
R Data Mining eignet sich besonders gut für die Auswertung grosser Datenmengen. Es wird also Data Mining mit dem Statistikprogramm R durchführt. Dabei geht es hier um folgende Fragen:
- Wie lädt man Daten in R?
- Wie verschafft man sich in R einen Überblick über umfangreiche Daten?
- Wie führt man in R Daten zusammen?
- Wie unterstützt R die Datenvorverarbeitung, z.B. Datenbereinigung oder Big Data Analytics?
- Wie skalieren die Statistik-Funktionen beim R Data Mining?
Sollten Sie Unterstützung benötigen, im Rahmen von Data Mining R zu nutzen, helfen unsere Statistiker Ihnen gerne weiter. Nutzen Sie einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Wie lädt man Daten in R?
Die Daten für das R Data Mining können aus allen möglichen Quellen stammen: aus Dateien auf Ihrem Computer, aus einer Datenbank, aber auch aus dem Internet. Um die Originaldaten zu dokumentieren, macht es Sinn, immer zuerst die Datei aus dem Internet auf Ihren Rechner herunterzuladen und erst anschliessend in das Programm R einzulesen, z.B. in eine Matrix oder ein Data Frame.
Das Herunterladen erfolgt mit der Funktion download.file(url=“http://adresse.com/datei.txt“, destfile = „datei.txt“) für eine Datei oder mit con Die Daten werden dann aus der Datei in eine Variable in R eingelesen. Dies erfolgt je nach Format der Datei mit einer anderen Funktion.
- Text-Datei: x
- Gezippte gz-Datei: dat
- Tabelle: read.table(„datei.txt“)
- Html-Datei: htmlTreeParse(“http://…”, useInternal = TRUE) oder readLines()
- CSV-Datei: read.csv(„datei.csv“)
- Xlsx-Datei: read.xlsx(“name.xlsx”, sheetIndex=1, colIndex= , rowIndex=) (Hierzu ist das xlsx-Package nötig.)
- XML-Datei: xmlTreeParse(“http://adresse.com/datei.xml”, useInternal= TRUE) (mit XML-Package)
Diese Funktionen erlauben eine Vielzahl an Argumenten, die Sie sich am besten im entsprechenden Hilfetext ansehen, z.B. mit ?read.table. So kann z.B. mit sep = „,“ das Komma als Trennzeichen zwischen Daten festgelegt werden, die Datentypen der Spalten mit colClasses definiert, die Anzahl und die Bezeichnungen der Zeilen mit nrows und row.names, das Zeichen, das fehlende Werte signalisiert, mit na.strings spezifiziert und mit skip die Anzahl der am Dateianfang zu überlesenden Zeilen angegeben.
Beim Zugriff auf eine Datenbank sind Grundkenntnisse in SQL nötig. Zunächst stellen Sie eine Verbindung her mit der Datenbank. Wenn Sie fertig sind, müssen Sie unbedingt die Verbindung wieder trennen mit dbDisconnect(datenbank).
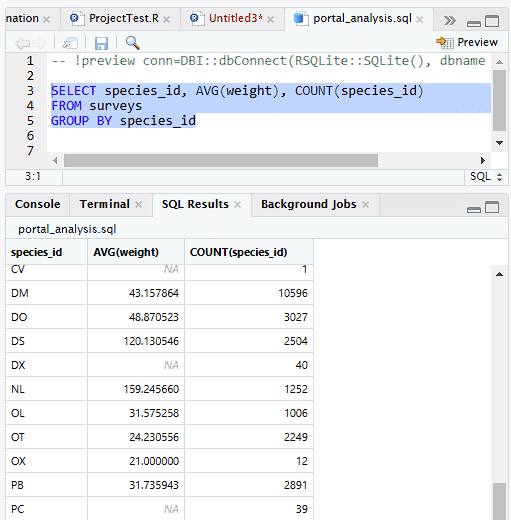
Während Sie Zugriff auf die Datenbank haben, können Sie SQL-Befehle auf ihr ausführen und damit Daten auslesen, aber auch ändern: dbGetQuery(datenbank, “select count(*) from table”) oder dbSendQuery(datenbank, “select * from … where variable between 1 and 3”).
Sie können sich die Tabellen anzeigen lassen mit Tabellen <- dbListTables(datenbank) sowie Tabellen lesen dbReadTable(datenbank, “Tabellenname”). Mehr Informationen zur Verwendung von SQL in R finden Sie hier.
Wie verschafft man sich beim R Data Mining einen Überblick über umfangreiche Daten?
Liegen Ihre Daten als Tabelle oder Data Frame vor, dann können Sie sich mit den folgenden Befehlen einen schnellen Überblick verschaffen, wenn Sie in R Data Mining betreiben möchten:
- Der Befehl dim(t) zeigt Ihnen die Anzahl der Zeilen und Spalten einer Tabelle t an, length(x) die Länge eines Vektors x. Mit diesen Befehlen können Sie schnell überprüfen, ob beim Einlesen oder Verarbeiten von Daten Zeilen oder Spalten verloren gegangen sind.
- Die Befehle head(t) und str(t) zeigen die Spaltenüberschriften und die ersten fünf Zeilen der Tabelle t an, so dass Sie eine Datenvorschau erhalten. Names(t) zeigt nur die Spaltenüberschriften.
- Summary(t) berechnet für jede Spalte einer Tabelle t den Minimum- und den Maximum-Wert, den Mittelwert, den Median und das erste und dritte Quartil.
- Table(x) ermittelt die Häufigkeiten der Werte eines Vektors.
Auch ein schneller Plot (grafische Darstellung) sorgt für einen Überblick über die Daten. Die beiden R-Standardfunktion sind plot(data, type) und text(150,600,”Beispieltext”). Die Eingabe für plot() sind die Daten als Data Frame, wobei x und y als separate Argumente eingegeben werden, jeweils als Vektor, der aus Zahlen besteht. Type kann sein: type= „p“(Punkte), „l“ (Linien), „b“(beides) oder „h“(Histogramm). Farben können angegeben werden mit dem Argument col=”red”.
Zusätzliche Grafik-Funktionen bieten die Packages graphics und ggplot2.
Im Rahmen von Data Mining R richtig nutzen: Wie führt man Daten zusammen?
Daten, die als zwei Matrizen x und y vorliegen, führt man in einer einzigen zusammen mit dem Befehl rbind(x,y) oder cbind(x,y). Dabei steht das r für rows (Zeilen) und c für columns (Spalten). Die Funktion rbind verwendet man, wenn die beiden Tabellen dieselben Spalten haben, und ihre Zeilen jeweils untereinander geschrieben werden sollen, und cbind, wenn die beiden Tabellen zwar dieselben Zeilen haben (die z.B. zum selben Datensatz aus einer Messung gehörend), aber die Spalten zusammengefügt werden sollen. Beispielsweise so: Es habe zwei Messrunden gegeben, in denen jeweils bei 5 verschiedenen Temperaturen 3 verschiedene physikalische Grössen a, b und c gemessen wurden. Die verwendeten Temperaturen stehen in einer Matrix temp, die Daten der beiden Messrunden in den Matrizen data1 und data2. Temp sieht z.B. so aus:
| Temperatur | |
| 1 | -10 |
| 2 | 0 |
| 3 | 10 |
| 4 | 20 |
| 5 | 30 |
Data1 und Data2 haben diese Form:
| a | b | c | |
| 1 | 14.1 | 8.9 | 17.0 |
| 2 | 15.6 | 9.0 | 16.4 |
| 3 | 17.8 | 9.1 | 16.0 |
| 4 | 19.1 | 9.2 | 14.8 |
| 5 | 20.5 | 9.3 | 10.6 |
Nun würde man z.B. mit data1 <- cbind(temp,data1) und data2 <- cbind(temp, data2) zunächst die Spalte „Temperatur“ beiden Matrizen hinzufügen:
| Temperatur | a | b | c | |
| 1 | -10 | 14.1 | 8.9 | 17.0 |
| 2 | 0 | 15.6 | 9.0 | 16.4 |
| 3 | 10 | 17.8 | 9.1 | 16.0 |
| 4 | 20 | 19.1 | 9.2 | 14.8 |
| 5 | 30 | 20.5 | 9.3 | 10.6 |
Und dann hängt man die beiden Matrizen mit rbind(data1, data2) hintereinander:
| Temperatur | a | b | c | |
| 1 | -10 | 14.1 | 8.9 | 17.0 |
| 2 | 0 | 15.6 | 9.0 | 16.4 |
| 3 | 10 | 17.8 | 9.1 | 16.0 |
| 4 | 20 | 19.1 | 9.2 | 14.8 |
| 5 | 30 | 20.5 | 9.3 | 10.6 |
| 6 | -10 | 14.0 | 8.9 | 16.5 |
| 7 | 0 | 15.6 | 9.0 | 15.8 |
| 8 | 10 | 17.6 | 9.1 | 15.2 |
| 9 | 20 | 19.0 | 9.2 | 14.1 |
| 10 | 30 | 20.3 | 9.3 | 9.7 |
Dasselbe funktioniert natürlich auch mit deutlich grösseren Datenmengen. Um sicher zu sein, dass die Zusammenführung funktioniert hat, sollten Sie nach jedem Schritt mit der dim()-Funktion die Dimensionen der Matrizen prüfen. Data1 und data2 hatten zunächst noch die Dimensionen 5×3, nach Hinzufügen der Temperatur-Spalte 5×4, und die kombinierte Matrix hatte 10×4. Mit der head()-Funktion können Sie die ersten fünf Zeilen der Tabelle kontrollieren, mit der View()-Funktion des dplyr-Packages öffnet sich die Matrix in einem separaten Fenster und kann dort gescrollt werden. Gar nicht ratsam ist, gerade bei umfangreichen Datenmengen, die Anzeige der Matrix in der Konsole mit dem Befehl data1. Die Anzeige ist unübersichtlich und schneidet bei grossen Datenmengen einen Teil einfach ab.
Eine weitere Möglichkeit, Datensätze zusammenzuführen, stellt die Funktion merge dar. Sie kann Daten auch dann zusammenführen, wenn nicht Zeile n der einen Tabelle zum selben Datensatz gehört wie Zeile n der anderen Tabelle. Verwendet wird für das Mergen ein Schlüsselwert oder auch zwei, anhand dessen zusammen gehörige Datensätze erkannt werden:
gesamt <- merge(data1, data2, by=”ID”)
gesamt <- merge(data1, data2, by=c(“ID”,”Country”))
Bei grossen Datenmengen verwendet man gerne statt der Data Frames auch Data Tables. Diese sind ähnlich, doch ihre Verarbeitung läuft schneller. Nötig ist hierzu das Package data.table.
Zu den Lesefunktionen gehören natürlich auch die entsprechenden Schreibfunktionen wie write.table(), mit denen die in R erzeugten Daten wieder in eine Datei geschrieben und so gesichert werden können.
Wie unterstützt R die Datenvorverarbeitung, z.B. Datenbereinigung?
Eine wichtige Voraussetzung für das R Data Mining sind saubere Daten. Zumeist liegen sie als Tabelle vor. Bei der Datenbereinigung wird sichergestellt, dass jede Zeile einem Datensatz entspricht, jede Spalte einer Variablen. Auch der Umgang mit fehlenden Daten muss geklärt sein. Für die späteren Auswertungen sind vermutlich nicht alle Daten nötig, sondern nur ein Ausschnitt davon, z.B. nur bestimmte Zeilen (Datensätze) oder bestimmte Spalten (Variablen) der Tabelle.
Colnames(m) <- c(„var1“,“var2“,…) ist eine Funktion, mit der Sie Ihrer Datentabelle Spalten-Überschriften zuweisen können. Zeilen und Spalten der Tabelle kann man anhand ihrer Nummer extrahieren, z.B. die n-te Zeile mit Tabelle[n,] und die m-te Spalte mit Tabelle[,m]. Tragen die Spalten Namen, können Sie eine Spalte auch mit Tabelle$name auswählen. Auch komplexere Verfahren für die Auswahl von Daten sind möglich, z.B. die Definition von Bedingungen wie diese: m[m$var1 %in% c(“a”,”b”),] wählt aus einer Matrix m diejenigen Zeilen aus, für die var1 entweder gleich „a“ oder gleich „b“ ist. Mit m[,var1==15] wählen Sie diejenigen Spalten aus, für die var1 gleich 15 ist. Und m[which(m$var2 > 8),] extrahiert alle diejenigen Zeilen, für die var2 grösser als 8 ist. Which(m$var2 > 8) ist ein Vektor mit den entsprechenden Zeilennummern.
Gerade für die Datenvorverarbeitung gibt es einige Packages, die das R Data Mining um zusätzliche Funktionen erweitern. Dazu gehören u.a. die Packages plyr, dplyr und tidyr. Weitere R-Funktionen finden Sie auch hier.
Wie skalieren die Statistik-Funktionen beim Data Mining mit R?
Nachdem diese Schritte ausgeführt sind, folgen die statistischen Auswertungen. Die Statistik-Funktionen von R sind hier beschrieben. An dieser Stelle interessiert uns die Skalierbarkeit dieser Funktionen für das R Data Mining.
Grundsätzlich kann R auch grosse Datenmengen verarbeiten. Allerdings geht es beim Data Mining um wirklich sehr, sehr grosse Datenmengen, so dass immer irgendwann die Rechenzeiten zu lang werden. Doch da R durch Pakete erweiterbar ist, gibt es auch hierfür Lösungen. So hat beispielsweise HP ein Open Source Paket namens HP Distributed R entwickelt, mit dem ein R-Programm auf mehreren Servern parallel laufen kann. So sind auch Auswertungen möglich, die einen einzigen Computer überfordern würden. Weitere Pakete für die effiziente Bearbeitung von Big Data entwickelt das Programming with Big Data in R (pbdR) Projekt. R wird als Programmiersprache auch von Apache SparkTM unterstützt, einem Open Source Framework für das Verarbeiten von Big Data im Rechnercluster.