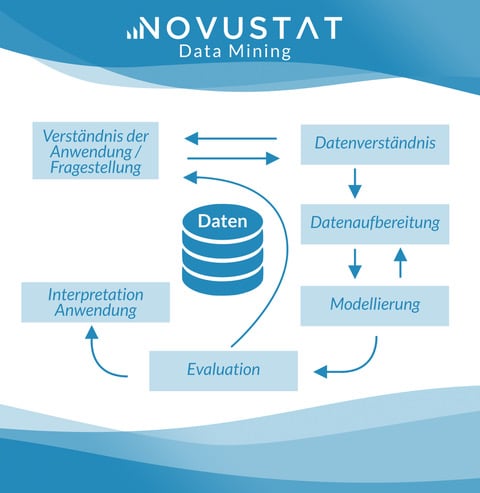
1. Datenauswahl und -bereinigung
In diesem Schritt selektiert man die zu analysierenden Daten und bereinigt unvollständige bzw nicht plausible Datensätze gegebenenfalls werden die Daten in ein anderes Format umgewandelt.
2. Datenexploration
Für grosse Datenmengen ist eine systematische Suche zu zeitaufwendig. Daher verwendet man heuristische Suchverfahren. Hierbei betrachtet man die Daten aus verschiedenen Perspektiven, um konkrete Erwartungen bestätigt zu finden sowie sich durch die Ergebnisse überraschen zu lassen. Die Datenexploration wird dabei durch Visualisierungstools unterstützt, welche die bildliche Darstellung der Daten und ihrer Eigenschaften in mehreren Dimensionen, Farben und Formen ermöglichen. Verfahren der künstlichen Intelligenz können ausserdem Zusammenhänge aufzeigen, die dem menschlichen Auge verborgen bleiben.
3. Modellbildung im Data Mining
Bei der Exploration entdeckt man Muster, Zusammenhänge sowie Korrelationen von Daten. Um festzustellen, ob die gefundenen Datenbeziehungen auch tatsächlich vorhanden und statistisch signifikant sind, werden die zugrundeliegenden Vermutungen und Hypothesen mathematisch ausgedrückt.
4. Evaluation
Nun werden die Hypothesen anhand der vorhandenen bzw auch weiterer Daten unter Einsatz der üblichen statistischen Verfahren geprüft.
5. Anwendung
Die gefundenen Muster werden dazu genutzt, um beispielsweise Prognosen zu erstellen oder Marketingstrategien zu entwickeln.
Durchführung
Eine 100% genaue Data Mining Definition gibt es nicht, da das Verfahren in den verschiedensten Bereichen angewandt wird.
Die umfangreichen vorhandenen Datenschätze lassen sich natürlich nicht von Hand auswerten. Dazu sind Werkzeuge nötig (siehe auch unter Data Mining Software). Laut Data Mining Definition geht man folgendermassen vor:
Vorbereitung
- Im ersten Schritt definiert der Anwender sowie der Data Mining Spezialist die zu beantwortende Frage. Passend dazu erfolgt die Auswahl auszuwertender Daten. Ein Interessantheitsmass muss definiert sein, das misst, welche Daten oder Zusammenhänge für die vorliegende Fragestellung in wie weit interessant sind.
- Im zweiten Schritt des Data Mining werden die Daten zusammengeführt. Diese liegen eventuell an verschiedenen Orten (Datenbanken, Listen, Dokumente) in unterschiedlichen Formaten vor. Sie werden, beispielsweise über eine ODBC-Schnittstelle, in einem eigenen Data Warehouse oder in einer Datenbank gesammelt.
- Im dritten Schritt folgt eine Datenvorverarbeitung. Dazu gehört nach Data Mining Definition insbesondere die Datenbereinigung. Manche Daten sind vielleicht doppelt (Dubletten) und werden zusammengefasst oder die Doppelten gelöscht, unplausible und widersprüchliche Daten werden gefunden und berichtigt, für fehlende Werte sollen vielleicht Schlüsselbegriffe eingetragen werden wie „na“.
- Eventuell codiert der Analyst noch die Daten, z.B. Freitext bestimmten Kategorien zugeordnet werden oder Gruppen gebildet. So könnte man beispielsweise Postleitzahlen ihren Landkreisen zuordnen oder Geburtstage jeweils einer Alterskohorte.
Auswertung und Interpretation
- Dann erst beginnt die Datenauswertung. Dabei spielt das Interessantheitsmass eine wichtige Rolle. Verfahren sind u.a. Clustering, Klassifikation, Segmentierung, Extraktion, Filtern, Aggregation (Bündelung) sowie Abhängigkeitsanalysen (z.B. Korrelationsanalysen oder Regression).
- Validierung: Der Data Mining Spezialist prüft die gefundenen Zusammenhänge an unabhängigen Daten, die nicht für deren Herleitung dienten. So erkennt man Gesetzmässigkeiten, die zufällig nur in dieser einen Stichprobe existieren, aber keine allgemeine Gültigkeit haben.
- Interpretation und Präsentation: Der Anwender deutet die gefundenen Zusammenhänge und anschliessend erfolgt dann zumeist auch die Präsentation oder Publikation.
Wo kommt Data Mining zum Einsatz?
Data Mining kann grosse Datenmengen (z.B. Big Data) effizient durchsuchen und dabei nicht nur solche Korrelationen finden, die man bereits vermutet hat, sondern auch ganz unerwartete. Damit ist es das ideale Verfahren, um Datenschätze zu heben, die Firmen im Verlauf ihrer Geschäftstätigkeit unbeabsichtigt bzw durch Webseiten-Tracking gezielt ansammeln.
Analyse von Kundendaten
Zu den regelmässig anfallenden Informationen gehören die Stamm- bzw Bewegungsdaten der Kunden. Somit kann man ermitteln, in welchem Gebieten besonders viele oder nur wenige Kunden wohnen oder welche Kundengruppen wie viel und was bestellen sowie zuverlässig die Rechnungen bezahlen. Ausserdem lässt sich auch feststellen Produkt am häufigsten gekauft wird, welche Produkte besonders häufig von einer Kundengruppe gekauft wird und so weiter. So lassen sich Kunden-Kategorien bilden und gezielt Werbemassnahmen sowie Rabatte lancieren, die nur für einzelne Marktsegmente gelten sollen.
Prozessoptimierung
Weitere interessante Daten sind solche, die bei der Produktion und Qualitätssicherung von Produkten entstehen, beispielsweise: Wie lange dauert die Herstellung eines Produkts von der Anlieferung des Materials bis zur Auslieferung an den Kunden? Welcher Arbeitsschritt dauert am längsten? Welchen Durchsatz hat welcher Schritt und wo wird die Produktivität doch durch Engpässe begrenzt? Wo entsteht am meisten Ausschuss?
Optimierung von Webseiten
Das Tracking einer Webseite erzeugt zusätzliche Informationen darüber, wie Besucher auf diese gelangt sind, was sie interessiert bzw. was nicht, auf welche Stichworte sie klicken und welche Unterseiten sie am aufmerksamsten lesen. Damit erhalten Unternehmen eine direkte sowie unverfälschte Rückmeldung zur Wirksamkeit von Werbemassnahmen und der Attraktivität von Webseiten-Inhalten.
Wissenschaftliche Studien
Obgleich Data Mining vor allem mit gewerblichen Anwendungen in Verbindung gebracht wird, können auch wissenschaftliche Studien von diesem Verfahren enorm profitieren. Mögliche Anwendungsbereiche sind die Auswertung von Strahlungen aus dem Weltall oder Daten eines Teilchenbeschleunigers, Patientendaten eines Krankenhauses bzw Herztöne aus der EKG-Aufzeichnung.
Tatsächlich bestehen unendlich viele Anwendungsmöglichkeiten, so dass jede Art von Daten strukturiert und Erkenntnisse hervorgebracht werden können.
Was macht Data Mining schwierig?
Forschungsfrage
Die erste Schwierigkeit besteht bereits darin, die Frage richtig zu stellen. Bevor man die riesigen Datenmengen zu analysieren beginnt, sollte man ungefähr wissen, wonach man sucht. Nur so kann der Analyst die richtige Analysemethode ausgewählen. Die Forschung zum Data Mining hat gerade erst begonnen, und so gibt es erst wenige Standards, die sich durchgesetzt haben.
Rechenzeit
Selbst dann wenn der Anwender die Frage klar formuliert hat, die Data Mining Definition angewendet hat und auch die Analysemethode passend gewählt hat, tritt noch das Problem auf, dass bei grossen Datenmengen zwangsläufig lange Rechenzeiten auftreten. So eine umfangreiche Auswertung kann auch Tage dauern. Viel Rechenzeit kann eingespart werden durch eine fokussierte Fragestellung und einen effizienten Auswertungsalgorithmus.
Datenqualität
Auch die Datenqualität beeinflusst stark die Gültigkeit und Qualität der gefundenen Ergebnisse. Und die Datenqualität ist oft nicht optimal: Viele Daten fehlen, sind ungenau und wurden meist sowieso für einen ganz anderen Zweck erhoben. Insbesondere muss man gut darauf achten, mit ungültigen und fehlenden Daten richtig umzugehen, z.B. bei einer Mittelwertbildung keine fehlenden Daten als Zahlenwert 0 mit in die Berechnung einzubeziehen.
Datenschutz und Data Mining
Bei der Auswertung personenbezogener Daten müssen Analysten darauf achten, aus Datenschutzgründen eine genügende Anonymisierung einzuhalten. Dabei genügt es nicht, die Namen zu löschen. Da anhand weniger persönlicher Daten wie Geburtsdatum, Geschlecht und Postleitzahl Daten wieder personenbeziehbar werden können (d.h. deanonymisiert), gehört mehr zu einer guten Anonymisierung. Am besten erstellen Sie für den optimalen Schutz ihrer Daten mit Diceware Passpharasen.
Interpretation
Auch die Interpretation der durch Data Mining gefundenen Muster, Korrelationen und Trends ist nicht trivial. Ein statistischer Zusammenhang beweist noch keinen kausalen Zusammenhang. So schätzen Experten die statistische Signifikanz von Ergebnissen zuerst ab und Trends lassen sich ebenso ohne Fachkenntnis nicht einfach in die Zukunft extrapolieren.
Unterstützung im Data Mining durch Novustat
Wir helfen Ihnen gerne bei Ihrem Projekt. Sie brauchen lediglich die Fragestellung zu formulieren, und wir übernehmen anschliessend den Rest. Alternativ können wir Sie auch gerne im Rahmen einer Beratung unterstützen, dabei können Sie Unterstützungsleistungen einzeln oder komplett buchen. Wenden Sie sich an uns, und Sie finden auf jeden Fall bei jedem Schritt kompetente Hilfe. Nutzen Sie hierzu einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.