
Daten fallen nahezu beiläufig im Alltag an: Ob im Supermarkt an der Kasse der Inhalt des Warenkorbs gescannt wird, im Internet Suchanfragen abgespeichert werden oder das Navi den Weg mittels GPS findet. Überall um uns herum werden Daten erhoben und anschliessend ausgewertet. Die Generierung von Wissen durch Data Mining Tools ist allerdings oft ein Buch mit sieben Siegeln. Ein gängiges Vorurteil lautet dabei in etwa so: Hoch spezialisierte Nerds extrahieren die intimsten Geheimnisse aus den Daten mit sündhaft teuren Data Mining Tools. Zumindest das Vorurteil mit der teuren Data Mining Software können wir aber aus dem Weg räumen: In unserem Rapidminer Tutorial stellen wir Ihnen eine kostenfreie Data Mining Software. Das Klischee der hochspezialisierten und komplexen Data Mining Methoden können wir allerdings nicht ausräumen. Die Methoden können komplex sein, müssen aber nicht unverständlich bleiben. Unsere Data Mining Spezialisten stehen ihnen jedoch jederzeit mit Tat und Rat zur Seite.
Dieser Artikel beantwortet folgende Fragen
- Was ist Rapidminer?
- Welche ersten Schritte sind für die Analyse notwendig?
- Wie bilde ich einen Entscheidungsbaum mit Rapidminer?
- Wie interpretiere ich das Ergebnis?
Das Rapidminer Tutorial: Herr Geldig und seine Daten – die Vorgeschichte
Herr Geldig führt ein (fiktives) Unternehmen, mit dem er im Internet elektrische Geräte, Spiele, Filme und Bücher verkauft. Der Unternehmer möchte seine Verkäufe durch Data Mining Tools optimieren. Dabei denkt er z.B. an Verbesserungen im Customer Relationship Management (CRM). CRM bezeichnet die Beziehung zwischen einem Unternehmer und seinem Kunden. Diese Beziehung sollte optimalerweise effizient und effektiv für beide Seiten organisiert werden. Die Beziehung zum Kunden kann man beispielsweise durch folgende Methoden optimieren:
- Bestimmten Kunden ausgewählte Waren konkret anbieten
- Kunden identifizieren und mit Gutscheinen zu erneuten Käufen animieren
- Kunden identifizieren, die retournieren
- Mangelnder Zahlungsmoral bei Kunden vor Tätigung eines Einkaufs erkennen
- Umsatzstarke Kunden näher charakterisieren
- Aktionspakete (Warenkörbe) so geeignet zusammenstellen, dass diese die Kunden besonders ansprechen
- Themenschwerpunkte, die im Fokus der Suche der Kunden stehen, weiter ausbauen
All diese Fragestellungen gehören zu den Methoden des Data Minings.
Herr Geldig ist besonders daran interessiert, durch Data Mining Tools Kunden zu erkennen, die keine weiteren Käufe mehr bei ihm tätigen wollen. Diese Aufgabenstellung fällt in den Bereich der Klassifikation.
Für die Klassifikation in der Data Mining Software wurde aus den Datenbeständen eine repräsentative Stichprobe von 500 Kunden ausgewählt. (Nebenbei: Üblicherweise untersucht man in Data Mining Tools Millionen von Datensätzen in realen Big Data Projekten. Für unser Rapidminer Tutorial beschränken wir uns aber auf 500 Kunden.). Aus den so vorliegenden Merkmalen Alter und Geschlecht des Kunden, den Saldo ihrer Bestellung, die Zahlungsmethode, die Anzahl der bestellten Waren, Newsletter Abonnement (ja/nein), die Warengruppen der Bestellung sollen die relevanten Variablen für die Vorhersage des Zielmerkmals zukünftiger Kunde (ja/nein) selektiert werden. Die Entscheidungsregeln werden durch einen Entscheidungsbaum (decision tree) gewonnen.
Was ist Rapidminer?
Rapidminer ist eine Open Source Data Mining Software und wurde 2001 unter dem Namen YALE (Yet Another Learning Environment) an der Universität Dortmund entwickelt. Mittels einer graphischen Benutzeroberfläche kann man mit dieser Data Mining Software Daten einlesen, bearbeiten, transformieren und mit einer Vielzahl von Prozessen auswerten. Die Ergebnisse kann man anschliessend in einem Ausgabefenster dargestellen. Auswertungen kann man aspeicheren und später weiterverarbeiten. Weiterhin steht eine Vielzahl graphischer Darstellungsmöglichkeiten zur Verfügung.
Nähere Informationen zur Data Mining Software finden Sie auf den Seiten des Programms.
Im Folgenden zeigen wir in unserem Rapidminer Tutorial Schritt für Schritt, wie man den Entscheidungsbaum für Herrn Geldig mit Rapidminer erstellen und interpretieren kann.
Rapidminer Tutorial: Entscheidungsbaum Schritt für Schritt
1. Daten einlesen
Der erste Schritt besteht darin, die Daten in das Repository von Rapidminer einzulesen. Mögliche Einleseformate sind z.B. Excel oder CSV. Alternativ kann man auch Daten aus einer Datenbank abfragen und importieren.
Um den Datenimport für Herrn Geldig durchzuführen, wählen wir File – Import Data und geben dann den Speicherort der einzulesende Datei an. Im nächsten Schritt wird der Datenbereich angegeben, sowie die Zeile mit den Variablennamen definiert. Durch Bestätigen mit der Next Taste gelangt man in ein weiteres Menü, in dem man die Variableneigenschaften definieren kann. Wichtig ist dabei v.a. die korrekte Festlegung des Skalenniveaus. Zur Auswahl stehen polynomial (kategoriell, viele Auspägungen), binomial (kategoriell, 2 Ausprägungen), integer (ganze Zahlen), real (stetige Ausprägungen), date_time, date und time.

Das Datumsformat sowie das Zeitformat muss für ein korrektes Einlesen ggf. näher spezifiziert werden. Durch Anklicken des Zahnrades kann man die automatische Zuweisung für jede einzelne Variable veränderen.
Wenn dieser Schritt abgeschlossen ist, gelangt man durch Drücken der Next-Taste zur Abspeicherung des Rapidminer Datensatzes im Repository.
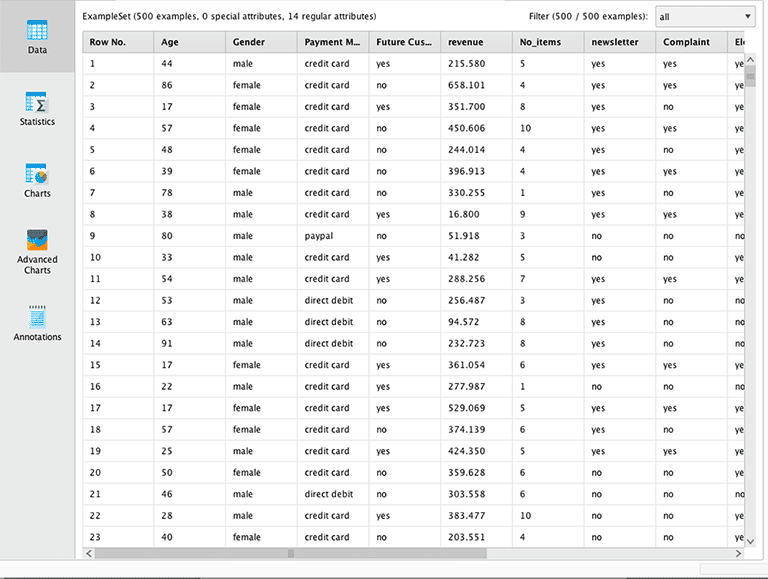
Der Datensatz von Herrn Geldig hat 14 Variablen mit folgenden Skalen (Types in Rapidminer)
| Variable | Anmerkung | Type |
| Age | Alter in ganzen Jahren | integer |
| Gender | Geschlecht (male/female) | binomial |
| Payment Method | Zahlungsmethode (credit card, paypal, direct debit) | polynomial |
| Future Customer | Zukünftiger Kunde (yes/no) | binomial |
| Revenue | Netto Einnahmen aus Warenkauf in € | real |
| No_items | Anzahl der gekauften Artikel | polynomial |
| Newsletter | Abonnement (yes/no) | binomial |
| Complaint | Rücksendung (yes/no) | binomial |
| Electronic | Elektogerät gekauft (yes/no) | binomial |
| Book | Elektogerät gekauft (yes/no) | binomial |
| Games | Buch gekauft (yes/no) | binomial |
| CDs | CD gekauft (yes/no) | binomial |
| DVDs | DVD gekauft (yes/no) | binomial |
| Others | Sonstige Artikel gekauft (yes/no) | binomial |
2. Daten aufbereiten – die Voraussetzung für saubere Ergebnisse
Im zweiten Schritt werden die Daten in der Data Mining Software aufbereitet. Dabei werden Ausreisser, Einträge denen keine Kategorie zugewiesen ist, unplausible Einträge, etc. identifiziert und ggf. entfernt. Mit beschreibenden (deskriptiven) Methoden verschafft man sich hierzu einen ersten Überblick über die Daten.
Der Menüpunkt Statistics
Um diese Schritte mit Rapidminer durchzuführen öffnet man zuerst den Datensatz aus dem Repository durch doppelklicken. Darauf öffnet sich die Datenblattansicht im Results Fenste. Im Menü Statistics können dann statistische Kenngrössen für die einzelnen Variablen abgerufen werden.
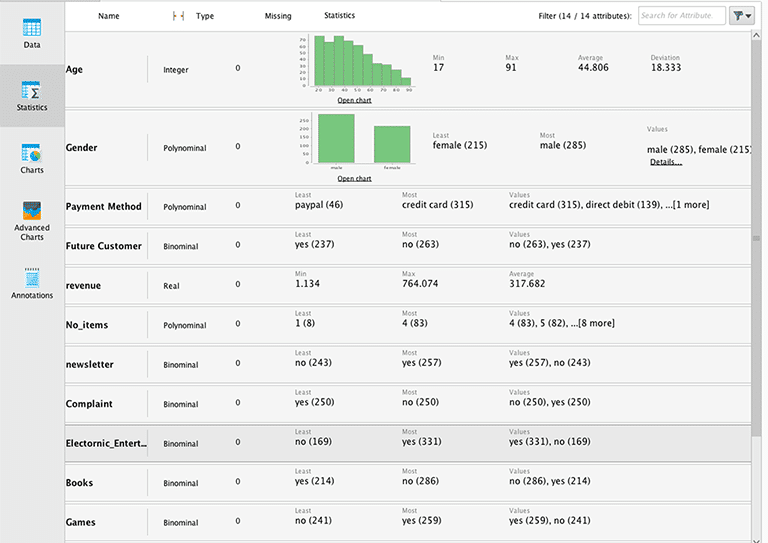
Die Variablen sind untereinander aufgelistet, gefolgt von Angaben zum Typ und der Anzahl der fehlenden Werte. In den folgenden Spalten werden dann je nach Skalenniveau relevante Kenngrössen angegeben: Minimum, Maximum, arithmetisches Mittel und Standardabweichung bei stetigen Merkmalen (Integer oder Real), eine Häufigkeitsauszählung bei kategoriellen Merkmalen. Klickt man auf den Pfeil vor dem Variablennamen, so vergrössert sich das Ausgabefeld und ein Histogramm zur Darstellung der Häufigkeitsverteilung wird angezeigt. Anhand dieser Zusammenstellung ist es möglich, Ausreisser zu identifizieren, den Wertebereich der Variablen zu überprüfen oder mittels der Häufigkeitsverteilung bzw. der Häufigkeitsauszählung schwach besetzte Kategorien zu erkennen.
Der Menüpunkt Charts
Im Menüpunkt Charts kann man in Rapidminer die Daten graphisch darstellen und bivariate Zusammenhänge z.B. anhand eines Streudiagramms veranschaulichen.
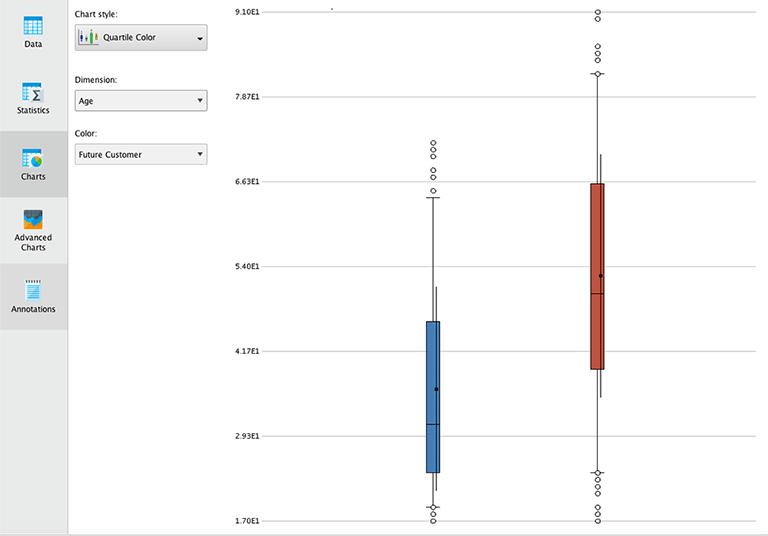
In unserem Rapidminer Tutorial vergleichen wir zuerst die Altersverteilung für Future Customer (yes/no) mit Boxplots. In diesem Diagramm wird bereits sichtbar, dass Futur Customer (blau) etwa 10 Jahre jünger sind als Kunden, die in Zukunft keine Einkäufe mehr tätigen wollen (rot).
Über den Punkt Advanced Charts kann man in Rapidminer auch komplexere Diagramme mit mehreren Dimensionen erstellen. Für einen ersten Überblick reichen aber in der Regel die Standarddiagramme, wie sie unter Charts zu finden sind.
Zusammenfassend sind mit dem zweiten Schritt folgende Erkenntnisse für Herrn Geldigs Daten verbunden:
- Im vorliegenden Datensatz sind keine auffälligen oder unplausiblen Werte zu finden.
- Die Variablen haben keine fehlenden Werte.
- Erste Zusammenhänge können anhand von Graphiken explorativ dargestellt werden.
Die Daten sind nun bereit für den nächsten Schritt.
3. Entscheidungsbaum – die eigentliche Analyse
In diesem Abschnitt im Rapidminer Tutorial werden wir eines der Data Mining Tools anwenden. Die Entscheidungsregeln sollen Herrn Geldig helfen, zukünftige Kunden zu erkennen.
Dazu definieren wir im Reiter Design zunächst einen Prozess. Ein Prozess wiederum besteht aus verschiedenen Operatoren, die auf Daten oder Ergebnisse angewendet werden.
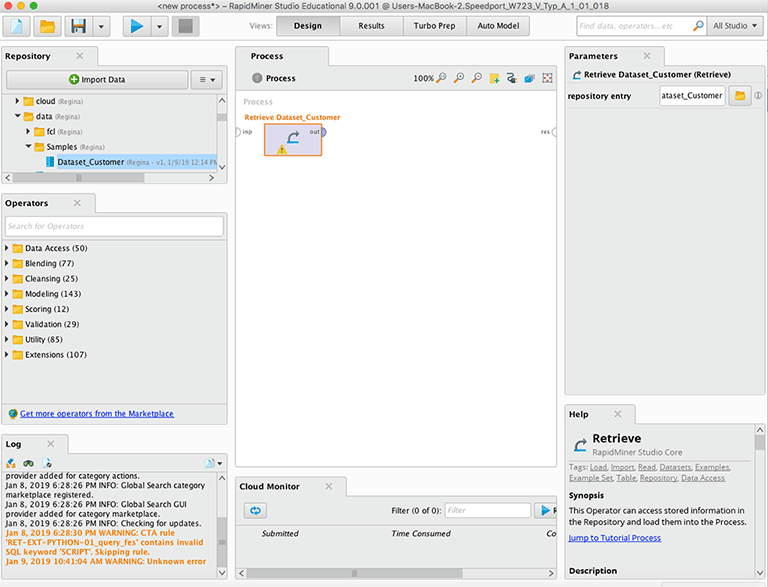
I – Retrieve Operator
Der erste Operator eines Prozesses ist der Retrieve Operator, der den Arbeitsdatensatz aus dem Repository holt. Die Operatoren können im Feld Operators ausgewählt werden. Anschliessend zieht man den Operator mit drag & drop ins Prozessfenster. Bei Anklicken eines Prozesses erscheint im Help Fenster eine kurze Beschreibung sowie ein Erläuterung zu den Einstellungen und Parametern, die zu dem Operator gehören.
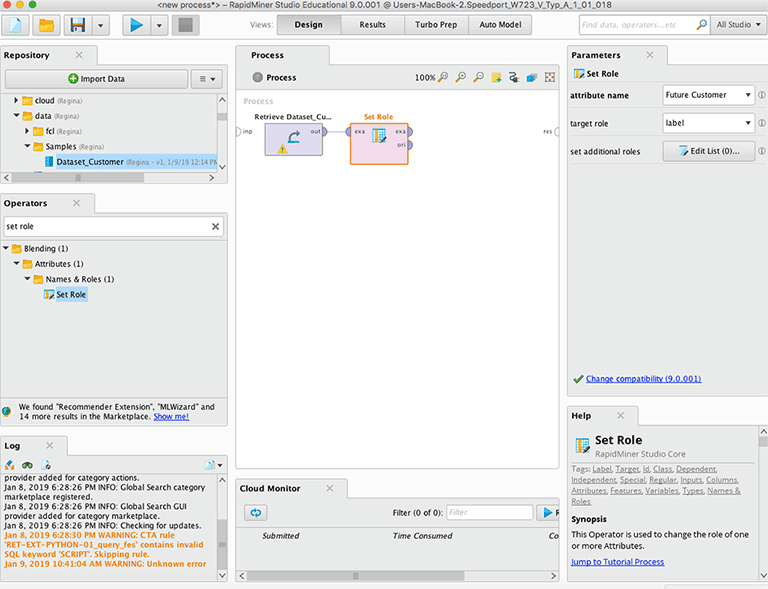
II – Set Role Operator
Der nächste Operator weist den Variablen des Datensatzes ihre Rolle für die weiteren Analysen zu. Rapidminer unterscheidet zwischen Identifikatoren (id), Zielvariable (label), Einflussvariable (prediction) und weiteren Einflussvariablen (regular). Alle Variablen, die nicht näher spezifiziert werden bekommen systemintern die Rolle regular zugewiesen.
Für den vorliegenden Datensatz ist es deshalb wichtig, Futur customer als Label zu definieren. Dazu wählt man aus dem Fenster Operators den Operator Set Role aus und zieht diesen in das Feld Process. Anschliessend werden die beiden Operatoren Retrieve und Set Role miteinander verbunden. Dies erfolgt in Rapidminer mit gedrückter Maustaste. Sobald diese Verbindung erfolgt ist, können im Parameterfenster von Set Role die Rollen der Variablen definiert werden. Bei attribute name wird Future Customer aus der Auswahlliste ausgewählt, target role für diese Variable ist label. Über edit list (0) könnte man weitere Rollen spezifizieren. Dies ist aber im vorliegenden Beispiel nicht notwendig, da alle anderen Variablen automatisch die Rolle regular zugewiesen bekommen.
III – Decision Tree Operator
Der dritte Operator ist eines der Data Mining Tools namens Entscheidungsbaum. Dazu wählt man in Rapidminer aus der Operatorenliste Decision Tree aus und zieht den Opertor in das Prozessfenster. Set Role Operator und Decision Tree Operator werden anschliessend mit gedrückter Maustaste verbunden. Das Ergebnis des Entscheidungsbaums soll ausgegeben werden. Deshalb wird zwischen dem Decision Tree mod Ausgang und res am rechten Fensterrand eine Verbindung erstellt.
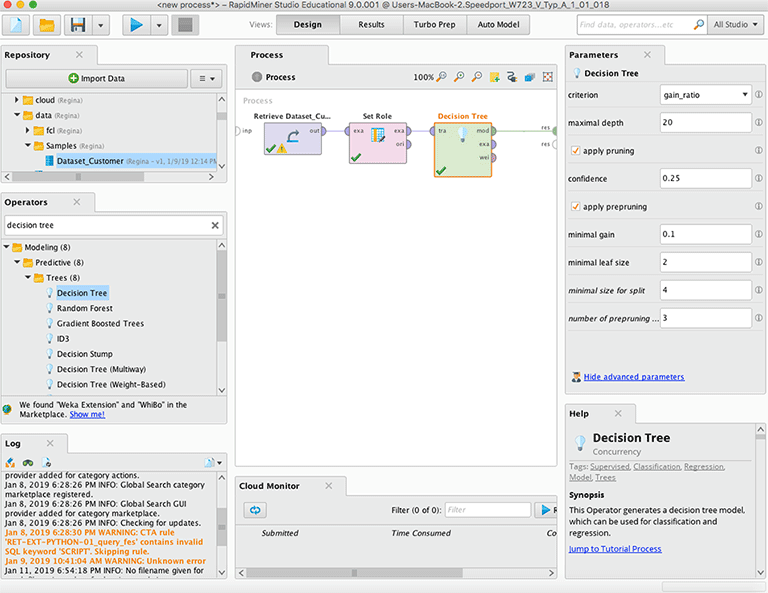
Über das Menü Process – Run Process locally kann der Prozess ausgeführt werden. Die Ergebnisse werden dann im Resultsfenster von Rapidminer angezeigt.
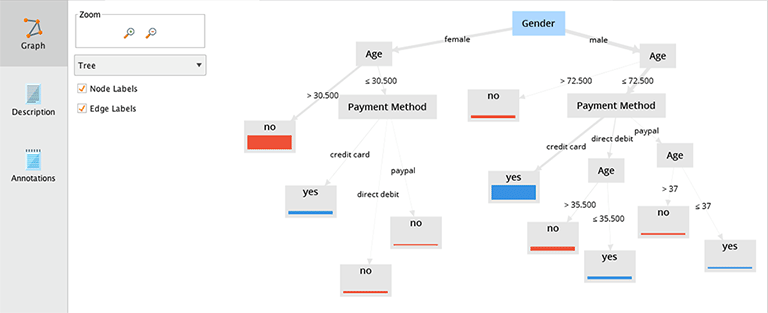
Die Entscheidungsregeln werden in Form eines Baumdiagramms ausgegeben. Alternativ dazu kann das Ergebnis in Rapidminer auch als beschreibende Darstellung angegeben werden, die bei grossen Bäumen oft übersichtlicher ist. Diese Beschreibung kann im Menüpunkt Description auf der linken Seite ausgewählt werden.

4. Ergebnisse interpretieren – was sagt der Entscheidungsbaum jetzt aus?
Der letzte Schritt im Rapidminer Tutorial besteht schliesslich darin, die gewonnenen Informationen zu lesen und zu deuten. Dieser Schritt ist Handarbeit und wird daher nicht mehr von Data Mining Software unterstützt.
Betrachten wir beispielsweie die obige Abbildung mit dem Entscheidungsbaum. Jeder Baum besitzt einen Anfang. Dieser Wurzelknoten wird dabei aus allen zur Verfügung stehenden Variablen ausgewählt. Die Auswahl wird anhand eines festgelegten Informationskriteriums getätigt. Die Variable, die am meisten Information des Zielkriteriums beinhaltet, wird ausgewählt. Anschliessend wird ein Schwellenwert gesucht, mit dem man möglichst homogene Klassifikationen hinsichtlich des Labels erhält. Dadurch entstehen neue Knoten. Für jeden dieser Knoten wird dann die Suche nach weiteren Variablen wie eben beschrieben wiederholt. Dies wird solange wiederholt, bis in den sogenannten Blättern eindeutige Klassenzuordnungen erreicht werden.
Für jedes Blatt wird dann die Entscheidung hinsichtlich des Zielkriteriums angegeben. In Rapidminer wird dies mittels der farbigen Balken in den Blättern des Baumes angegeben.
In unserem Rapidminer Tutorial stellt Geschlecht den ersten Knoten dar. Anschliessend erfolgt eine Abfrage von Alter und Zahlungsmethode. Bei den Männern findet nochmals eine Aufsplittung nach Alter statt. Der Baum liefert also eine Klassifizierung, die den Beobachtungen des Datensatzes eindeutige Klassen zuweisen.
Ein 20-jähriger Mann, der über Lastschrifteinzug (direct debit) bezahlt, wird mit diesem Entscheidungsbaum demzufolge als zukünftiger Kunde klassifiziert. Eine 40-jährige Frau dagegen wird als Einmalkäufer eingeordnet.
Zusammenfassung
Rapidminer ist eine Open Source Data Mining Software, die Data Mining in vielen Phasen unterstützt. Für die Modellierung komplexer Prozesse kann man dabei zahlreiche Operatoren verwenden. Die zur Verfügung stehenden Methoden für Data Mining Tools wachsen zudem ständig an. Entsprechend der Grundidee des Data Minings werden die Algorithmen der Data Mining Software halbautomatisch durchgeführt. Die Ergebnisse erscheinen dann in einem separaten Fenster und man kann diese für weitere Analysen weiter verwenden. In diesem Rapidminer Tutorial haben wir Ihnen Schritt für Schritt eines der Data Mining Tools näher gebracht.
Für die einzelnen Methoden kann man allerdings sehr viele Parameter variieren. Oft unterschieden sich die Ergebnisse von Data Mining Tools erheblich, wenn man die Einstellungen verändert. Ausserdem ist die Interpretation der Ergebnisse oft sehr komplex. Wir unterstüzen Sie jeodch gerne bei ihrem Data Mining Projekt! Nehmen Sie Kontakt mit uns auf!
Weitere Quellen:
Anwendung von Data Mining in der Praxis (PDF)