

In heutiger Zeit werden Unmengen von Daten erhoben und gespeichert. Bei der Auswertung dieser riesigen Datenbestände (Big Data) kommen nicht nur statistischen Verfahren sondern auch die neuen Algorithmen der Data Mining Methoden zum Einsatz. Aber hinter dem Begriff Data Mining verbirgt sich mehr als nur modernes Goldschürfen auf der Suche nach geldwertem Wissen und Informationen.
In diesem Artikel klären wir zunächst die Frage: “Was ist Data Mining?“ und geben Ihnen eine Data Mining Definition. Anschliessend stellen wir die 5 wichtigsten Data Mining Methoden vor: Clusteranalyse (Cluster Analysis), Entscheidungsbaum (Decision Tree), Vorhersage (predictive Analysis), Assoziationsregeln (Mining Association Rules) und Klassifikation (Classification).
Eine Zusammenstellung unserer Leistungen im Bereich Data Mining finden Sie auf unseren Seiten. Gerne graben wir auch in ihren Datenschätzen neues Wissen für Sie aus! Nehmen Sie Kontakt mit uns auf.
Folgende Fragen beantwortet dieser Artikel
- Was ist Data Mining?
- Welche Data Mining Methoden gibt es?
- Was ist ein Entscheidungsbaum (Decision Tree)?
- Was versteht man unter Clusteranalyse (Cluster Analysis)?
- Wie kann man Vorhersagen treffen (predictive Analysis)?
- Wie stellt man Assoziationsregeln (Mining Association Rules) auf?
- Wann benötigt man eine Klassifikation (Classification)?
Was ist Data Mining?
Mit der steigender Leistungsfähigkeit elektronischer Medien, der zunehmenden Vernetzung und dem explosionsartigem Anwachsen der Speichermöglichkeiten elektronischer Daten ist es zu einem Anstieg an verfügbaren Informationen gekommen.
Diese elektronisch verfügbaren Daten sowie die Datenmenge sind mit der Datenerhebung auf Papier allerdings nicht mehr vergleichbar. Man spricht in diesem Zusammenhang von Big Data: Sowohl die Anzahl der Daten (meist Millionen von Datensätzen), als auch die Erhebungsgeschwindigkeit (Echtzeit), sowie die Bandbreite der Erhebungsinstrumente (Kameras, Satelliten, Internet, Scannerkassen,…) sind in jeder Hinsicht big.
Solche enormen Datenmengen stellen besondere Anforderungen an die Auswertung. Analysen von Big Data sollten:
- Grosse Datenmengen effizient verarbeiten.
- Zuverlässige, leicht interpretierbare Ergebnisse liefern.
- Eine möglichst kurze Verarbeitungszeit haben.
- Für verschiedenartige Datenstrukturen (z. B. Textanalysen, Bildverarbeitung, Zahlen, Koordinaten,…) geeignet sein.
Data Mining Methoden sind Verfahren, die aus Big Data bislang unbekannte, neuartige, nützliche und wichtige Informationen „aufspüren“. Die Data Mining Definition umfasst einerseits klassische statistische Methoden wie z. B. Regressionsanalyse, logistische Regression, generalisierte lineare Modelle (GLM). Aber auch neue Machine Learning Algorithmen, die obig genannten Anforderungen erfüllen, sind gebräuchliche Data Mining Methoden. Ziel des Data Mining ist es, die gewonnenen Erkenntnisse zu verallgemeinern und so neues Wissen zu erzeugen.
Mehr zur Data Mining Definition ist in unserem Glossar hinerlegt.
Die Abgrenzung statistischer Auswertung zur Data Mining Definition ist in folgender Tabelle aufgelistet.
Statistik versus Data Mining Methoden
| Statistik | Data Mining | |
| Daten | Überschaubare Datenmengen ab einer Fallzahl von 30 | Big Data |
| Übertragbarkeit | Schlussfolgerungen erfolgen anhand einer Stichprobe der Grundgesamtheit | Grundgesamtheit existiert oft nicht Stichprobe ist nicht definiert Datenbestände ändern sich ständig |
| Auswertung | Auch mit Papier und Bleistift durchführbar | Ausschliesslich auf Computer beschränkt. |
| Zeitspanne Datenerhebung- Ergebnisse | Auswertungen dauern oft jahrelang (z. B. klinische Studien) | Ergebnisse müssen zeitnah zur Datenerhebung vorliegen (z. B. Kriminalistik, Live Website Analytics) |
| Voraussetzungen | Voraussetzungen müssen sehr genau für verwendete Verfahren überprüft werden | Data Mining Methoden sind nicht mehr theoretisch begründet Stattdessen werden Data Mining Methoden parallel verwendet. Man wählt darauf das beste Modell. Eine passende Datenstrategie ist unverzichtbar. |
| Ziel | Testen von Hypothesen | Generieren von Hypothesen |
Die 5 wichtigsten Data Mining Methoden im Überblick
Der erfolgreiche Unternehmer H.J. Geldig möchte seine Verkaufsstrategien optimieren. Aus diesem Grund sammelt er auf seinen Shopwebseiten von allen Besuchern Daten gemäss den geltenden Datenschutzgesetzen. Innerhalb kürzester Zeit hat Herr Geldig eine riesige Menge an Daten, die er Experten zur Auswertung überlässt. Sein Ziel ist es, die Verkaufszahlen zu erhöhen und den Gewinn zu maximieren.
Die Data Mining Experten raten ihm darauf zu folgenden Auswertungen:
1. Clusteranalyse – erfolgreiches Fischen im Trüben
Im Rahmen der Clusteranalyse versucht man die riesige Datenmenge in kleinere homogene Gruppen einzuteilen. Alle Mitglieder eines Clusters besitzen dabei ähnliche oder gemeinsame Eigenschaften. Zwischen den Gruppen sollen sich die Attribute oder Eigenschaften in möglichst hohem Masse unterscheiden.
Die Cluster werden ohne Vorwissen generiert. Die Ähnlichkeitsstrukturen innerhalb eines Clusters sind daher nicht auf den ersten Blick erkennbar. Was die einzelnen Cluster ähnlich macht muss anschliessend oft durch zusätzliche Analysen herausgearbeitet werden. Ausserdem entstehen gelegentlich Cluster, die inhaltlich wenig hilfreich sind.
So kann die Clusteranalyse dazu dienen, den riesigen Datenbestand auf homogene Einheiten zurückzuführen und zu reduzieren. Die weiteren Analysen werden anschliessend nur in bestimmten inhaltlich bedeutenden Clustern weitergeführt.
Im Einzelnen führt man für eine Clusteranalyse folgende Schritte durch:
- Auswahl der Variablen für die Ähnlichkeitssuche
- Festlegung des Distanzmasses: Wie wird der Abstand zwischen den Datenpunkten gemessen? Dies hängt stark von der Fragestellung und dem Skalenniveau der Daten ab. Bei nominalen Variablen verwerdendet man oft Chi-Quadrat basierte Distanzmasse. Bei metrisch skalierten Variablen kann man z.B. euklidische Distanzen oder kleinste Quadrate verwenden.
- Festlegung der Anzahl der Cluster sowie der Clusterzentren
- Zuordnung der Punkte zu den Clustern auf Basis des Distanzmasses
Die letzten beiden Punkte werden rekursiv wiederholt, solange bis alle Beobachtungen einem Cluster zugeordnet werden.
Eine detaillierte Vorstellung konkreter Clustering Algorithmen findet sich hier.
2. Der Entscheidungsbaum (Decision Tree) – Wenn man vor lauter Baum den Forest nicht sieht.
Entscheidungsbäume oder Decision Trees sind Data Mining Methoden oder Entscheidungsregeln in Form eines Baumes. Das Ergebnis ist ein Baum mit einer Wurzel und davon ausgehenden Ästen. Die Äste verzweigen sich fortlaufend an Knoten. Die Verzweigungen enden zuletzt in Blättern. Diese Blätter zeigen dann die Klassenzugehörigkeit oder die Entscheidung an.
Entscheidungsbäume sind beliebt, da sie Regeln einfach und verständlich darstellen können. Die Regeln werden hierarchisch, d. h. hintereinander in einer festgelegten Reihenfolge abgearbeitet und enden dann mit einem Ergebnis. Der Algorithmus arbeitet bei diskreten Variablen wie folgt:
- Zuerst wird das Merkmal mit dem höchsten Informationsgehalt in Hinblick auf die Vorhersage des Labels (Zielvariable) selektiert.
- Für jeden Wert, den das Attribut annehmen kann, wird anschliessend ein Zweig des Baumes erstellt.
- Für jeden neuen Knoten wird Schritt 1 und 2 wiederholt.
- Der Baum ist fertig gestellt, wenn jeder Knoten eine Klasse eindeutig identifiziert. Die letzten Knoten legen dann die Klasse fest. Diese werden auch Blätter genannt.
Im Falle stetiger Variablen werden in einem zusätzlichen Schritt geeignete Schwellenwerte berechnet. Dieses in Gruppen „zerlegte“ Attribut kann daraufhin wie ein polynomiales Merkmal verwendet werden.
Herrn Geldig ist daran interessier, einfache Regeln aufzustellen, welchen Kunden Ratenzahlung eingeräumt werden kann. Ratenzahlung mit den Ausprägungen ja/nein ist dabei das Label. Geschlecht, Alter und bevorzugte Zahlungsmethode sind Prädiktoren. Der auf Basis des Datenbestandes generierte Entscheidungsbaum ist in der folgenden Abbildung zu sehen. Die Wurzel des Baumes ist Geschlecht. Dies ist also die Variable mit dem initial höchsten Informationsgehalt. In den Blättern ist jeweils die Entscheidung für die Einräumung einer Ratenzahlung abzulesen. Einer 40 jährigen Frau wird aufgrund dieses Entscheidungsbaumes die Ratenzahlung verweigert.
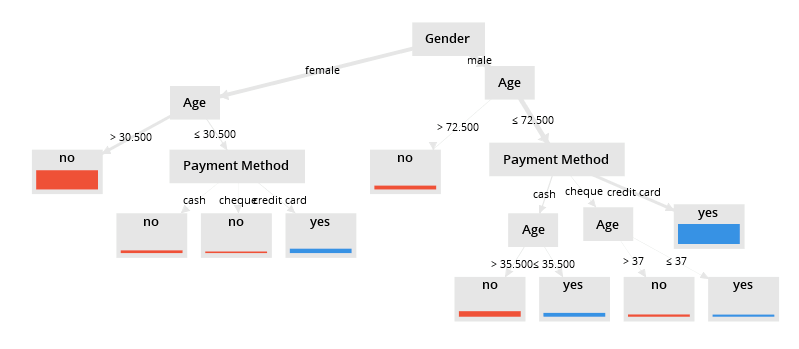
Decision Trees: Vorsicht vor Overfitting!
Entscheidungsbäume sind leicht zu interpretieren, allerdings führt dieser Algorithmus nicht unbedingt zu dem Baum mit der besten Klassifikation. Da der Baum weiter wächst, bis die Daten eindeutig einer Gruppe zugeordnet werden können ist die Gefahr des Overfittings gross.
Von Overfitting spricht man, wenn Modelle zu stark spezifiziert sind. Diese Modelle sagen zwar die Daten, für die sie optimiert sind, fehlerfrei vorher. Allerdings ist dadurch eine Generalisierung und die Übertragbarkeit auf andere Daten nicht mehr gewährleistet. Grund dafür ist die Hinzunahme zu vieler Einflussvariablen. Entscheidungsbäume mit sehr vielen Stufen und Blättern passen sich den Trainingsdaten perfekt an, führen aber bei anderen Daten zu sehr hohen Fehlerquoten. Um Overfitting zu verhindern, sollte man den Entscheidungsbaum im nachhinein oft kürzen. Diesen Vorgang nennt man Prunning. Zweige mit wenig Informationsgehalt werden im Nachhinein wieder entfernt. Eine weitere Möglichkeit ist die Verwendung von Random Forest Methoden. Dabei werden viele Entscheidungsbäume auf den gleichen Daten generiert, die Klassenzugehörigkeit einzelner Beobachtungen basiert auf einer gemeinschaftlichen Entscheidung über alle Entscheidungsbäume hinweg.
3. Wer mit Wem? – Assoziationsregeln
Assoziationsregeln werden aufgestellt, um Zusammenhänge sichtbar zu machen. Diese Assoziationsregeln werden auch als Abhängigkeitsregeln bezeichnet. Die Data Mining Experten raten Herrn Geldig die Warenkörbe seiner Kunden mit Assoziationsregeln zu untersuchen. Auch Suchverläufe kann man mit Assoziationsregeln analysieren. Dadurch entstehen beispielsweise Aussagen wie: Wenn ein Kunde rote Wollpullis sucht, kauft er mit grosser Wahrscheinlichkeit auch gelbe Socken. So können die Experten Kundenprofile erstellen und beispielsweise Werbung gezielt platzieren.
Assoziationsregeln werden aufgestellt, indem die Häufigkeit für unterschiedliche Mengen und Teilmengen ermittelt werden. Dabei sind vor allem sogenannte frequent Item Sets von Interesse. Darunter versteht man Mengen, also zum Beispiel Warenkörbe, bei denen die Häufigkeit bestimmter Kombinationen eine vorgegebene Schranke übersteigt. Dabei wird zunächst jedes Attribut einzeln untersucht und dann schrittweise weitere Attribute hinzugenommen, die auch die frequent item set Bedingung erfüllen. Dadurch erhält man Kombinationen von Attributen, die sehr häufig in Kombination auftreten. In diesen häufig auftretenden Kombinationen werden dann alle Zerlegungen gebildet und daraus die Folgerungen aufgestellt.
4. Vorhersage Modell (predictive Analysis oder predictive Analytics) – Prognosen für die Zukunft
In der predictive Analysis oder auch predictive Analytics werden anhand der Daten Vorhersagemodelle für die Zukunft erstellt. In Rahmen eines Modells versuchen Experten dabei anhand von Einflussgrössen (Prädiktoren) die Zielgrösse (label) vorherzusagen.
Bei dem Modell kann es sich im einfachsten Fall um einen linearen Zusammenhang handeln. Die Wahl des Modells hängt dabei vom Skalenniveau der Zielvariable (label) ab. Bei dichotmonen Label (ja/nein Ausprägungen) ist eine logistische Regression im Rahmen eines GLM möglich. Für stetige Label steht dagegen die lineare Regression zur Verfügung. Es können aber auch rein datenerzeugte Systeme wie zum Beispiel neuronale Netze sein. Auch Support Vector Machines, Deep Learning Models oder Naive Bayes Modelle sind möglich.
Meist wendet man im Data Mining mehrere mögliche Modelle parallel an. Anschliessend ermittelt man dann mittels Kreuzvalidierung die Modellgüte ermittelt. Für die Vorhersage verwendet man anschliessend das Modell mit dem besten durchschnittlichen Fit.
Die meisten Modelle haben derart komplexe Algorithmen, dass sie für Anwender nicht mehr verständlich sind.
Bei Herrn Geldigs Daten können predictive Analysis verwendet werden, um Kunden zu einem erneuten Kauf in seinem Shop zu bewegen. Dies kann z. B. dadurch erfolgen, dass Marketingaktivitäten erfolgen, noch bevor der Kunde sich anderweitig informierten muss. Kunden, die eine Kaffeemaschine kaufen, benötigen in bestimmten Zeitabständen Kaffe oder Reinigungsprodukte. Auch Retourenquoten lassen sich mittels predictive analytics und geeigneten Daten vorhersagen.
5. Klassifikation – Jedem seine Klasse!
Im Data Mining werden effiziente Algorithmen angewendet, die Informationen aus einem (meist sehr grossen) Datenbestand extrahieren können. Eine typische Aufgabenstellung ist es, aus dem Datenbestand Regeln abzuleiten. Anhand dieser Regeln können dann zukünftige oder neue Beobachtungen vorgegebenen Klassen oder Kategorien zugeordnet werden. Klassifikationsverfahren ordnen dabei Objekte in vorgegebene Klassen anhand der gefundenen Zuordnungsregeln ein.
In der Klassifikation werden die Objekte bestimmten Klassen oder Gruppen zugeordnet. In unserem Beispiel wenden die Experten Klassifikation an, um Käufer und Nicht-Käufer zu unterscheiden. Anhand der Klassifikation werden hierzu Entscheidungsregeln in den Daten gesucht. Mit diesen Regeln sollen dann Käufer von Nicht-Käufern unterschieden werden können. Zur Klassifikation zählen beispielweise Data Mining Methoden wie neuronale Netze, Bayes-Klassifikation und k-nächste Nachbarn Verfahren. Auch Entscheidungsbäume zählen zu den Klassifikationsverfahren.

Data Mining Klassifikation: Ein Allrounder
Die Anwendungsmöglichkeiten für Data Mining Klassifikation sind sehr vielfältig:
- Medizin: Diagnostizieren einer Krankheit
- Wirtschaft: Überprüfen der Kreditwürdigkeit, Warenkorbanalysen, Kundenabwanderung (Churn Prediction)
- Texterkennung: Sentiment Analyse, Spam Detection bei E-mail Programmen
- Versicherung: Risikoberechnung
- Bildverarbeitung: Gesichtserkennung, autom. Warenerkennung an Scanner
- Biologie: Bestimmung von Tieren, Pflanzen und Lebewesen anhand von Bildern, Artenbildung, Zuordnung von Hunderassen, …
Data Mining Klassifikation: Erst lernen, dann anwenden
Data Mining Klassifikation besteht aus zwei Schritten: Zunächst durchläuft das Modell eine Trainingsphase. In dieser Phase werden Regeln generiert, mithilfe derer die Objekte den vorgegeben Klassen zugeordnet werden können. In der zweiten Phase überprüft man anschliessend diese Regeln an einem Testdatensatz.
Für das zweistufige Vorgehen hat es sich bewährt, den Ausgangsdatensatz in zwei Teile zu trennen: Trainingsdaten und Testdaten. Sind sowohl bei Test – als auch bei Trainingsdaten die tatsächlichen Klassenzugehörigkeiten bekannt, kann die Klassifikationsgüte angegeben werden.
Abhängig davon, wie die Aufteilung durchgeführt wird, ergeben sich dabei unterschiedliche Regeln und Klassifikationsgütemasse. Um eine Robustheit gegenüber zufälligen Aufteilungen zu gewährleisten, wird die Klassifikation für sehr viele verschiedene Aufteilungen durchgeführt. Anschliessend werden die unterschiedlichen Modelle und Testergebnisse wieder zusammengefügt und kombiniert. Ein solches Splitting Verfahren ist beispielsweise die Kreuzvalidierung (Crossvalidation).
Data Mining Klassifikation: Die wichtigsten Verfahren
Die vier wichtigsten Verfahren der Data Mining Klassifikation sind Entscheidungsbaum (Decision tree), neuronale Netze, das Nächste-Nachbarn Verfahren und die Bayes Klassifikation.
| Entscheidungsbaum | Neuronale Netze | Nächste Nachbarn Verfahren | Bayes Klassifikation | |
|---|---|---|---|---|
| Vorteil | – Sehr einfach zu interpretierende Wenn-Dann Regeln – Können auch zur Priorisierung von Regeln verwendet werden | – Sehr gutes Handling von Ausreissern – Hohe Klassifikationsgüte bei Klassen, die nicht in der Trainingsmenge vorkommen – Bei metrischer Zielvariable anwendbar – Keine Linearität des Zusammenhangs notwendig | – Für metrische und kategorielle Merkmale anwendbar | – Hohe Genauigkeit auch bei grossen Datenmengen |
| Nachteil | – Wird bei vielen Variablen sehr schnell unübersichtlich – Bei Verzweigungen werden metrische Variablen kategorisiert | – Berechnungen schwer nachvollziehbar (Blackbox) – Sehr hoher Rechenaufwand | – Es müssen stets alle Trainingsdaten für die Klassifizierung verwendet werden – hoher Rechenaufwand | – Falsche Annahmen führen zu ungültigen Klassifizierungen |
Data Mining Klassifikation: Gütemasse für die Klassifikation
Durch die Überprüfung der Klassifikationsregeln anhand eines Testdatensatzes mit bekannter Klassenzugehörigkeit kann die Klassifikationsgüte angegeben werden. Wie auch bei den Gütemassen zur Regression ist für die Beurteilung der Güte auch die Kompaktheit des Modells (z. B. die Anzahl der Regeln) und die Interpretierbarkeit der Regeln ein wichtiger Aspekt. Die Klassifikationsgenauigkeit ist dabei der Anteil der korrekten Klassenzuordnungen im Testdatensatz bezeichnet. Den Anteil der falschen Klassenzuweisungen nennt man Klassifikationsfehler.
Data Mining Klassifikation: Entscheidungsbaum (Decision Tree)
Ein Entscheidungsbaum ist ein Verfahren zur Klassifikation. Entscheidungsbäume lassen sich gut visualisieren, können allerdings auch sehr komplex werden. Bei einem Entscheidungsbaum kann man jede Entscheidung bewerten bzw. gewichten. Dies spielt insbesondere dann eine Rolle, wenn die Entscheidungen unterschiedliche Kosten haben. Insgesamt werden mit einem Entscheidungsbaum alle möglichen Alternativen dargestellt.
Ein Entscheidungsbaum ist immer von oben nach unten aufgebaut. Bei jeder Entscheidungsalternative verzweigt sich der Baum um eine Ebene nach unten. Am unteren Ende des Entscheidungsbaumes stehen schliesslich die Blätter, in den Blättern sind die Entscheidungen zu sehen.
Beispiel aus der Beratungspraxis: Churn Modelling eines Telekomunikationsanbieters
Ein Anbieter für Telekommunikation möchte herausfinden, welche Kunden abwandern, d.h. ihre bestehenden Verträge kündigen. Es stehen dabei 9990 Datensätze von Kunden zur Verfügung. Insgesamt sind 21 der 9990 Kunden abgewandert. In dem Datensatz stehen ausserdem Informationen zum Vertragsbeginn, zum durchschnittlichen monatlichen Grundpreis, dem Alters des Kunden sowie die Art des Vertrags (4G, Telefon, Glasfaser oder Festnetz) und die Anzahl der Supportkontakte im letzten Jahr zur Verfügung.
Das Ziel der Auswertung besteht darin, mögliche Abwanderer in Zukunft bereits frühzeitig zu identifizieren und schliesslich durch geeignete Massnahmen eine Kündigung abzuwenden.
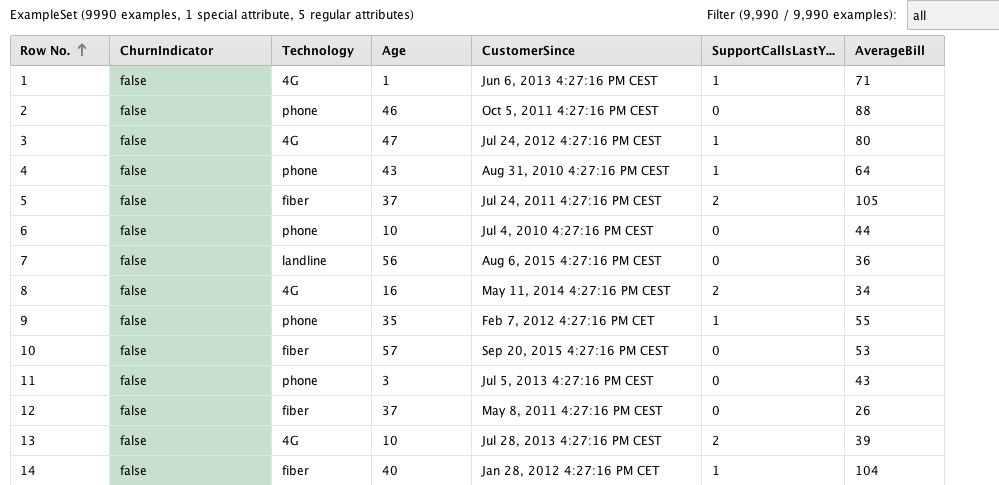
Lösungsvorschlag: Entscheidungsbaum
Mit 10-facher Kreuzvalidierung wird zuerst ein Entscheidungsbaum generiert. Da nur wenige Kunden abwandern, wird eine balancierte Stichprobenziehung gewählt. Der Entscheidungsbaum soll dabei auf maximal 20 Blätter beschränkt sein, um eine unnötige Komplexität zu vermeiden. Mit Pruning (Beschneiden) kann ebenfalls eine Optimierung hinsichtlich Klassifikationsgüte und Komplexität erreicht werden.
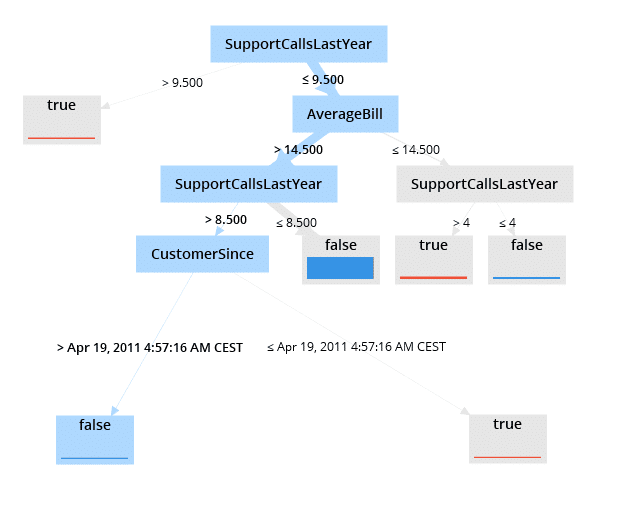
Den Entscheidungsbaum liest man zuerst von oben nach unten. Blau hinterlegte Rechtecke zeigen dabei die Variablen an. An den Verbindungen zur nächsten Ebene sind die Entscheidungsregeln zu finden. Als wichtigstes Kriterium für die Abwanderung zeigt sich die Anzahl der Service Anrufe. Übersteigt die Anzahl der Anrufe 9,5, also ab 10 Anrufen, klassifiziert man den Kunden als Abwanderer. Hier endet der Entscheidungsbaum dann bereits in einem Blatt (grau ausgefülltes Rechteck). Bei 9 oder weniger Serviceanrufen unterteilt sich der Entscheidungsbaum allerdings weiter. Als nächste Kriterien sind dann die durchschnittliche Rechnungshöhe sowie die Anzahl der Supportanrufe zu sehen.
Liest man einen Entscheidungsbaum von unten nach oben, so erkennt man, dass sich abwandernde Kunden durch drei Kriterien auszeichnen:
- Mehr als 9 Support Anrufe oder
- Weniger als 9 und mehr als 4 Supportanrufe im letzten Jahr sowie eine durchschnittliche Rechnung unter 14,50 €
- Vertragsabschluss vor 19.04.2011, weniger als 8 Supportanrufe sowie eine durchschnittliche Rechnung von mehr als 14,50 €
Alter der Kunden sowie Art des Vertrags haben angesichts der ausgewählten Variablen dabei keine zusätzlichen Informationen hinsichtlich des Zielkriteriums.
Modellgüte:
Durch die Kreuzvalidierung ist eine Schätzung der Prognosegenauigkeit möglich.

Der obige Entscheidungsbaum kann 98,46 % der Daten richtig klassifizieren. 17 der 21 Abwanderer können also identifiziert werden. 98,5 % der treuen Kunden können ebenfalls korrekt klassifiziert werden.
Data Mining Klassifikation: Neuronale Netze Beispiel
Im folgenden Beispiel möchten wir den Umsatz eines Unternehmens anhand von 5 Attributen vorhersagen. Die 5 Attribute (Verkäufe, Lohnkosten, Zufriedenheit, Marketing sowie Zeit) sind stetig und zeigen nicht lineare Zusammenhänge mit dem Umsatz.
Lösungsansatz: Neuronales Netz
Aufgrund der nicht linearen Zusammenhänge kann kein Regressionsmodell verwendet werden. Zudem soll das Modell einfach anzuwenden sein und die Daten gut vorhersagen. Als Verfahren bietet sich daher ein neuronales Netz an.
Der Datensatz wird zuerst in Test und Trainingsdatensatz geteilt. Mit dem Trainingsdatensatz wird dann das neuronale Netz zur Vorhersage des Umsatzes gebildet. Anschliessend wird das neuronale Netz auf den Trainingsdatensatz angewendet, um die Vorhersagegüte zu schätzen.
Die 5 Attribute werden vor der Analyse normiert und können somit als Input Variable verwendet werden. Durch neuronale Netze werden die Inputvariablen gewichtet und aufsummiert. Diese Gewichtung und Summation erfolgt dabei in Schichten. In den Schichten befinden sich Knoten (oft auch als Neuronen bezeichnet), die miteinander in Verbindung stehen. Am Ende der Verarbeitung wird ein Ergebnis ausgegeben.
Eine Besonderheit für neuronale Netze ist zum einen, dass diese alle Signale gleichzeitig verarbeiten. Zum anderen lernt das System selbstständig. Als Lernen bezeichnet man dabei die Modifikation der Gewichte aufgrund des Datenflusses.
Aufgrund der komplexen Struktur wird ein neuronales Netz oft als Blackbox dargestellt.
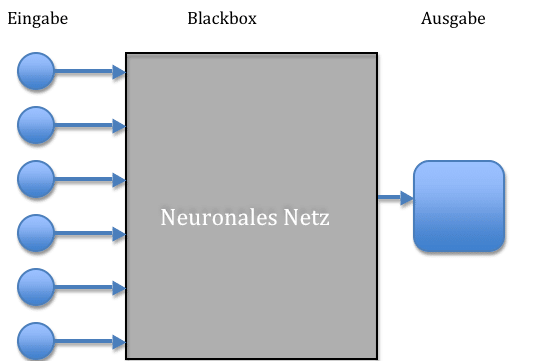
Interpretation Neuronales Netz
Bei der Schätzung der Umsätze ergibt sich folgendes neuronales Netz:
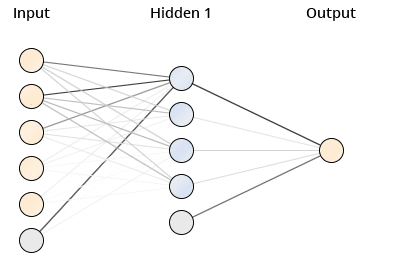
Für jedes der fünf Attribute existiert ein Input Knoten (rosa Kreis). Darüber hinaus wurde noch ein weiterer Hilfsknoten zur Modellierung verwendet (Bias Node, blau). Die mittleren Kreise bilden die Zwischenschicht (Hidden Layer). Jeder Input besitzt eine Verbindung zu jedem inneren Knoten. Die Output Schicht ist repräsentiert durch einen Knoten, der Zielvariable Umsatz.
Die Stärke der Verbindung wird durch dessen Intensität dargestellt. Farbintensive und dicke Linien stellen Verbindungen dar, die ein hohes Gewicht besitzen. Durch das neuronale Netz erhält man vorhergesagte Werte für den Umsatz. Vergleicht man diese mit den tatsächlichen Werten des Datensatzes, so kann man Angabe zur Modellgüte machen. Mögliche Grössen zur Bestimmung der Modellgüte sind etwa RMSE oder das Bestimmtheitsmass.
Zusammenfassung
In diesem Artikel haben wir Ihnen die 5 wichtigsten Data Mining Methoden nähergebracht und erläutert. Eine Gegenüberstellung der Data Mining Methoden ist nachfolgender Tabelle zu entnehmen. Die Verwendung der Methoden im Data Mining erfolgt oftmals explorativ, die Verfahren im Hintergrund sind allerdings äusserst komplex und anspruchsvoll. Insbesondere die Interpretation der Ergebnisse und die Übertragbarkeit ist ein heikles und schwieriges Thema. Aufgrund riesiger Datenmengen lassen sich perfekte Modelle entwickeln, die jedoch nicht immer auf andere Daten übertragbar sind. Gerne helfen wir Ihnen, ihre Datenbestände professionell auszuwerten und zeitnah, verständlich, kundenorientiert und effektiv die Ergebnisse ihres Data Mining Projekts zu präsentieren.
Wir kümmern uns unabhängig und zuverlässig um alle Aspekte im Umgang mit Big Data. Nehmen sie Kontakt mit uns auf!
| Zielvariable (label) | Aussage | Einschränkung | |
| Clusteranalyse | Keine, Cluster werden automatisch gebildet | Bildung homogener Gruppen, Reduzierung der Datenmenge | Ähnlichkeitsmerkmale müssen nachträglich bestimmt werden |
| Assoziationsregeln | kategoriell | Wenn – Dann Regeln | Sind nur für Datenset gültig, Übertragbarkeit insb. mit zeitlicher Komponente muss überprüft werden. |
| Vorhersage Modell (predictive analysis) | Beliebig, Modellwahl von Skalenniveau abhängig | Vorhersage Modelle für zukünftige Ereignisse | Bestes Modell muss anhand von Kriterien (z. B. Interpretierbarkeit, Fit, …) bestimmt werden |
| Klassifikation | kategoriell | Zuordnung zu fest vorgegebenen Klassen | Vielzahl möglicher Algorithmen, Problem des Overfittings |
| Entscheidungsbaum (Decision Tree) | kategoriell | Hierarchische Entscheidungsregeln | Gefahr Overfitting, unübersichtlich bei sehr vielen Leveln |
Weitere Quellen:
Wikipedia Übersichtsartikel zu Data Mining
Einführung in wichtige Data Mining Verfahren der TH Nürnberg
Data Mining Einführung von Klaus-Perter Wiedmann, Frank Buckler und Holger Buxel
Datenbeispiel Telekommunikation: RapidMiner Sample