
Sobald man sich mit Datentransformation in R befasst, kommt man schnell auf das viel genutzte Paket dplyr. Dieses Paket stellt viele praktische Funktionen zur Verfügung, die das Filtern, Gruppieren und viele weitere Operationen zum Kinderspiel werden lassen.
Sollten Sie weiterführende Unterstützung bezüglich Datentransformation mit dplyr benötigen oder allgemeine Fragen zum Paket haben, wenden Sie sich gerne und unverbindlich an unsere Experten in der Statistik Beratung.
In diesem Artikel zeigen wir die wichtigsten und meistgenutzten Funktionen auf. Ausserdem erklären wir die Magie des genialen Pipe Operator. Die Ausführungen ergänzen wir für ein besseres Verständnis mit etlichen Praxisbeispielen.
Am Ende erklären wir noch, wie gut dplyr in R mit ggplot2 zusammenarbeitet.

Was genau ist dplyr R und wie wird es verwendet?
Wie schon erwähnt, ist dplyr ein Satz an Funktionen, mit denen Daten in Data Frames transformiert bzw. manipuliert werden können. Der Begriff ‘Manipulieren’ beschreibt hier jede Art von Operation mit den Zielen
- Daten miteinander zu verknüpfen oder zu gruppieren,
- Daten zu löschen, hinzuzufügen, zu ändern oder
- Daten nach bestimmten Kriterien zu durchsuchen.
Das übergeordnete Ziel von Datentransformation bzw. –manipulation ist immer die Extraktion von Information. Dplyr wird als Teil der Tidyverse-Umgebung geliefert, kann aber auch auf sich allein gestellt im Skript verwendet werden. Dies geschieht wie üblich über den Befehl
>>install.packages(„tidyverse“)<< oder
>>install.packages(„dplyr“)<< und anschliessend wird das Paket geladen mit
>>library(dplyr)<<.
Für dieses dplyr-Tutorial verwenden wir ausserdem das Datenset mpg. Dieser Datensatz enthält eine Mischung aus kategorischen und numerischen Variablen. Er lässt sich unkompliziert laden mit dem Befehl
>>data(„mpg“)<< und anschliessend betrachten mit
>>head(mpg)<<.
Eine äusserst praktische Ressource hierbei ist das dplyr cheat-sheet. Es gibt auch zu jedem anderen Paket im tidyverse ein solches cheat-sheet.
Gut lesbare Operationen mit dem Pipe Operator
Unter dem Pipe Operator versteht man das Zeichen ‘%>%‘. Es lässt sich auch mit STRG + SHIFT + M einfügen. Der Operator erlaubt das Überführen einer dplyr-Operation in eine anderweitige Operation. Wir können uns das in etwas so vorstellen, wie ein Rohr (pipe), das zwischen zwei Stufen einer Raffinerie den Rohstoff weiterleitet.
Der Pipe Operator in R macht dadurch Codes besser und einfacher lesbar. Möchten wir beispielsweise einen Datensatz erst gruppieren und anschliessend zusammenfassen, erleichtert uns der Operator dies und wir brauchen nicht umständlich die Zwischenstufen einzeln abspeichern.
Konkret lautet der Befehl:
```{r}
mpg_2 <- group_by(data = mpg, manufacturer)
mpg_2 <- summarise(data = mpg_2, cyl = mean(cyl))
mpg_2
```
Mithilfe des Pipe Operator gelingt es zudem, die einzelnen Operationen einfach ineinander über zu führen. Wir ersparen uns damit das Erstellen von Zwischenergebnissen. Weiters müssen wir nicht jedes Mal den Datensatz für die Funktion separat angeben:
```{r}
mpg %>% group_by(manufacturer) %>%
summarise(cyl = mean(cyl))
```
Der daraus resultierende Data Frame ist identisch, nur der Weg unterscheidet sich deutlich im Hinblick auf Lesbarkeit, Bequemlichkeit und Fehleranfälligkeit. Je mehr die Funktionen verschachtelt sind, desto stärker und sichtbarer werden wir den Vorteil demnach erkennen.
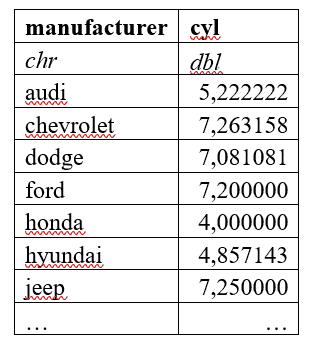
Details dazu lassen sich auch im dplyr cheat cheet finden.
Fokus Zeilen: dplyr Filter, slice und arrange
Die erste Gruppe an Funktionen, namentlich dplyr Filter, beschreibt Operationen, mit denen Zeilen im Data Frame bearbeitet werden. So lassen sich mit dem dplyr Filter alle Zeilen heraussuchen, die eine bestimmte Voraussetzung erfüllen.
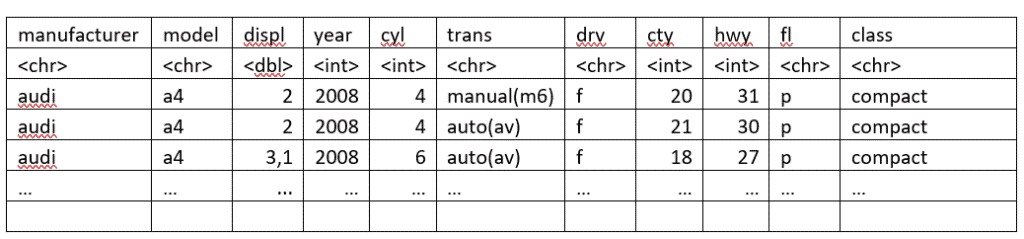
Beispielsweise können wir damit alle Autos filtern, die von Audi nach 2001 hergestellt wurden. Dafür ist es nötig, im filter() Befehl nur die Bedingungen für die jeweiligen Spalten zu definieren:
```{r}
mpg %>% filter(manufacturer=="audi", year > 2001)
```
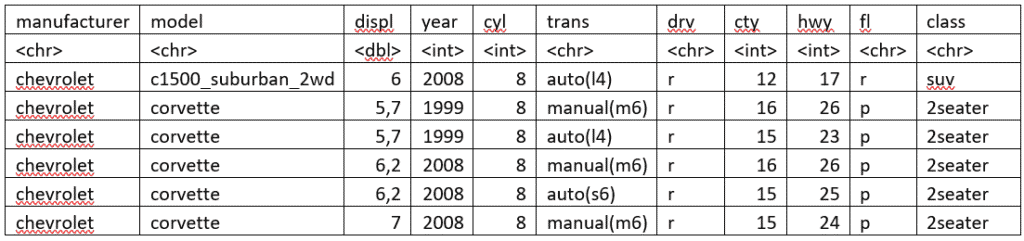
Mit dem Befehl slice() können wir die Zeilen nach ihrem Index auswählen. Wir wollen uns beispielsweise die Zeilen 23 bis 28 anschauen, dann formulieren wir wir folgt:
```{r}
mpg %>% slice(23:28)
```
Als Ergebnis erhalten wir folgenden Output:
Eine weitere wichtige Funktion ist auch das Sortieren der Reihen eines Data Frames nach bestimmten Kriterien. Dafür können wir die Funktion arrange() verwenden. Bei mehr als einer Variable wird automatisch in absteigender Hierarchie sortiert.
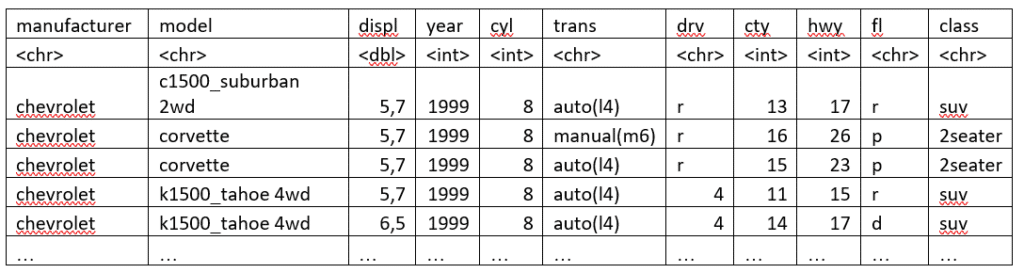
Alternativ können wir mit dem Wrapper desc() die Variable auch absteigend sortieren. Werfen wir zum Beispiel einen Blick auf die ältesten Autos mit den meisten Zylindern:
```{r}
mpg %>% arrange(year, desc(cyl))
```
Fokus Spalten: dplyr select, rename und mutate
Oben haben wir Operationen von dplyr R gezeigt, die auf Zeilen angewendet werden. Nun wollen wir drei Funktionen betrachten, die auf Spalten ausgeführt werden.
Die wichtigste Funktion ist dplyr select, mit der man Spalten nach Name auswählen kann:
```{r}
mpg %>% select(c(manufacturer, year))
```

Natürlich lassen sich auch Spalten umbenennen mit der sogenannten rename() Funktion. Im folgenden Beispiel benutzen wir den Pipe Operator, um erst zwei Spalten auszuwählen und anschliessend eine davon umzubenennen:
```{r}
mpg %>% select(c(manufacturer, year)) %>% rename(Hersteller=manufacturer)
```

Eine der wichtigsten Funktionen ist schliesslich die mutate() Funktion. Hier lässt sich eine neue Spalte dem Data Frame hinzufügen, die wir durch eine Vorschrift erstellen.
Konkret könnten wir beispielsweise aus dem Spritverbrauch (hier: Meilen pro Galone Sprit) innerstädtisch (cty) und auf Freilandstrassen (hwy) einen kombinierten Kraftstoffverbrauch errechnen:
```{r}
mpg %>% mutate(kombiniert=1/3*cty + 2/3*hwy) %>% select(c(model, year, cty, hwy, kombiniert))
```
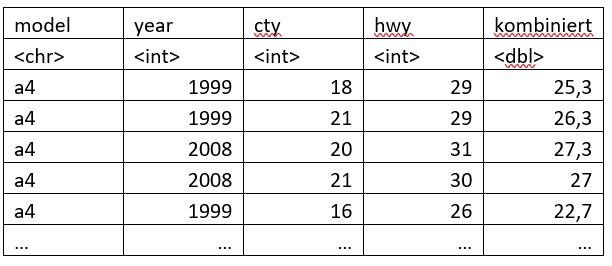
Bei allen Funktionen ist es wichtig zu erwähnen, dass wir hier nur Basisauswertungen durchführen. Dplyr R ist ein unglaublich umfassendes Programm. Die Tiefe lässt sich erahnen, wenn wir im dplyr cheat sheet schmökern.
So lassen sich dplyr select zum Beispiel auch alle Spalten auswählen, die auf „r“ enden, der Befehl dazu lautet: select(ends_with(„r“)).
Dplyr und ggplot2: Herausragende Zusammenarbeit
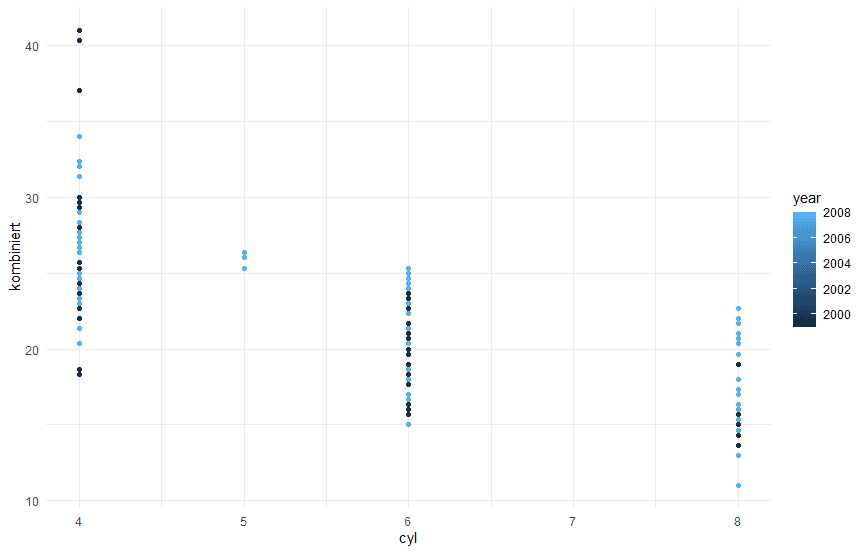
Abschliessend noch ein praktisches Beispiel, das zeigt, wie hervorragend ggplot2 und dplyr im tidyverse zusammenarbeiten. Zunächst erstellen wir wieder eine Variable für den kombinierten Spritverbrauch.
Dann wählen wir mit dplyr select die Spalten Jahr, Zylinderanzahl und Spritverbrauch aus und überführen sie in eine ggplot Funktion. Wir plotten Verbrauch zur Anzahl der Zylinder und geben mit einem Color Grading noch das Jahr aus, in dem das jeweilige Auto zugelassen (year) wurde:
```{r}
mpg %>% mutate(kombiniert=1/3*cty + 2/3*hwy) %>% select(c(year, cyl, kombiniert)) %>%
ggplot(aes(x=cyl, y=kombiniert, color=year)) + geom_point() + theme_minimal()
```
Fazit
Dplyr ist eines der zentralen und wichtigsten Tools, wenn man produktiv mit R arbeiten möchte. Es gibt ein Paket an Funktionen an die Hand, mit der wir einfach und effektiv Datentransformationen durchführen können.
Die Zahl an Möglichkeiten scheint nahezu endlos. Gegebenenfalls hilft hier immer ein Blick in das dplyr cheat sheet, das wir unten verlinkt haben! Ob Neuling oder dplyr R Experte, dieses Paket bietet allen Wissensstufen relevante Informationen.
Sollten Sie noch Hilfe oder Unterstützung benötigen, so zögern Sie nicht, sich bei uns für eine Beratung zu melden. Wir helfen Ihnen gerne weiter, nutzen Sie unverbindlich unser schriftliches Anfrageformular.
Weiterführende Links
- Paket dplyr
- dplyr cheat sheet.
- Daten in Data Frames transformieren
- Wickham H, François R, Henry L, Müller K (2022). dplyr: A Grammar of Data Manipulation.
- Tidyverse
- Pipe Operator