
In diesem Artikel möchten wir Ihnen die Datenbereinigung SPSS und in diesem Zusammenhang auch den Umgang mit Extremwerten, Ausreissern und ‚falschen‘ Daten näher bringen. Denn diese Themen sind essenziell für jeden, der mit Daten arbeitet und aus seiner SPSS Auswertung valide Ergebnisse erhalten möchte. Wir haben eine Menge von statistischen Daten vor uns, die wir analysieren möchten und stehen damit unweigerlich vor der Frage: Wie bereinigen wir die Daten und wie erkennen wir Extremwerte? Was also tun im Umgang mit Extremwerten und Ausreissern? – Eine wichtige Bedeutung hat hier die Datenbereinigung, SPSS bietet dazu einige Möglichkeiten. Zugleich gilt für Extremwerte bzw. Ausreisser: Statistik bietet hierzu keine Patentlösung auf Knopfdruck. Der Beitrag zeigt daher einige Lösungsansätze auf, die helfen können, Extremwerte und ‚falsche‘ Daten aufzuspüren und zu beseitigen.
Wenn Sie Unterstützung bei der Datenaufbereitung in SPSS benötigen, helfen unsere Statistiker Ihnen gerne weiter. Kontaktieren Sie uns für eine kostenlose Beratung & ein unverbindliches Angebot!
Fehler- und Datenbereinigung SPSS
Grundsätzlich können sich Fehler bzw. fehlerhafte Daten im gesamten empirischen Forschungsprozess einschleichen, also sowohl im Rahmen der Datenerhebung als auch bei der Dateneingabe und der Datenaufbereitung. Die Beispiele reichen von falschem Ankreuzen oder fehlerhaften Angaben durch die Probanden über Tippfehler bis hin zu (Um)Codierungsfehler bei der Aufbereitung der Daten.
Sie wünschen Hilfe bei der Aufbereitung Ihrer Daten in SPSS oder bei anderen Aspekten der statistischen Auswertung? Kontaktieren Sie uns für eine professionelle Unterstützung bei der SPSS Auswertung! Von der Beratung zu statistischen Themen, über Datenaufbereitung bis hin zur vollständigen Auswertung – unsere Experten helfen Ihnen schnell und kompetent weiter.
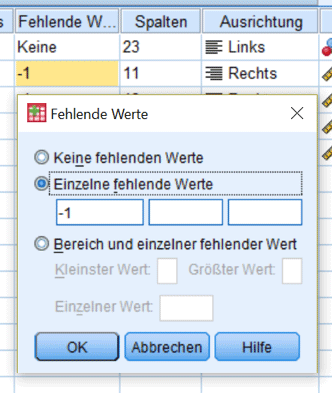
Fehler können in SPSS sowohl systembedingt als auch nutzerbedingt auftreten. Systembedingte Missings beispielweise sind die Folge von bedingten Skalierungen im Zuge einer Filterführung, deren Datenbereinigung SPSS automatisch durch einen Punkt anzeigt. Userseitig sind Fehler zum einen die Folge eines bewussten Definierens von Missing-Values. Typischerweise werden hier Zahlenwerte gewählt, die im Datensatz nicht vorkommen, beispielsweise 101, -1 oder -99.
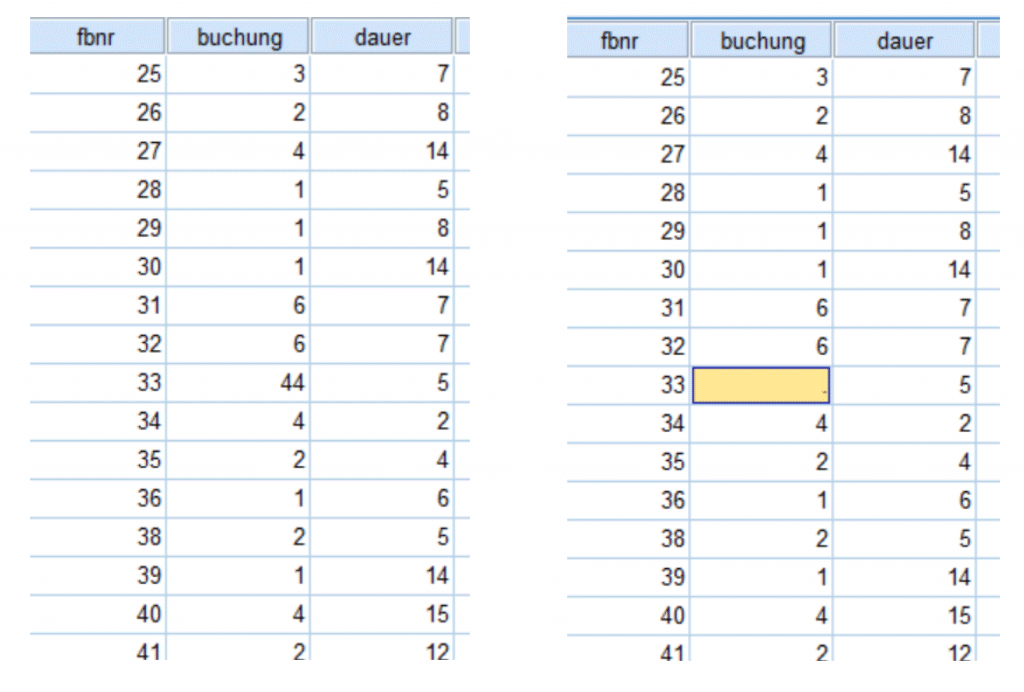
Zum anderen sind falsche Daten auf Nutzerseite die Folge von (unbeabsichtigten) Tippfehlern bei der Eingabe. Solche fehlerhaften Werte gilt es idealerweise zu korrigieren, sofern die Möglichkeit zur Einsicht in die Originalfragebögen (mittels eindeutiger Identifikationsnummer) besteht. Ist ein falscher Wert offensichtlich erkennbar, jedoch nicht belegbar, so bleiben zwei weitere Optionen: entweder den Wert oder das Merkmal im Datensatz zu löschen und durch ein Missing-Value zu ersetzen oder gegebenenfalls den gesamten Fall zu entfernen. Das bedeutet natürlich zwingend eine Datenreduktion der ursprünglichen Rohdatensatzes. Hier gilt es vorab gut zu überlegen, inwieweit eine solche Reduktion des Datensatzes die Aussagekraft der Ergebnisse beeinflusst.
Fehlervermeidung vorab im Fragebogen
Filterfragen sollten schon im Fragebogen klar und einfach gestellt bzw. im Falle eines elektronischen (Online-)Fragebogens korrekt und eindeutig definiert werden. Dies gehört zu der Entwicklung eines gut strukturierten Forschungsplans. Probanden sollten zudem die Möglichkeit zur Antwortenthaltung haben, zB. durch ‚keine Angabe‘ oder ‚weiss nicht‘. Und: Es gilt immer auch auf die Art der Formulierung von Fragen achten, diese kann zu Verzerrungen in den Ergebnissen führen, zu einem sogenannten Bias. Eine Form der systematischen Verzerrung sind suggestive Fragestellungen, die zu sozial erwünschten Ergebnissen führen können. Ein Beispiel: ‚Finden Sie nicht auch, das Statistik langweilig ist?‘
Extremwerte und Ausreisser, Statistik: Was tun?
Eine guter und relativ einfacher Weg, mittels einfacher deskriptiver Statistik Ausreisser und offensichtliche Messfehler zu erkennen, sind Häufigkeitstabellen und Boxplot. Ebenso lassen sich über Minimum und Maximum leicht fehlerhafte Daten und Tippfehler aufspüren. Eine weitere etwas anspruchsvollere Möglichkeit ist es, die Daten auf Normalverteilung zu testen bzw. die Schiefe der Daten zu prüfen. Liegt eine erheblich Schiefe vor, kann dies ein Indiz sein, die Daten nochmals individuell im Detail nach nicht plausiblen Messwerten zu überprüfen und eventuell auszuschliessen.
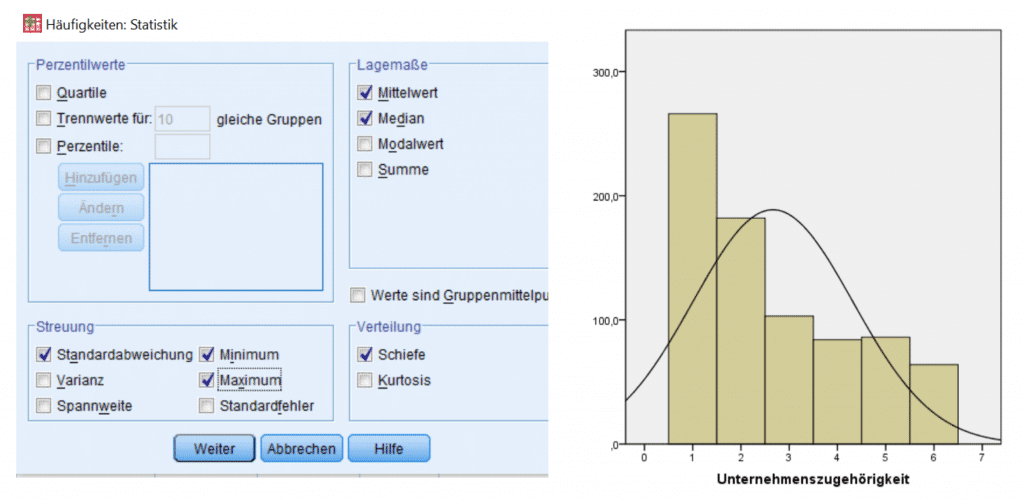
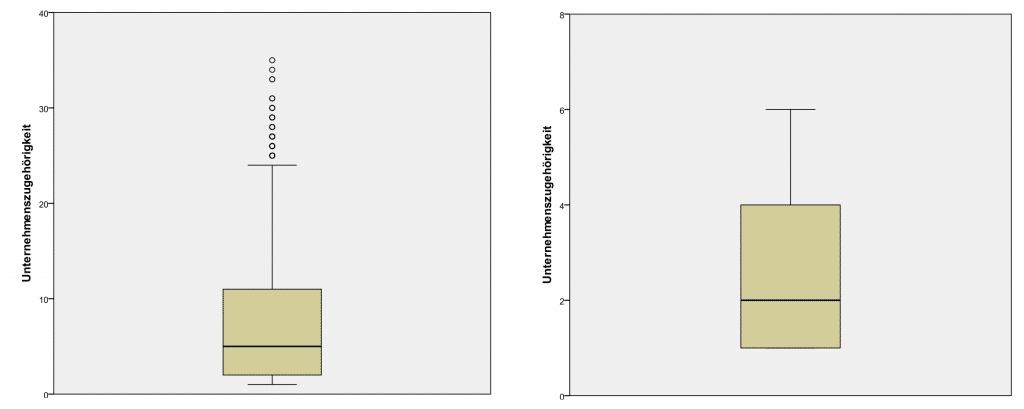
Im folgenden Beispiel lassen sich Extremwerte bzw. Ausreisser – SPSS verdeutlicht dies anhand von Boxplots – gut erkennen. Wir verwenden häufig für die Datenbereinigung SPSS, da dies uns eine Vielzahl von Funktionen für die Korrektur bzw. Eliminierung von Ausreissern bietet, und die Ausreisser Statistik zeigt danach, wie die Schiefe der Verteilung deutlich abgenommen hat.
Ein letzter Punkt, der im Rahmen von Ausreisser Statistik erwähnt werden soll, betrifft Onlineerhebungen und dem damit verbundenen Zeitfaktor beim Ankreuzen. Gemäss der Regel: Wer sich durch die Fragen einfach nur durchklickt, benötigt weniger Zeit. Konkret heisst das: Über die Variable Zeitdauer lassen sich jene Fälle aussortieren, die deutlich unter der mittleren Ausfülldauer des Fragebogens bleiben und damit für die Auswertung nicht valide erscheinen.
Datenbereinigung SPSS: Fazit
Wie die genannten konkreten Beispiele und Empfehlungen gezeigt haben, ist es sinnvoll, Extremwerte und Messwerte allgemein immer auch individuell und kritisch durch den Nutzer zu hinterfragen. Für Ausreisser SPSS einzig und alleine heranzuziehen, ist meist nicht ausreichend.
Zusammenfassend ist hilfreich:
- Filterfragen eindeutig und korrekt setzen
- Möglichkeit zur Antwortenthaltung
- Korrektur falscher Daten
- Nicht plausible Werte im Datensatz löschen
- gesamten Fall aus Datensatz entfernen
Weiterführende Links
Uni Hamburg – SPSS Datenbereinigung
Lück, Landrock (2014): Datenaufbereitung und Datenbereinigung in der quantitativen Sozialforschung