
In diesem Beitrag stellen wir Ihnen die Anwendung unterschiedlicher Machine Learning Algorithmen vor. Solche Data Science Tools sind Beispiele für die in einem früheren Artikel vorgestellten Lernmethoden. Viele dieser Anwendungen finden sich auch im Angebot von Python Machine Learning und Azure Machine Learning. Wir zeigen weiters konkrete Beispiele mit der umfangreichen Python Machine Learning Bibliothek scikit-learn und erklären die erfolgreichsten Data Science Tools im Detail. Zu jeder Methode gibt es verschiedene Machine Learning Algorithmen und Anwendungsbereiche, die wir beispielhaft vorgestellen. Wichtig zu wissen ist es, dass einige Machine Learning Algorithmen, je nach Anwendung, zu mehreren Lernmethoden passen.
Sie möchten sich einen umfassenden Überblick über die einzelnen Lernmethoden im Rahmen künstlicher Intelligenz verschaffen sowie konkrete Machine Learning Algorithmen kennenlernen und einsetzen? Wenden sie sich hierzu an uns für eine professionelle Beratung.
Was Sie im folgenden Artikel erwartet, haben wir für Sie in der folgenden Grafik zusammengefasst. Diese soll Ihnen einen Überblick von Machine Learning Algorithmen geben und helfen, sich im Artikel zurechtzufinden.
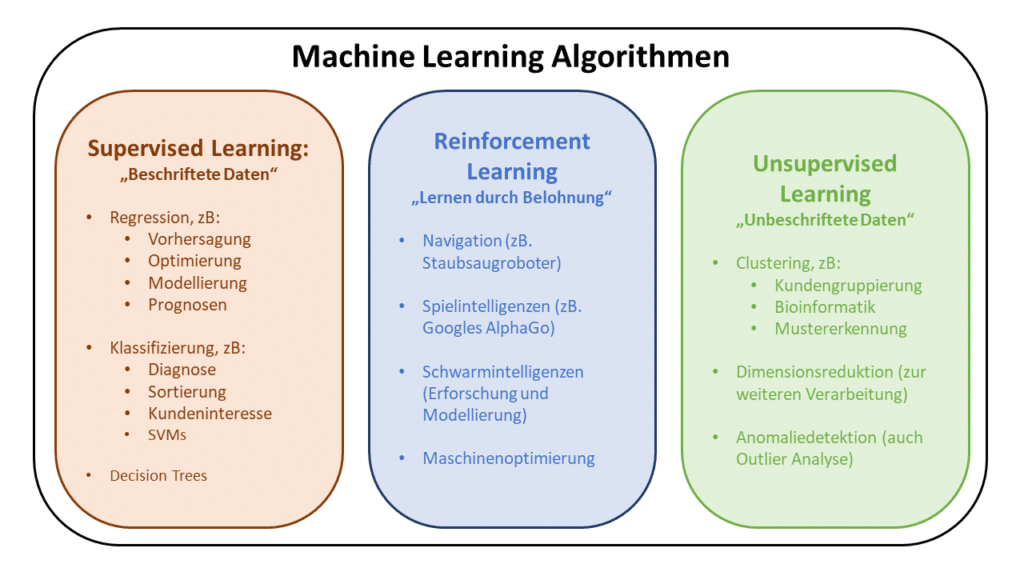
Machine Learning Algorithmen: Lernmethoden
Supervised Learning
Beim Supervised Learning wird der Computer mit Hilfe von beschrifteten („tagged“) Trainingsdaten trainiert, um dann Vorhersagen oder Bewertungen unbekannter Daten zu liefern. Derjenige, der das Programm aufsetzt, ist sich sehr darüber im Klaren, welche Ergebnisse er von den Berechnungen erwartet. Ein typisches Beispiel wäre die Vorhersage von Immobilienpreisen anhand historischer Immobiliendaten (Grösse, Alter, Zustand, etc.) und den dazugehörigen Verkaufspreisen (sogenannte „tags“).
Beim überwachten Lernen verwendet man Eingabevariablen (X) und Ausgabevariable (y) (zum Beispiel könnte X den Lernaufwand in Stunden für eine Klausur darstellen, während y die resultierende Note ist) und man verwendet einen Algorithmus, um eine Funktion f von der Eingabe zur Ausgabe zu „lernen“.
Y = f (X)
Ziel ist es, die Funktion f so gut anzunähern, dass man mit neuen Eingabedaten (X) die Ausgabevariablen (Y) für diese Daten vorhersagen kann. Verschiedene Algorithmen des überwachten Lernens unterscheiden sich vornehmlich dadurch, wie f gewählt wird.
Wir kennen sozusagen also die richtigen „Antworten“ Y auf die „Fragen“ X. Beispielsweise verfügen wir bereits über Daten von verschiedenen Schülern über Ihren Lernaufwand und der erzielten Noten. Diese Daten könnten wir als Trainingsdaten verwenden. Der Algorithmus macht dann iterativ Vorhersagen über die Trainingsdaten und wird vom Lehrer korrigiert. Das Lernen endet, wenn der Algorithmus ein akzeptables Leistungsniveau erreicht. Für unser Beispiel wäre ein akzeptables Leistungsniveau etwa, wenn der Algorithmus die erzielte Note auf Basis des Lernaufwands mit hoher Wahrscheinlichkeit vorhersagen kann.
Überwachte Lernverfahren lassen sich einteilen in Klassifikations- und Regressionsprobleme. Beispiele hierfür sind Support-Vektor-Maschinen, lineare Regression, logistische Regression, naive Bayes, Entscheidungsbäume, k-Nächster-Nachbar-Algorithmus sowie Neuronale Netze. Wenn von „künstliche Intelligenz“ gesprochen wird, ist oft eines dieser Verfahren gemeint.
Klassische Machine Learning Algorithmen für Supervised Learning sind die Lineare Regression, Decision Trees und Klassifikation. In Rahmen dieses Artikels stellen wir die spannende und äusserst praktische Anwendung eines Entscheidungsbaumes (Decision Tree) aus der Python Machine Learning Bibliothek scikit-learn vor. Im folgenden Code haben wir einen Datensatz über Wein geladen. Ausserdem benötigen wir neben scikit-learn noch die Python Bibliothek Pandas. Für das Beispiel beschränken wir uns darauf, drei Eigenschaften zu betrachten und erstellen ein Featureset „X“ daraus. Wir teilen die von 0 bis 10 bewerteten Weine in „Gute Weine“ und „Schlechte Weine“ (0 respektive 1). Anschliessend benutzen wir den DecisionTreeClassifier um die Daten zu analysieren und stellen das Ergebnis graphisch dar.
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
import pandas as pd
df = pd.read_csv("winequality-red.csv")
features = ["citric acid", "fixed acidity", "free sulfur dioxide"]
df["target"] = 0
df.loc[df.quality > 5.63, "target"] = 1
X = df[features]
y = df["target"]
clf = tree.DecisionTreeClassifier(max_depth=2)
clf = clf.fit(X, y)
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=features,
class_names=["Bad Wine","Good Wine"],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data, format='png')
graph.render()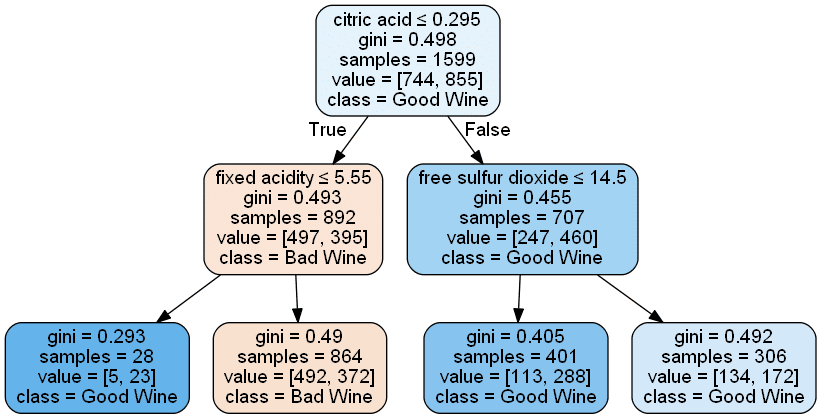
Anhand der verschiedenen Weineigenschaften lässt sich nun rasch herausfinden, ob man hier wohl einen guten oder schlechten Wein vor sich hat. Diese ML Methode eignet sich folglich hervorragend, um Prozessentscheidungen mathematisch herzuleiten und darzustellen.
Bei konkreten Fragen zur Anwendung von Machine Learning Algorithmen bzw. Python Machine Learning und Azure Machine Learning für Deep Learning in ihrem Business oder für Ihre Forschung melden Sie sich direkt und unverbindlich bei uns. Nutzen Sie dazu gerne unser Kontaktformular!
Zweites Beispiel Überwachtes Lernen: Support Vector Machine
Ein typischer Vertreter überwachter Lernverfahren sind Support Vector Machines. Bei diesem Verfahren werden Daten mit Hilfe von hochdimensionalen Trennflächen separiert. In diesem Abschnitt wird beschrieben, wie man mit Hilfe des kernlab-Pakets Support Vector Maschinen mit R implementieren kann. Wie wir anschliessend sehen werden, können wir mit Hilfe von R diese Trennflächen einfach visualisieren (solange die Daten 2-dimensional sind). Eine einfache theoretische Einführung findet sich beispielsweise hier.
1. Daten generieren und darstellen
Zunächst werden wir Daten generieren, die nicht linear trennbar sind (es gibt also keine Gerade in 2D, welche die Daten eindeutig in zwei Klassen teilt). Wir erstellen dabei einen zweidimensionalen Vektor von 120 Zeilen (x Є R120 × 2). Die Werte in der ersten Spalte (x1) stammen von einer Normalverteilung mit dem Mittelwert 1 und die Werte in der zweiten Spalte (x2) von einer Normalverteilung mit dem Mittelwert 3.
library(kernlab) # importiere kernlab
library(ggplot2) # importiere ggplot2
set.seed(6) # set.seed sorgt für Reproduzierbarkeit
x = rbind(matrix(rnorm(120), , 2), matrix(rnorm(120, mean = 3), , 2)) # x ist ein 120x2 Vektor normalverteilter Werte mit Mittelwert 1 bzw. 3
y
Zur Visualisierung der Daten verwenden wir anschliessend das Paket ggplot2.Dies ist das geläufigste Paket für eine schnelle und flexible Datenvisualisierungen mit R.
d=data.frame(x=x, y=y) # erstelle
names(d)<-c("x1", "x2", "y")
qplot(x1, x2, data = d, color = factor(y)) + geom_point(shape = 1)
+scale_colour_manual(values = c("#0000FF", "#00FF00"), labels = c("1", "-1"))
Der obige Code zeichnet die Daten auf einem 2-D-Gitter und färbt sie entsprechend ihrer Klasse y ein.
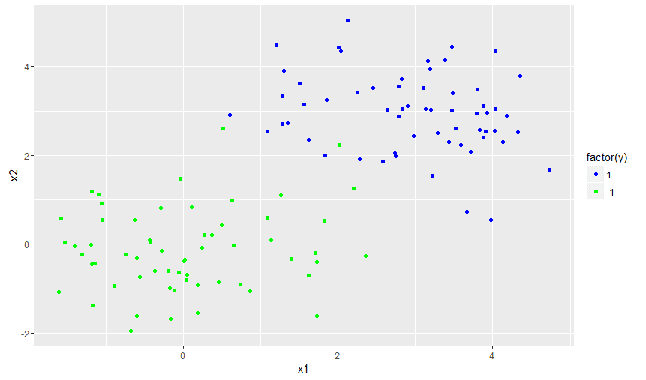
2. Daten Klassifizieren mit linearer Trennfunktion
Wie man leicht erkennen kann, gibt es keine Möglichkeit, die Datenpunkte linear zu trennen, ohne Fehler zu machen. Wenn man dies dennoch tut, führt der Algorithmus eine sogenannte „soft margin“ Klassifizierung durch, wodurch falsch kategorisierte Datenpunkte in Abhängigkeit von ihrer Entfernung von der trennenden Hyperebene bestraft werden. Somit findet der Algorithmus dennoch die beste Trennfläche.
svp = ksvm(y ~ x1 + x2, data = d, type = "C-svc", C = 1, kernel = "vanilladot")
Der folgende Code führt die Support Vector Machine durch.
svp = ksvm(y ~ x1 + x2, data = d, type = "C-svc", C = 1)
Der Parameter C steuert die erwähnte Strafe. Wir werden sehen, dass es für die Generalisierbarkeit der SVM entscheidend ist, einen guten Wert für C zu finden. In diesem Beispielcode ist C auf 1 gesetzt.
Hier können wir nun sehen, wie die Klassifizierungen aussehen:
plot(svp, data = d)
Das Diagramm der resultierenden SVM ergibt einen sogenannten Konturplot, wobei die entsprechenden Unterstützungsvektoren hervorgehoben sind (fett). Es zeigt die gleiche SVM, diesmal jedoch mit C = 100. Offensichtlich versucht die SVM nicht zu missklassifizieren und abzusuchen, da C die Strafe sehr hoch ansetzt:
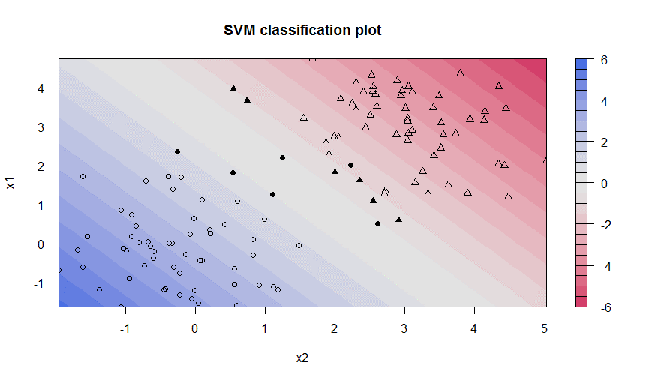
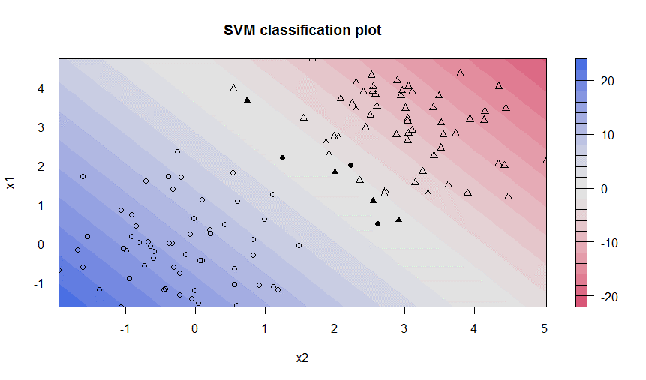
3. Daten klassifizieren mit RBF Trennfunktion
Ein weiterer wichtiger Parameter ist kernel. Dieser Parameter gibt an, wie die Trennfläche konstruiert wird. Versuchen wir, den sogenannten RBF-Kernel anzuwenden:
svp = ksvm(y ~ x1 + x2, data = d, type = "C-svc", C = 1, kernel = "rbfdot")
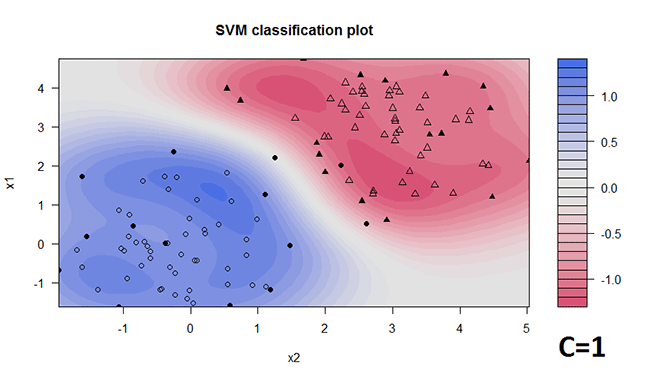
Wir sehen also, dass sowohl die Wahl von C als auch die Wahl der Trennfläche einen grossen Einfluss auf das Ergebnis des Algorithmus haben.
Unsupervised Learning
Im Gegensatz zum Supervised Learning gibt es beim Unsupervised Learning nur unbeschriftete Daten, also „untagged“ Data. Die Machine Learning Algorithmen suchen demnach eigenständig nach Lösungen für die Daten, wobei es aber keine richtigen oder falschen Antworten gibt. Der Computer beginnt anhand verschiedener Merkmale die Daten zu sortieren, nach Auffälligkeiten zu untersuchen und ihre Struktur zu verstehen. Besonders erfolgreich werden diese Algorithmen beim sogenannten Data Mining eingesetzt: Die riesigen Datenmengen, die dabei entstehen, können unmöglich von Menschenhand sortiert und analysiert werden. Daher werden unsupervised Learning Methoden angewendet, um die Daten automatisiert für die weitere Verarbeitung vorzubereiten.
Beim unüberwachten Lernen hat man nur Eingabedaten (X) und keine entsprechenden Ausgangsvariablen. Beispielsweise könnten diese Eingabedaten die Wohnorte von Menschen sein – dann wären Städte die zugehörigen Cluster. Es wäre dann etwa denkbar, dass Restaurantketten aufgrund der Ergebnisse einer Clusteranalyse eine Standortplanung durchführen könnten. Weiterhin wäre es auch denkbar, die Clusteranalyse zu nutzen, um Umfragen auszuwerten und die Antworten in entsprechende Cluster einzuteilen.
Ziel des unüberwachten Lernens ist es, die zugrunde liegende Struktur oder Verteilung in den Daten zu modellieren. Somit kann man dann anhand der Struktur mehr über die Daten erfahren.
Dies wird als unüberwachtes Lernen bezeichnet, da es im Gegensatz zum überwachten Lernen keine richtigen Antworten gibt und es keinen Lehrer gibt. Algorithmen sind ihren eigenen Entwürfen überlassen, um die interessante Struktur in den Daten zu entdecken und darzustellen.
Die Data Science Tools, die dabei Anwendung finden, sind vor allem Clustering Algorithmen wie K-Means Clustering sowie Dimensionsreduktionsalgorithmen wie beispielsweise die Principal Component Analysis und Anomaliedetektion (zB. mittels Isolation Forest). Obgleich Azure Machine Learning dafür Methoden anbietet, wollen wir nachfolgend den Algorithmus K-Means Clustering aus scikit-learn vorstellen.
Für das Beispiel nutzen wir einen Datensatz mit fiktiven Kundendaten. Wir wollen die Kunden nach Einkommen und der Höhe ihrer Ausgaben in unserem Geschäft klassifizieren, um sie anschliessend nach optimierten Kriterien mittels Werbung zu locken. Nach dem Einlesen der Daten erstellen wir das KMeans Objekt und lassen es insgesamt fünf Cluster analysieren. Das Ergebnis stellen wir dann noch mit Matplotlib dar. Wichtig: Da es sich um unsupervised Learning handelt, gibt es diesmal keinen Target y-Vektor.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
df=pd.read_csv("Mall_Customers.csv")
X=df.iloc[:,[3,4]].values
kmeans=KMeans(n_clusters=5, init="k-means++", max_iter=300, n_init=10, random_state=0)
y_kmeans=kmeans.fit_predict(X)
plt.figure(figsize = (10,10))
colors = ['red','lime','maroon','green','blue']
for i in range(5):
plt.scatter(X[y_kmeans == i,0], X[y_kmeans == i, 1], s = 90, c = colors[i])
plt.title("Clusters of clients")
plt.xlabel("Annual Incom (K$)")
plt.ylabel("Spending Score (1-100)")
plt.savefig("KMeans.png")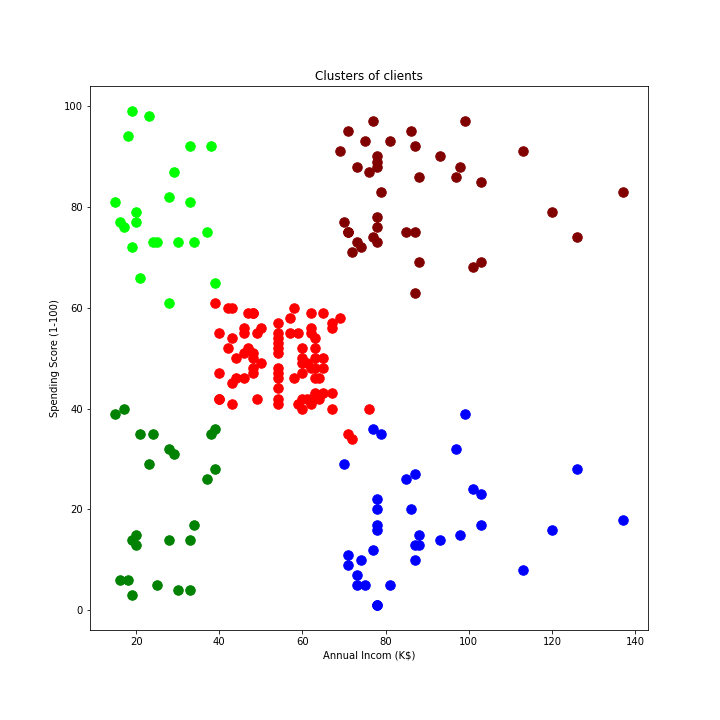
Doe Abbildung lässt mit freiem Auge die Gruppierungen erkennen, die unser Code gefunden hat. Die Gruppierungen des Codes sind farblich hervorgehoben. So lassen sich auch reale Kundendaten gruppieren und dementsprechend visualisiert darstellen.
Beispiel Unüberwachtes Lernen: k-means Clustering
K-Means-Clustering ist einer der einfachsten und beliebtesten unüberwachten Algorithmen für maschinelles Lernen (ein einfaches theoretisches Beispiel findet sich z.B. hier). Im Folgenden wird ein einfaches angewandtes Beispiel durchgespielt.
Schritt 1: Generierung von geclusterten Daten
Wir erzeugen wieder 200 zweidimensionale Datenpunkte. Diese verteilen sich dabei um die Werte (15, 5) und (5, 15) herum (mit normalverteilten Abweichungen).
c1 = cbind(rnorm(100, mean=5), rnorm(100, mean=15)) # links oben
c2 = cbind(rnorm(100, mean=15), rnorm(100, mean=5)) # rechts unten
data = rbind(c1, c2) # Binde beide Spalten aneinander (siehe unten)
plot(data)
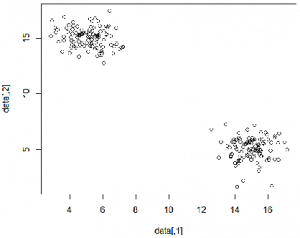
| c1 | data[,1] | data[,2] |
| 6.370958 | 16.20097 | |
| 4.435302 | 16.04475 | |
| … | … | |
| c2 | 12.99907 | 4.995379 |
| 15.33378 | 5.760242 | |
| … | … |
Schritt 2: Implementation des k-Means-Algorithmus
Für die Implementierung des k-Means-Clustering-Algorithmus existiert in R eine integrierte Funktion namens kmeans. Man muss dabei nur die zu gruppierenden Daten und die Anzahl der Cluster angeben, die wir auf 4 setzen.
cluster = kmeans(data, 4)
cluster
Das Clustering wird anschliessend von R durchgeführt. Wenn wir cluster aufrufen, erhalten wir den folgenden Output:
K-means clustering with 2 clusters of sizes 100, 100
Cluster means:
5.19192 14.997198
14.70764 4.930212
Clustering vector:
1 1 […] 2 2
Within cluster sum of squares by cluster:
258.1744 160.2776
(between_SS / total_SS = 95.8 %)
Available components:
“cluster” “centers” “totss” “withinss” “tot.withinss” “betweenss” “size” “iter” “ifault”
Der obige Output sagt Folgendes aus:
- was getan wurde (Clustering mit 2 Clustern der Grössen 100, 100)
- die Zentroide der Cluster, also ihre zentralen Punkte (das ist ziemlich nahe an dem, was wir erwarten würden – die Daten stammen von bivariaten Normalverteilungen mit Mitteln (5, 15) und (15, 5)) (cluster means)
- ein Vektor mit 200 Einträgen, der die zugewiesenen Kennzeichnungen jedes Datenpunkts beschreibt (clustering vector)
- und die Summe der Quadrate pro Cluster innerhalb des Clusters – dies ist die Summe der quadratischen Abweichungen für jeden Datenpunkt vom jeweiligen Cluster-Schwerpunkt (Within cluster sum of squares by cluster)
Schritt 3: Visualisierung der Ergebnisse
# Zeichne Daten verschiedener Farbe
plot(data, col = kk$cluster)
# Plotte die Mittelpunkte in Schwarz
points(kk$centers, pch = 16, cex = 2)
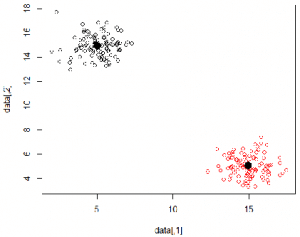
Das war ein sehr einfaches Beispiel mit zwei schön getrennten Punktclustern. In praktischen Anwendungen für künstliche Intelligenz sind die Punkte jedoch
Reinforcement Learning
Die dritte Lernmethode, die wir im Artikel zu Machine Learning und künstliche Intelligenz vorgestellt haben, ist das Reinforcement Learning. Hier lernt der Computer teilweise durch selbständiges Ausprobieren („Exploration“) und durch das Maximieren einer Belohnungsfunktion („Exploitation“). Auf dieser Grundlage erkennt er jene Strategie, die in einem bestimmten Zusammenhang am sinnvollsten ist. Hierfür werden vor allem sogenannte neuronale Netzwerke verwendet und auch Data Science Tools im Rahmen des Deep Learnings und Machine Learning Algorithmen finden hier Anwendung.
Das Reinforcement Learning wird vor allem für Bereiche genutzt, in denen die Interaktion mit der Umwelt eine tragende Rolle spielt. Selten werden hier starre Datensätze zum Trainieren verwendet, sondern entweder komplexe Simulationen oder tatsächliche Echtweltreaktionen. Ein gutes Beispiel hierfür sind etwa die Spielintelligenzen von Google und Co., die durch Spiele gegen sich selbst oder echte Menschen immer erfolgreichere Strategien entwickeln. Ein anderes wichtiges Anwendungsfeld ist das Optimieren von gigantischen und komplizierten Maschinen. Beispiele dazu sind: ein Teilchenbeschleuniger oder auch eine Produktionsstrasse in einem Industriebetrieb. Auch für Live Website Analytics kann Reinforcement Learning eingesetzt werden.
Ein vollständiges Beispiel eines neuronalen Netzwerks würde hier die Grenzen des Artikels sprengen, dazu verweisen wir Sie auf unsere Dienste im Bereich Big Data Analytics. Gerne helfen wir Ihnen auch im Rahmen einer persönlichen Data-Mining-Beratung, sich mit Machine Learning Algorithmen, Python Machine Learning und Azure Machine Learning vertraut zu machen.
Zusammenfassung
In diesem Artikel haben wir eine erste Einführung in die Grundlagen des maschinellen Lernens gegeben. Dabei haben wir den Unterschied zwischen überwachten und unüberwachten Lernen dargestellt:
- Überwachtes Lernen: Alle Daten werden gelabelled und die Algorithmen lernen, die Ausgabe aus den Eingangsdaten vorherzusagen.
- Unüberwachtes Lernen: Alle Daten sind nicht gelabelled und die Algorithmen lernen aus den Eingabedaten die inhärente Struktur.
In den letzten Jahren haben viele Techniken des Maschinellen Lernens / Künstliche Intelligenz in der Statistik an Bedeutung gewonnen. Beispiele hierfür sind Support-Vektor-Maschinen, lineare Regression, logistische Regression, naive Bayes, Entscheidungsbäume, k-Nächster-Nachbar-Algorithmus, Neuronale Netze sowie k-means Clustering. Falls Sie Hilfe bei der Auswahl und Durchführung ihres Data Mining-Projekts brauchen, helfen unsere Experten gerne mit einer persönlichen Statistik-Beratung!