
Wollen Sie Big Data für sich nutzen, so muss dieses Projekt sorgfältig geplant und durchgeführt werden. Hilfe durch Experten ist bei diesem komplexen Thema sehr oft ratsam. Denn die Zusammenführung der Daten, die Auswahl der Auswertungsmethoden und das Umsetzen dieser Auswertungen ist deutlich aufwändiger und schwieriger als bei überschaubaren Datenmengen, die Sie notfalls auch von Hand durchsehen können, um sicher zu stellen, dass eine Transformation erfolgreich war. Bei Big Data Analytics fehlt diese Möglichkeit. Lückenhafte Auswertungen und Fehlinterpretationen können jedoch teure Folgen haben.
Sollten Sie Unterstützung bei einem Big Data Projekt benötigen, helfen unsere Statistiker Ihnen gerne weiter. Nutzen Sie einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Worin besteht der Unterschied zwischen Big Data Analytics und Data Mining?
Big Data Analytics umfasst alle Verfahren zum Sammeln, Zusammenführen und Analysieren von grossen, vielfältigen Datenmengen. Dazu gehören Verfahren der Datenvisualisierung, Data Mining Methoden und Vorhersagemodelle. Somit ist es eigentlich Data Mining für Big Data, also für grosse Datenmengen schlechter Qualität.
Big Data Analytics besteht jedoch keineswegs nur darin, die üblichen Data Mining Methoden auf schnelleren Servern durchzuführen. Wegen der enormen Datenmengen wird eine Beschleunigung benötigt, die man nur durch neuartige Technologien und Machine Learning Algorithmen erreichen kann wie z.B. Parallelisierung, Cloud Computing, NoSQL-Datenbanken, Hadoop, MapReduce, Apache Spark, Pig oder Hive. Big Data Analytics muss sich also auch mit der Rechenperformanz beschäftigen und diese signifikant vervielfachen.
Last but not least ist auch der Datenschutz ein Thema speziell für Big Data Analytics. Daten, die für sich allein unkritisch sind, können durch das Zusammenführen datenschutzrechtlich relevant werden. Schlimmstenfalls wird eine Deanonymisierung möglich, d.h. anonyme Daten können auf eine bestimmte Person zurückgeführt werden. In diesem Falle ist es hilfreich sich an eine Data Mining Beratung wie Novustat oder sich durch einen Juristen unterstützen zu lassen, der sich auf Datenrecht spezialisiert hat. Wir unterstützen Sie auch bei der Sicherung Ihrer Daten, bspw. durch eine Diceware Passpharase.
Was gehört zu Big Data Analytics?
Die grossen Datenmengen sollen später für vielfältige Zwecke wieder ausgewertet werden können. Beispielsweise soll bei einer Rückrufaktion die Fragen beantwortet werden: „Zu welcher Serie gehört das beanstandete Teil? Welche anderen Teile sind eventuell auch defekt? Wo wurden sie verbaut und an wen ausgeliefert?“
Zusätzlich zu solchen gezielten Auswertungen kommen noch explorative Analysen dazu und umfassende Fragen der Qualitätssicherung und des Managements, z.B. wie viele Werkstücke pro Stunde produziert wurden, ob es Unregelmässigkeiten gab und wie diese mit anderen Faktoren korrelierten. Beispielsweise: Wurden montags weniger Teile gefertigt? Hat ein bestimmtes Team mehr Ausschuss produziert?
Zudem wird auch im Bereich Immobilien Big Data häufig analysiert.
Allgemeines zu Big Data
Mit „Big Data“ bezeichnet man grosse Datenmengen. Wie gross eine Datenmenge sein muss, um als gross zu gelten, verschiebt sich ständig mit dem sich verbessernden Stand der Technik: Terabyte (=1024 Gigabyte), Petabytes (=1024 Terabyte) oder Exabyte (=1024 Petabyte). Was gestern noch viel war, ist heute normal. Heutzutage werden in zwei Tagen 5 Exabytes an Daten erzeugt, was der Datenmenge entspricht, welche die gesamte Menschheit vor 2003 angesammelt hat. Die Datenmenge auf unserem Planeten verdoppelt sich alle anderthalb Jahre.
Big Data sind jedoch per Definition so viele und komplexe (d.h. miteinander vernetzte) Daten, dass sie mit herkömmlichen Auswertungsmethoden nicht sinnvoll analysiert werden können. Sowohl spezielle Auswertungsmethoden als auch innovative Rechenalgorithmen und Architekturen (z.B. das parallele Rechnen auf mehreren Servern) sind dazu nötig, um aus Big Data Erkenntnisse zu gewinnen und gültige Schlussfolgerungen zu ziehen. Oft sind Big Data nicht nur umfangreich, sondern auch noch lückenhaft, unstrukturiert, in verschiedensten Formaten und müssen innerhalb kurzer Zeit ausgewertet werden.
Dazu gehören Daten aus verschiedenen Quellen, die automatisch ständig grosse Datenmengen erzeugen und zusammengeführt werden, z.B. die Messdaten von Sensoren, aber auch Texte aus sozialen Netzwerken. Auch in der Biologie wird Big Data Analytics eingesetzt, um DNA zu entschlüsseln.
Big Data wird oft durch drei Eigenschaften charakterisiert, die im Englischen jeweils mit v beginnen:
- volume (Volumen / Menge),
- velocity (Geschwindigkeit der Erzeugung und Auswertung) und
- variety (Vielfalt).
Solche Daten innerhalb kurzer Zeit auswerten zu können, hilft Unternehmen dabei, frühzeitig schädliches Verhalten, aber auch positive Stimmungen zu entdecken. Dies sollte möglichst in Echtzeit geschehen, um mit Hilfe eines Real Time Reportings auf Ereignisse und Trends angemessen reagieren zu können.
Darüber hinaus gibt es heute noch zwei weitere Dimensionen, die für Nutzung von Big Data Bedeutung haben:
- Complexity: Daten verschiedener Quellen müssen verknüpft, bereinigt und übertragen werden. Dabei spielt die Gewährung der Datenintegrität eine grosse Rolle.
- Variability: Der Datenfluss oder Feed kann sehr unregelmässig sein und Schwankungen aufweisen. Dies ist insbesondere relevant, wenn Sie unstrukturierten Daten analysieren, wie bspw. Textmeldungen der Fall.
Um Big Data nutzen zu können, werden Daten aus Streaming-Daten, Daten aus sozialen Netzwerken oder öffentlich zugänglichen Datenquellen (z. B. offene Datenportale von Regierungen) verwendet. Ausserdem werden auch firmeneigene Daten herangezogen (z. B. Bestellungen, Versandtracking, …)
Big Data kommt überall dort zum Einsatz, wo sich grosse Datenmangen ohnehin ansammeln: Im Marketing, im Internet, durch Sensoren, in der Produktion, in Krankenhäusern, im Sicherheitsbereich. Die Analyse von Big Data hilft Unternehmen dabei, frühzeitig schädliches Verhalten (z.B. systematische Fehler oder Betrug), aber auch positive Stimmungen zu entdecken und für sich zu nutzen. Die Ergebnisse der Big Data Auswertungen unterstützen die Planung von Cross Selling, die Kundensegmentierung, Prognosen, Qualitätssicherung, Betrugserkennung und Decision Intelligence. Aber auch der Wissenschaft stehen durch Big Data grosse Datenmengen zur Verfügung.
Sollten Sie Unterstützung bei einem Big Data Projekt benötigen, helfen Ihnen unsere Statistiker gerne weiter. Nutzen Sie hierzu einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Unsere Stärken liegen insbesondere bei der Analyse und Prognose grosser Datenmengen – der Big Data Analytics und Big Data Predictive Analytics. Jedoch können wir zu jeder Phase des Big Data Projektes helfen.
Phasen des Big Data Projektes & wie Novustat helfen kann
- Formulieren der Fragestellung : Ohne klare Frage keine klare Antwort. Die Fragestellung muss manchmal auch iterativ gefunden werden, indem man explorativ die Daten untersucht und anschliessend die Frage konkretisiert. Hier kann Novustat Data Mining Beratung leisten.
- Auswahl und Zusammenführen der Daten aus verschiedensten Quellen: Dazu gehört auch der Export von Daten aus IT-Systemen und deren Import in einer einzigen Datenbank, die technische Umformatierung und die inhaltliche Umcodierung. Teilweise lassen können wir diese Tätigkeiten für Sie automatisieren, teilweise müssen sie händisch ausgeführt werden.
- Planung und Durchführung der Datenbereinigung: Gerade weil die Daten aus verschiedenen Quellen stammen und gar nicht für den Zweck der Auswertung erhoben wurden, lässt deren Qualität zu wünschen übrig. Darum müssen unvollständige Datensätze vervollständigt oder entfernt werden, Dubletten bereinigt oder zusammengehörige Daten gefunden und integriert werden. Kann man für die Datenbereinigung Regeln definieren, lässt sich diese Tätigkeit werkzeugunterstützt automatisieren.
- Auswahl der richtigen Analyse-Methode: Zur verfügung stehen vielfältige statistische Verfahren und methoden wie z.B. Clustering. Kompetent auszuwählen sind aber auch das passende Werkzeug, die Hardware und der Auswertungsalgorithmus (z.B. Hadoop, MapReduce), die zur Datenmenge und Auswertung passen.
- Durchführen der Auswertung: Nun wird mit Hilfe des gewählten Werkzeugs die entsprechende Methode ausgeführt und die Durchführung protokolliert. Die gestellte Frage wird beantwortet. Gegebenenfalls muss für die Auswertung ein Skript programmiert werden.
- Optimierung der Auswertungsdauer: Die Auswertung von Big Data benötigt wegen der grossen Datenmenge auch entsprechend viele Ressourcen in Form von Hardware und Rechenzeit. Gerade bei Auswertungen, die regelmässig wiederholt ausgeführt werden sollen, lohnt eine Optimierung durch die Verbesserung des Algorithmus.
- Validierung der gefundenen Ergebnisse anhand weiterer Daten: Der Vorteil der grossen Datenmengen besteht darin, dass man die Daten zu zwei verschiedenen Zwecken verwenden kann: Den einen Teil für die Auswertung und den zweiten Teil für die Überprüfung, ob auch diese Daten zu denselben Schlussfolgerungen führen.
- Interpretation der Ergebnisse : Die Ergebnisse der Auswertung beantworten die anfangs gestellte Frage. Sie müssen dann noch auf ihre statistische Signifikanz analysiert werden. Damit kann die Zuverlässigkeit der Antwort quantifiziert werden. Zur Interpretation gehört auch das Formulieren von Schlussfolgerungen, wozu Branchenwissen nötig ist.
- Zielgruppenspezifische Darstellung der Ergebnisse: Die Ergebnisse des Projektes ssiessen dann in einen Abschlussbericht ein oder werden als Präsentation vorgestellt. Auch eine vollständige Dokumentation aller durchgeführten Auswertungen, Original-Daten und Ergebnisse ist für spätere Big Data Projekte nützlich. Meist sind mehrere verschiedene Darstellungen der Ergebnisse für verschiedene Zielgruppen nötig. Wir helfen Ihnen bei der grafischen und textuellen Darstellung, vollständig oder zusammenfassend.
- Beratung bei Datenschutzthemen : Werden im Big Data Projekt personenbezogene Daten verarbeitet, ist ein Datenschutzkonzept nötig. Dazu gehören auch Überlegungen zu und die Umsetzung von Massnahmen zur Anonymisierung von personenbezogenen Daten.
Sie können auch modular einzelne der Dienstleistungen beauftragen, je nach ihrem konkreten Bedarf. Wir überprüfen gerne auch bereits durchgeführte Big Data Projekte auf ihre Qualität und helfen sie zu verbessern.
Was ist schwierig an Big Data?
Herausfordernd ist beim Umgang mit Big Data nicht nur der reine Umfang der Daten. Grosse Datenmengen verlangen natürlich effizientere Auswertungsalgorithmen und performantere Hardware und Software als klassische statistische Auswertungen. Beispielsweise wird es nötig, parallel auf mehreren Servern zu rechnen, um in einer vernünftigen Zeit zu Ergebnissen zu gelangen.
Zusätzliche Herausforderungen bestehen auch darin, dass diese grossen Datenmengen üblicherweise aus verschiedenen Quellen stammen und nicht für den vorliegenden Zweck erhoben wurden. Sie müssen also aus verschiedenen Orten, Datenbanken und Formaten in einer einzigen Datenbank integriert werden. Dazu werden sie auch umformatiert und umcodiert. Oft sind die Daten unvollständig, und es muss geklärt werden, wie man mit diesen Datenlücken umgeht: Welche Datensätze werden wegen Unvollständigkeit gelöscht? Welche Datenlücken werden wie gestopft? Auch die Datenaufbereitung verlangt umfangreiche Überlegungen und muss nachvollziehbar und qualitativ hochwertig erfolgen.
Gleichzeitig steht man meist unter Zeitdruck, um möglichst bald verbindliche Big Data Analysen vorzulegen, auf deren Grundlage sinnvolle geschäftliche oder wissenschaftliche Entscheidungen getroffen werden können. Gerade wenn Produktionsfehler oder Betrugsfälle durch Auswertungen von Big Data entdeckt werden sollen, sollte die Auswertung möglichst in Echtzeit geschehen, um auf Ereignisse und Trends schnellstmöglich reagieren zu können. Spezielle Big Data Analytics Methoden sind nötig, um die gewünschte Geschwindigkeit zu erreichen. Will man aus den vorhandenen Daten Prognosen für die Zukunft erstellen, spricht man auch von Big Data Predictive Analytics.
Werden personenbezogene oder personenbeziehbare Daten verarbeitet, dann müssen die Regeln des Datenschutzes eingehalten werden. Selbst Daten, die für sich allein unkritisch sind, können durch das Zusammenführen datenschutzrechtlich relevant werden.
Was benötigt man für die Verarbeitung von Big Data?
- Eine klare Fragestellung: Klare, nützliche Antworten erhält nur, wer mit einer klar definierten Frage startet. (Es dürfen auch mehrere sein.)
- Die richtigen Daten: Aus den richtigen Datenquellen müssen die richtigen Daten extrahiert und in das passende Format gebracht werden.
- Geeignete Data Mining Analytics Methoden oder Big Data Predictive Analytics Methoden für die Datenanalyse
- Umfangreiche, performante Hardware, welche die Big Data Analyse durchführt.
- Genau die richtige Darstellung der Ergebnisse.
- Ein Datenschutzkonzept.
Novustat unterstützt Sie bei Ihrem Big Data Projekt
Wollen Sie Big Data für sich nutzen, so muss dieses Projekt sorgfältig geplant und durchgeführt werden. Fehler in der Datenbereitstellung, Bereinigung oder Auswertung können teuer werden. Die Unterstützung durch Experten tut bei so einem komplexen Projekt not. Eventuell haben Sie auch gar nicht alle notwendigen Ressourcen, z.B. die Rechenleistung.
So können unsere Experten Sie unterstützen:
- Beratung bei der Planung Ihres Big Data Projektes, z.B. Formulieren der Frage, Auswahl der Daten und Datenquellen
- Erstellen des Datenschutzkonzeptes
- Zusammenführen der Daten
- Planung und Durchführung der Datenbereinigung
- Durchführen der Auswertungen
- Interpretation und Darstellung der Ergebnisse
- Individuelle Coachings und Schulungen, wie bspw. SPSS Schulungen
Woher stammen grosse Datenmengen?
Heutzutage liegen in Unternehmen alle und im privaten Bereich immer mehr Daten digital vor, alle Geschäftsprozesse werden elektronisch unterstützt und dokumentiert. Wird beispielsweise jedes Werkstück mittels RFID-Chip Schritt für Schritt auf seinem Produktionsprozess durch die Werkhalle verfolgt, dann entstehen hier bereits riesige Mengen an Daten. Später will man genau wissen, in welcher Maschine welche Schraube verbaut und an welchen Kunden ausgeliefert wurde, wann ausgetauscht und wie entsorgt. Hohe Qualitätsansprüche und rechtliche Dokumentationspflichten erzeugen riesige Mengen an Daten.
Big Data entstehen nicht nur in der Produktion, es gibt auch Big Data im Gesundheitswesen in der Verwaltung, Sicherheit (Überwachung), Finanzwesen, Energiewirtschaft und Verkehr, Internet (z.B. soziale Medien) und Mobilfunk. Je mehr „intelligente“ Geräte wie Smart-Metering-Systeme, Assistenz-Systeme und Überwachungsgeräte zum Einsatz kommen, umso weitere Bereiche des Lebens werden digitalisiert und somit auswertbar.
Big Data nutzen: Grosse Datenmengen alleine reichen nicht aus
Das Sammeln grosser, qualitativ hochwertiger Datenmengen ist ein wesentlicher Aspekt bei Big Data Lösungen. Meist werden mit dem Begriff Big Data viele verschiedene Aspekte moderner digitaler Technologien aus dem Bereich Data Mining zusammengefasst.
Es geht nicht nur darum, wie viele hochwertige Daten vorliegen. Ebenso wichtig ist es, was man daraus macht und wie man Big Data nutzen kann. Die Analyse und Generierung von relevanten Informationen wird als Big Data Analytics bezeichnet.
Big Data Analytics ermöglicht es, Zeit einzusparen, Kosten zu senken, objektive Unterstützung bei Entscheidungen sowie bei der Optimierung von Prozessabläufen zu erhalten und vieles mehr.
Die Nutzung von Big Data impliziert aber auch eine neue Art und Weise der Unternehmensführung. Denn die aus Big Data Analytics gewonnenen Erkenntnisse werden anschliessend im Management integriert und angewendet.
Big Data nutzen – eine interdisziplinäre Chance
Für die systematische Nutzung von Big Data ist ein interdisziplinärer Ansatz notwendig. Nur wenn die technologischen Voraussetzungen vorhanden sind, wie beispielsweise Speicherkapazität, Arbeiten in Echtzeit, Cloudlösungen, Software etc. kann man Big Data Analytics sinnvoll anwenden. Datenmanager bzw. Informatiker müssen die Datenintegrität und die Datenqualität sicherstellen und auf einem hohen Level halten, um valide Aussagen zu ermöglichen. Sind diese Voraussetzungen erfüllt, können Analysten oder Statistiker Big Data Analytics anwenden, um die Fragestellungen des Managements zu bearbeiten und Algorithmen zu generieren. Die Ergebnisse stellen Analysten dann wiederum dem Unternehmensmanagement für Entscheidungsfindungen zur Verfügung. Gleichzeitig hat das Management die Verantwortung für weiterführende Big Data Lösungen und muss die Mittel und Kapazitäten für die Umsetzung von Big Data Lösungen zur Verfügung stellen. Ausserdem ist die Einbindung der Datenschutzbeauftragten unabdingbar, unter Umständen auch von Juristen. Diese sind für die Einhaltung der Datenschutzbestimmungen und Regelung der gesetzlichen und vertraglichen Bestimmungen zuständig.
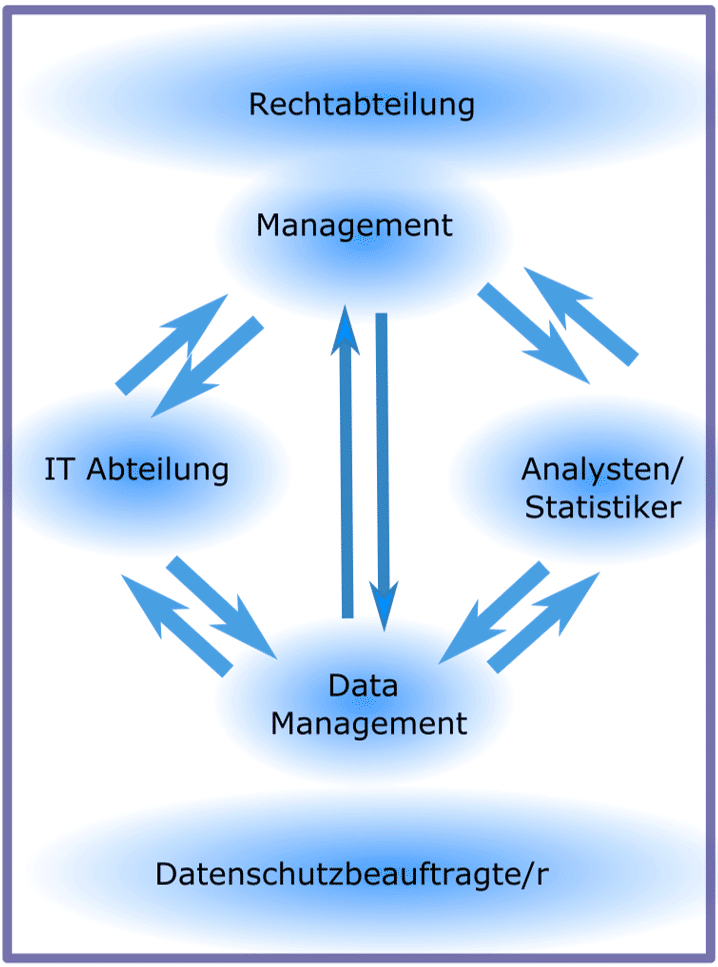
Die Nutzung von Big Data
Die dargestellten Zusammenhänge sind ideal, um routinemässig und effizient Big Data nutzen zu können. Entscheidet sich ein Unternehmen, Entscheidungsprozesse gestützt von Big Data Analytics einzuführen und so Wettbewerbsvorteile zu erhalten, so müssen diese Strukturen meist erst geschaffen werden. Gegebenfalls müssen Fachleute ausgebildet oder eingestellt werden. Ein riesiger finanzieller und zeitlicher Aufwand, der viele mittelständische und kleinere Unternehmen davon abhält, Big Data nutzen zu können.
Für eine erfolgreiche Nutzung von Big Data geben unsere Experten folgende Ratschläge:
Aller Dinge Anfang ist klein
Zu Beginn der Nutzung von Big Data ist es hilfreich, wenige abgegrenzte Fragestellungen zu beantworten. Die Daten müssen zunächst noch nicht mehrere Terabyte umfassen. Für valide Aussagen sind qualitativ hochwertige Daten wichtiger als unzählige minderwertige Datensätze.
So kann ein Unternehmen mit Online-Präsenz zunächst ermitteln, welche Produkte von Kunden angesehen werden, die keine Produkte kaufen. Aufgrund dieser Informationen können speziell für diese Kunden in der Folge zugeschnittene Werbemassnahmen durchgeführt werden.
Aufgrund solch abgegrenzter, überschaubarer Big Data Lösungen kann das Management sehen, was die Daten leisten können. Der Gewinn für das Unternehmen kann mit einem kleinen, abgegrenzten Ansatz im Anschluss angegeben werden.
Zeitintervalle bei der Nutzung von Big Data festlegen
Wenn Sie Big Data nutzen wollen, kann zu Beginn erfahrungsgemäss auf eine Echtzeitauswertung verzichtet werden. Die Prozesse, um alle Daten jederzeit zu erfassen, zu verarbeiten und zu analysieren und die Ergebnisse jeweils auf dem aktuellen Stand zu haben, sind sehr kosten- und zeitintensiv. Eine regelmässige Datenerfassung z. B. monatlich, im Quartal oder halbjährlich reicht erfahrungsgemäss in vielen Fällen aus. So sind für Vorhersagen von Verkaufszahlen oft die Vorjahreswerte sowie die Zahlen aus den Vormonaten aussagekräftiger als Verkaufszahlen der letzten Stunden.
Einbeziehung externer Dienstleister für Big Data Analytics
Big Data Analysten sind gefragte Experten. Für die Datenaufbereitung sowie Big Data Analytics ist es anfänglich hilfreich, externe Dienstleister zu beauftragen. Die Experten stellen eine vollständige, reliable und zufriedenstellende Beantwortung aller Fragen sicher. Dabei gilt es zu beachten, dass Consulting Anbieter neben den Auswertungen auch Coaching und eine Erklärung der durchgeführten Analysen liefern. Nur dadurch kann ein Wissenstransfer stattfinden. Die Unterstützung und das Vertrauen in die Nutzung von Big Data bei allen Beteiligten kann man durch externe Dienstleister stark fördern.
Einbindung von Big Data Analytics in Entscheidungsprozesse
Um Big Data nutzen zu können, muss auf Management Ebene ein spezifischer Ansatz gefunden werden, Ergebnisse aus Big Data Analytics in die Entscheidungsfindung einzubinden. Bei einem Widerstand und zu grosser Skepsis, Erkenntnisse aus der Nutzung von Big Data in die Managementprozesse einzubinden, kann man daraus keinen Unternehmensgewinn erzielen. Andererseits liefert die Nutzung von Big Data natürlich auch nicht automatisiert Lösungen aller Fragestellungen. Big Data ist als Entscheidungshilfe konzipiert, die verantwortungsvolle Umsetzung liegt beim Management.
Big Data Predictive Analytics
Big Data Predictive Analytics bedeutet, aus den Big Data von gestern und heute Vorhersagen für morgen und übermorgen zu treffen. Während es bereits schwierig ist, aus Big Data gültige Schlussfolgerungen zu ziehen, kommen bei der Vorhersage weitere Herausforderungen hinzu. Big Data Predictive Analytics kann zuverlässig nur durch Experten durchgeführt werden.
Sollten Sie Unterstützung bei einem Big Data Projekt benötigen, helfen unsere Statistiker Ihnen gerne weiter. Nutzen Sie einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Prädiktive Analyse: Vorteile für Unternehmen
Predictive Analytics Methoden verschaffen Unternehmen klare Konkurrenzvorteile, die man nicht unterschätzen sollte. Prädiktive Analyse kann einem Unternehmen ermöglichen die Lage des Marktes in jedem Moment genauer als die Konkurrenten abschätzen und dadurch in jeder Situation optimaler zu handeln, bspw. durch Predictive Analytics im Ecommerce. Auch eine prädikative Kundenanalyse wird häufig eingesetzt.
Predictive Analytics Methoden sind systematisch und basieren auf Daten sowie verschiedenen mathematischen und statistischen Methoden. Prädiktive Analyse bietet somit eine Möglichkeit, fundierte Vorhersagen zu treffen, die auf einer soliden Datengrundlage beruhen.
Novustat ist Experte für Big Data Predictive Analytics
Die Methoden der Big Data Predictive Analytics verlangen wegen der Mehrdimensionalität der Fragestellungen tief gehendes mathematisches und statistisches Know-How. Novustats Experten besitzen dieses Spezialwissen und können es in Ihr Projekt einbringen. Durch kompetente Data Mining Beratung gelingt eine möglichst zuverlässige Prognose der Zukunft.
Wie funktioniert Predictive Analytics?
Prädiktive Analyse besteht aus drei Schritten:
1. Datenerhebung
Es gibt zwei Gruppen der Daten für Prädiktive Analyse: interne und externe Daten.
Interne Daten sind die Unternehmensdaten: Umsatz, Kosten usw. Der Vorteil dieser Daten besteht darin, dass sie leicht zugänglich sind. Gleichzeitig beziehen interne Daten sich aber wirklich nur auf ein konkretes Unternehmen. Wenn man ausschliesslich interne Daten für die Erstellung des Modells nutzt, sind die Vorhersagen des Modells wegen geringer Datenmenge ungenau. Deswegen ergänzt man die internen Daten durch externe Daten.
Zu den externen Daten gehört eine grosse Menge von verschiedenen Kennzahlen wie z.B. Wetter, Aktienkurse, politische Entscheidungen, Marktprognosen und vielen mehr. Heutzutage gibt es viele offene Datenbänke mit grossen Datensätze zu den verschiedensten Themen. Die externen Daten müssen dabei aber sorgfältig auswählt werden: Nur die Daten, die die Vorhersagekraft des Modells erhöhen, sollten für die Analyse und Modellierung verwendet werden.
2. Datenanalyse
Der zweite Schritt der prädiktiven Analyse ist Data Mining: die Anwendung von computergestützten statistischen und mathematischen Methoden, um so viele verborgene Zusammenhänge und Informationen wie möglich in den Daten zu entdecken. Dazu gehören z.B. verschiedene Klassifizierung und Modellierungsmethoden, Clustering oder sequential Association.
3. Predictive Modelling
In diesem Schritt ist es wichtig, die Fragestellung für die Prädiktive Analyse genau zu definieren: Was genau möchte man prognostizieren? Was ist das Vorhersagefenster? Basierend darauf wird ein passendes statistisches Modell ausgewählt.
Es gibt zwei grosse Gruppen der predictive Analytics Methoden: Supervised und unsupervised Learning. Beide basieren auf statistischer Theorie und sind mit den Themen predictive AI, Big Data und Deep Learning for Business eng verknüpft.
Welche Methoden braucht man für Predictive Analytics im Zusammenhang mit Big Data?
Big Data Predictive Analytics geht über die Erkennung von Mustern in grossen Datenmengen hinaus und bezieht auch statistische Berechnungen, Spieltheorie, Optimierungsrechnung, statistische Modellierung, maschinelles Lernen (künstliche Intelligenz) und Simulationen mit ein. Für die Erzeugung eines Datenmodells, das Predictive Modeling, stehen diverse Verfahren der Künstlichen Intelligenz (KI) in Kombination mit Methoden des Maschinellen Lernens (ML) und der Statistik als Software zur Verfügung. Alles, was dabei hilft, effizient die Zukunft vorherzusagen.
Big Data Predictive Analytics vereint hierzu Data Mining Methoden für die Zukunftsprognose mit den performanten Verfahren der Big Data Analytics wie NoSQL-Datenbanken, Hadoop, MapReduce und Apache Spark.
Besonders weit verbreit sind dabei die Technologien Hadoop und Apache Spark.
Hadoop vs. Spark: Wo liegt der Unterschied?
Hadoop und Spark sind zwei Technolgien die gut geeignet sind um unterschiedliche Bereiche von Big Data abdecken. Hadoop ist historisch als Datenspeicher gewachsen. Spark eignet sich dahingegen besonders zur Processing Engine, Die folgende Tabelle listet die wichtigsten Unterschiede zwischen Hadoop und Spark auf:
| Hadoop MapReduce: Daten speichern  | Spark: Daten verarbeiten | |
| Geschwindigkeit | Wurde für sehr grosse Datenmengen entwickelt, ist schneller als traditionelle Systeme | Ca. 100x schneller als MapReduce im Arbeitsspeicher und ca. 10x schneller auf dem Festplattenspeicher |
| Programmiersprache | Geschrieben in Java | Geschrieben in Scala |
| Funktionalität | Batch Processing von Daten | Batch, real-time, interaktive, iterative und grafische Verarbeitung von Daten |
| Speicherung der Daten | Streng Datei-basiert | In-Memory Speicherung von Daten |
| Resource Management | YARN | Standalone Cluster |
| Datenaufbereitung Modell | Aufgabe wird als Ganzes zuerst bewertet und kann dadurch optimiert werden – weiterer Geschwindigkeitsgewinn | |
| Besondere Vorteile | Einfache Handhabung durch high-level Programmiersprachen | |
| Spark ist nicht dazu gedacht, Hadoop zu ersetzen, sondern dessen Funktionalitäten zu erweitern. Spark ist kein direktes Äquivalent für die relationale Datenbank-Systeme und unterstützt die ACID Eigenschaften nicht. Der Hauptvorteil von Spark ist seine Geschwindigkeit, die auf bestehenden System wie Hadoop sehr hohe Performance-Vorteile bringt. |
Was macht Predictive Analytics mit Big Data schwierig?
Zunächst stellt die schiere Menge von Big Data hohe Ansprüche an die Hardware, Auswertungsmethoden und -algorithmen. Aber auch die Datenqualität ist selten optimal. Hinzu kommen die Schwierigkeiten, die Prognosen in die Zukunft immer mit sich bringen. Geht man davon aus, dass in der Zukunft dieselben Randbedingungen gelten wie bisher, dann kann man durch Extrapolation, Fourier- und Regressionsanalysen voraussehen, dass vergangene Trends sich in der Zukunft fortsetzen werden. Solche Trends können lineare Trends sein oder auch zyklische. In unserer dynamischen Welt verändern sich jedoch die Bedingungen ständig. Darum muss Big Data Predictive Analytics sowohl diese Veränderungen vorhersehen als auch deren Einfluss auf das zu beobachtende Phänomen. Daher erfordert der Einsatz von Predictive Analytics unbedingt die Expertise von erfahrenen Fachleuten.
Wozu dient Big Data Predictive Analytics?
Mit Hilfe von Big Data Predictive Analytics kann eine Firma oder Organisation zukünftige Chancen und Risiken frühzeitig im Voraus erkennen. Beispielsweise aus den Daten der Kundenkarten-Datenbank kann man vorhersehen, welche Preisaktionen zukünftig bei den Kunden am beliebtesten sein werden, aus Gesundheitsdaten lassen sich für einzelne Patienten ihre Gesundheitsrisiken voraus berechnen.
Predictive Analytics mit Big Data können in allen Branchen sinnvoll eingesetzt werden: Marktforschung, Gesundheitswesen, Vorhersage von Epidemien, Finanzdienstleistungen, Sicherheit und Missbrauchsentdeckung, Verkehrs- und Städteplanung, System- und Produktionssteuerung, Klimaforschung, sogar für das Auffinden aufstrebender Sportler.
Predictive Analytics findet Einsatz in vielen Geschäftsbereichen
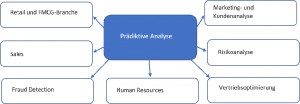
Mindestens 50 % allen Unternehmen haben predictive AI (Artificial Intelligence/Künstliche Intelligenz) in zumindest einer Unternehmensfunktion implementiert. Diese Zahl wird in den kommenden Jahren vermutlich noch weiter wachsen.
Prädiktive Analyse stellt ein neuen und komplexen, aber sehr mächtigen Data Science Bereich dar. Dank predictive AI kann man fundierte Geschäftsentscheidungen treffen. Man kann sich besser auf unvorhergesehene Situationen vorbereiten und die Effizienz des gesamten Unternehmens steigern.