
In diesem Artikel wollen wir Ihnen eine Schritt-für-Schritt-Anleitung für die Aufbereitung von Daten in SPSS an die Hand geben. Wir zeigen Ihnen dazu wie Sie richtig in SPSS Daten importieren. Datenaufbereitung ist der Grundbaustein für erfolgreiches Datenmanagement und daher essentiell für die Datenqualität. Schliesslich ist jede Analyse nur so gut wie die Qualität Ihrer Daten! Eine gründliche Datenaufbereitung kostet zwar anfangs ein wenig Aufwand, dafür sparen Sie aber später ein Vielfaches der investierten Zeit.
Wenn Sie Unterstützung bei der Datenaufbereitung in SPSS benötigen, helfen unsere Statistiker Ihnen gerne weiter. Kontaktieren Sie uns für eine kostenlose Beratung & ein unverbindliches Angebot!
Richtige Datenaufbereitung für die Auswertung von Fragebögen
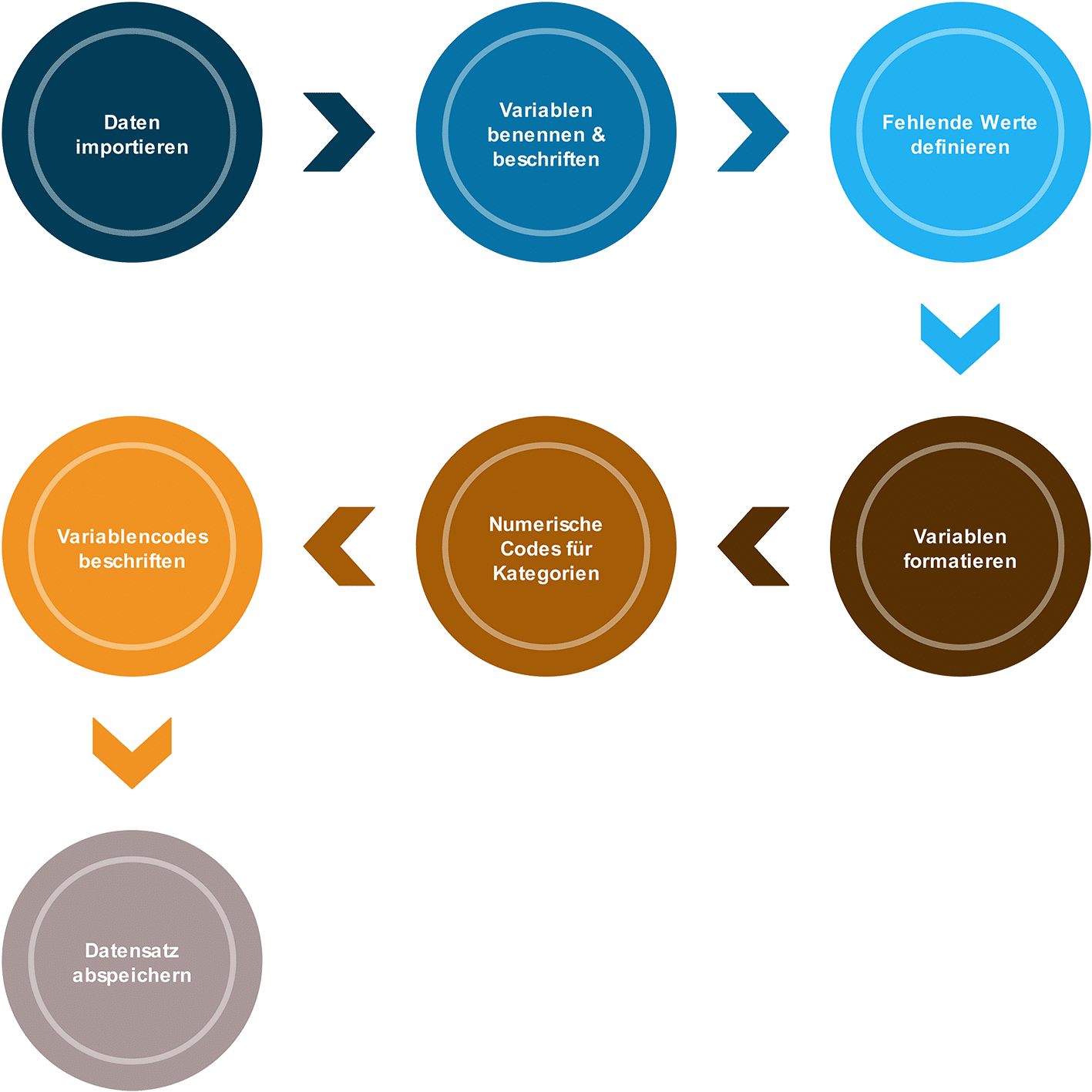
Im Wesentlichen lässt sich die Datenaufbereitung in sieben Schritte unterteilen, die im Folgenden näher besprochen werden.
Sie wünschen Hilfe bei der Aufbereitung Ihrer Daten in SPSS oder bei anderen Aspekten der statistischen Auswertung? Kontaktieren Sie uns für eine professionelle Unterstützung bei der SPSS Auswertung! Von der Statistik Beratung, über Datenaufbereitung bis hin zur vollständigen Auswertung – unsere Experten helfen Ihnen schnell und kompetent weiter.
Schritt 1: In SPSS Daten importieren – das richtige Dateiformat entscheidet
Zuerst müssen Sie Ihre Daten in SPSS importieren. Die folgenden Hinweise sollen Ihnen dabei helfen mögliche Probleme wie fehlerhafte Variablennamen oder falsche Werte zu vermeiden. Verschiedene Dateiformate haben dabei unterschiedliche Vor- und Nachteile. Ausserdem sollten Sie bereits von Anfang an darauf achten, ob Sie die Daten im Wide- oder Long-Format darstellen möchten.
Vor- und Nachteile der verschiedenen Dateiformate
| Dateiformat | Vorteile | Nachteile |
| SPSS-Format (.sav) | Einfach zu importieren | Möglicherweise Fehler bei der Formatierung, wenn automatisch erstellt |
| Excel (.xlsx oder .xls) | Problemlose Dateneingabe und Korrektur in Excel | Import von komplexen Datensätzen kann zu Problemen bei Formatierung und Erkennung von Datentypen führen |
| Textdatei (.csv oder .txt) | Für erfahrene Benutzer erlaubt dies die vollständigste Kontrolle über den Datenimport | Inspektion und Import der Daten verhältnismässig umständlich |
Daten im SPSS-Format (.sav)
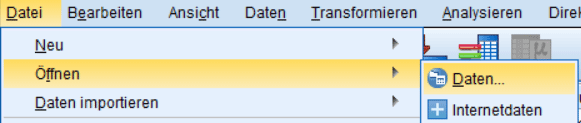
Wenn die Daten bereits im SPSS-Format (.sav) vorliegen, gestaltet sich das Importieren der Daten denkbar einfach.
Aber auch wenn Sie SPSS Daten importieren, sollten diese stets auf Fehler geprüft werden. Dies gilt insbesondere für die Auswertung von Fragebögen, denn manche Plattformen für Online-Umfragen neigen beim Export in das SPSS-Format zu Fehlern.
Daten im Excel-Format (.xlsx oder .xls)
Liegen Ihre Daten im Excel-Format vor (.xlsx oder .xls) gestaltet sich der Import meist ebenfalls problemlos. Allerdings sollten Sie die Excel-Datei vorher in Excel inspizieren, um potenzielle Probleme zu vermeiden. Achten Sie dabei darauf, dass die erste Zeile die Namen der Variablen enthält und diese keine Sonderzeichen oder Umlaute enthalten. Überprüfen Sie auch, ob die Daten direkt auf der zweiten Zeile beginnen.
Bei der Dateneingabe SPSS werden die Variablen üblicherweise mit Zahlen codiert, beispielsweise das Geschlecht mit den Zahlen 1 und 2. Sie können die Variablen später immer noch mit „weiblich“ und „männlich“ beschriften. Die Excel-Datei sollte nur den reinen Datensatz ohne Anmerkungen, Berechnungen oder Diagramme enthalten, sonst können Sie nicht in SPSS Daten importieren. Zudem sollte nach Möglichkeit die Datenbereinigung schon vorher abgeschlossen werden.
Sowohl in SPSS als auch in R (mit RStudio) können Sie Daten über eine grafische Benutzeroberfläche importieren. In RStudio wählen sie dazu im Fenster oben rechts das Menü „Import Dataset“ und anschliessend „From Excel…“. Eventuell wird vorher das für den Import benötigte Paket installiert. In SPSS wählen Sie „Datei –> öffnen“ und ändern den Datentyp auf „Excel“. Anschliessend wählen Sie die Excel-Datei im passenden Verzeichnis aus.
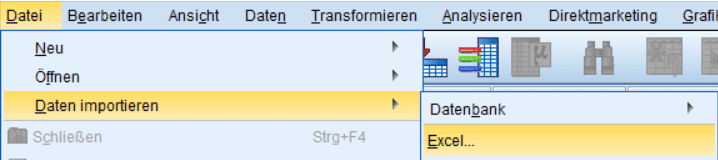
Daten im Textformat (.txt oder .csv)
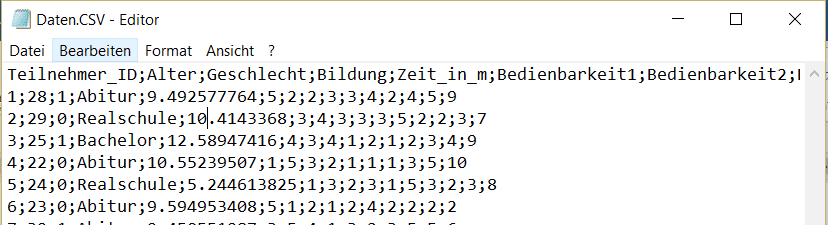
Falls Sie in SPSS Daten importieren möchten, die im Textformat vorliegen (.txt oder .csv), benötigt dies etwas mehr Sorgfalt. Zuerst sollten Sie die Datei in einem Texteditor prüfen. Notieren Sie sich dabei folgende Punkte:
- Befinden sich die Namen der Variablen in der ersten Zeile?
- Ist die Dezimalstelle ein Punkt oder Komma?
- Wie sind die Einträge abgetrennt? Übliche Trennzeichen sind Semikolon oder Komma, aber auch Punkt, Leerzeichen oder Tabstopp sind möglich.
Nach diesem Schritt geht das Importieren der Daten dann meist leicht von der Hand. Wählen Sie hierzu in SPSS „Datei -> Datei importieren“ und dann je nach Endung „CSV-Daten“ (für .csv) oder „Textdaten“ (für .txt).
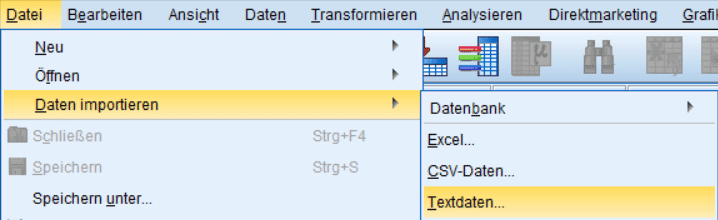
Sie können anschliessend die SPSS Daten importieren, indem Sie von SPSS durch die folgenden Schritte geführt werden, die mit Hilfe Ihrer Notizen kein Problem darstellen sollten.
Exkurs: Wide-Format oder Long-Format für die SPSS Dateneingabe?

Bei der SPSS Dateneingabe stellt sich die Frage, in welchem Format man die Daten haben möchte, im klassischen Wide-Format oder doch eher im Long-Format? In diesem Abschnitt erklären wir Ihnen die Eigenschaften und Besonderheiten dieser beiden Formate.
Das Wide-Format und das Long-Format (manchmal auch ungestapelt und gestapelt genannt) sind Begriffe, welche verwendet werden, um zwei verschiedene Darstellungen von Tabellendaten zu beschreiben.
Die gebräuchlichere Darstellungsmethode der beiden ist das Wide-Format, in welchem jede Spalte eine Variable repräsentiert. Messwiederholte Variablen erhalten pro Zeitpunkt jeweils eine eigene Spalte. Diese intuitive Darstellungsweise ist übersichtlich, wird jedoch nicht von allen statistischen Verfahren unterstützt.
Im Long-Format werden die gesamten Werte der messwiederholten Variable in einer einzigen Spalte dargestellt. Daher werden die Daten im Long-Format auch als “gestapelt” bezeichnet. Die zu den Messwerten gehörenden Zeitpunkte werden in einer separaten Spalte notiert. Im Fall einer nicht messwiederholten Variable enthält diese Spalte stattdessen den Kontext der Werte.
Im Allgemeinen hat das Wide-Format mehr Spalten als das Long-Format, welches dafür mehr Zeilen besitzt. Die Darstellung im Wide-Format ist übersichtlicher, insbesondere wenn viele messwiederholte Variablen vorliegen. Die Anzahl der Spalten bleibt meistens noch überschaubar. Ausserdem befinden sich alle Variablen einer Untersuchungseinheit in derselben Zeile, wodurch man leichter Unstimmigkeiten und fehlende Daten entdeckt. Man vergisst bei der Dateneingabe in den Computer auch nicht so leicht Daten. Dagegen enthält die Datenmatrix im Long-Format oft besonders viele Zeilen, was dieses Format weniger leserlich macht.
Wir empfehlen Ihnen also, die Daten im Wide-Format einzugeben, bevor sie die Excel Daten importieren. Wenn Sie in SPSS Daten importieren, können Sie diese ins Long-Format transformieren. Es besteht also kein Grund dafür, die Daten gleich im Long-Format abzutippen. Im folgenden Abschnitt erzeugen wir anhand eines fiktiven Beispiels mit der Statistik-Software R Daten im Wide-Format, um sie anschliessend ins Long-Format zu transformieren.
Vom Wide-Format zum Long-Format
Ein Ernährungswissenschaftler möchte eine neue Diätmethode testen. Hierfür nehmen 10 übergewichtige Personen, davon 5 Frauen und 5 Männer, an einer Studie teil. Die Probanden werden unmittelbar vor Beginn (Gewicht.1) und nach Ende (Gewicht.2) der Diät gewogen, um eine Gewichtsreduktion durch die Diät feststellen zu können. Ausserdem wird das Gewicht ein Jahr später (Gewicht.3) erneut gemessen, um den langfristigen Erfolg der Diät zu überprüfen. Das Gewicht erscheint als messwiederholte Variable in mehreren Spalten im Gegensatz zum Geschlecht, welches bei jedem Probanden nur einmal gemessen wird.
# R-Programm-Code zur Erstellung des Datensatzes im Wide-Format und Export zu Latex:
library ( xtable ) # optional; braucht man nur für Latex bzw. Lyx!
set.seed ( 42 )
datensatz.wide = data.frame(Probandennummer=1:10,Geschlecht=c(rep(“w”,5),rep(“m”,5)) ,
Gewicht.1 = rnorm(10,150,10),Gewicht.2=rnorm(10,140,10),Gewicht.3=rnorm(10,135,10) )
View ( datensatz.wide )
xtable ( datensatz.wide,caption=”Wide-Format”,digits=1,align=c(“c|”,”c”,”c”,”c”,”c”,”c”) )

So anschaulich das wide-Format auch ist, manche statistischen Verfahren wie zum Beispiel die Varianzanalyse mit Messwiederholung aus dem R-Paket ez benötigen eine Darstellung im Long-Format. Im Wide-Format wird für jeden Zeitpunkt einer messwiederholten Variable eine eigene Spalte im Datensatz angelegt. Dagegen werden im Long-Format sämtliche Messwerte des Gewichts für die drei Zeitpunkte in einer einzigen Spalte untergebracht. Damit die Information über den Zeitpunkt nicht verloren geht, wird entsprechend eine neue Variable erstellt.

# R-Programm-Code zur Transformation vom Wide -ins Long-Format und Export zu Latex:
datensatz.long = reshape ( datensatz.wide , idvar = ”Probandennummer” ,
varying = c(“Gewicht.1″,”Gewicht.2”,“Gewicht.3″), v.names = „Gewicht“ ,
timevar = ”Zeitpunkt” , sep = ”.” , direction = ”long” )
View ( datensatz.long )
xtable ( datensatz.long,caption=”Long-Format”,digits=1,align=c(“c|”,”c”,”c”,”c”,”c”) )
Die Transformation vom Wide- ins Long-Format geschieht in R mit dem reshape-Befehl. Das erste Argument der Funktion ist der zu umstruktierende Datensatz, in diesem Fall datensatz.wide. Idvar ist die Variable, welche die Probanden eindeutig kennzeichnet, in diesem Fall mit den Nummern 1 bis 10. varying gibt die messwiederholte Variable Gewicht inklusive der Bezeichnung für den Zeitpunkt an. Der Messzeitpunkt ist von der Variablenbezeichnung durch einen Punkt getrennt, sodass sich die drei einzelnen Variablen im Wide-Format als Vektor c(“Gewicht.1″,”Gewicht.2″,”Gewicht.3”) ergeben. Weil in diesem Fall ein Punkt zur Trennung verwendet wurde, wird das im Argument sep = ”.” notiert. Bei einem Leerzeichen wie bei Gewicht1 würde man stattdessen sep = ”” schreiben. Die messwiederholte Variablenbezeichnung ohne Messzeitpunkt wird bei v.names eingetragen. Im Long-Format wird eine neue Variable erstellt, damit eindeutig ist, zu welchem Zeitpunkt die messwiederholte Variable gemessen wurde. Eine Variablenbezeichnung hierfür kann unter timevar vergeben werden. Schliesslich wird noch mit direction die Richtung der Transformation angegeben, in diesem Fall in ein Long-Format.
Zusammenfassung: Das Long-Format richtig einsetzen
Wir hoffen, dass Ihnen unser Artikel die Themen Dateneingabe und das Prinzip des Wide-Formats näher bringen konnte. Nachdem wir zu Beginn des Artikels die SPSS Dateneingabe beschrieben und die Vorteile und Nachteile der beiden Formate hervorgehoben haben, sollten Sie nun auf Basis unserer Ausführungen in R oder SPSS Excel Daten importieren und im Wide-Format in SPSS Daten importieren können. Weiterhin sollten Sie auf Basis unserer obigen Anleitung fähig sein, nach dem Import von Excel in SPSS bzw. R oder nach der Dateneingabe SPSS dazu zu nutzen, die Daten vom Wide- ins Long-Format zu bringen. Dieses eignet sich besonders für die Analyse von Zeitverläufen oder beispielsweise für die Überprüfung der Mitarbeiterentwicklung im Rahmen einer kontinuierlichen Mitarbeiterbefragung. Für weitere Fragen oder ein tiefergehende Beratung zu diesem Thema stehen Ihnen die professionellen Statistiker von Novustat Ihnen jederzeit zur Verfügung.
Schritt 2: Variablen umbenennen und Beschriftungen anlegen
Der nächste Schritt der Datenaufbereitung ist das Benennen und Beschriften Ihrer Variablen. Klar benannte Variablen verhindern Verwirrung beim Auffinden von Variablen und erleichtert das spätere Datenmanagement. SPSS bietet dabei zwei Möglichkeiten Variablen zu identifizieren:
| Name | Ein möglichst kurzer und bündiger Name sollte eine Variable eindeutig identifizieren. |
| Beschriftung | Mit der Beschreibung können Sie die Variable vollständig beschreiben. Eine eindeutige Beschreibung von Variablen ist wichtig, damit Sie und andere sich schnell im Datensatz zurechtfinden. Für die Auswertung von Fragebögen können Sie hier häufig die Frage im Wortlaut oder eine sinngemässe Zusammenfassung verwenden. |

Zur Bearbeitung der Namen und Beschriftungen Ihrer Variablen schalten Sie auf die Variablensicht (Schaltfläche unten links). Namen und Beschriftung der Variablen können Sie dann mit Klick auf die jeweiligen Spalten bearbeiten.

Schritt 3: Fehlende Werte definieren
Ein nächster wichtiger Schritt bei der Datenaufbereitung und Datenbereinigung ist der Umgang mit fehlenden Werten. SPSS kennt zwei Arten von fehlenden Werten:
- Systembedingt fehlenden Werte: Dies sind „leere“ Datenfelder in Ihrem Datensatz. Diese Zellen werden von SPSS automatisch als fehlende Werte erkannt.
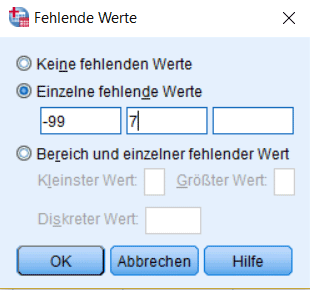
- Benutzerdefinierten fehlenden Werte: Fehlende Werte die durch einen numerischen Code gekennzeichnet sind (z.B. „-99“)
Benutzerdefinierte Werte sind bei der Auswertung von Fragebögen z.B. dann sinnvoll, wenn Probanden mit „weiss nicht“, „nicht zutreffend“ oder „möchte hierauf nicht antworten“ auf eine Frage geantwortet haben. Diese Werte sollten natürlich nicht in die Analyse einfliessen. Als benutzerdefinierte fehlende Werte können Sie diese von der Analyse ausschliessen, aber trotzdem für das Datenmanagement von „gewöhnlichen“ fehlenden Werten unterscheiden.
Fehlende Werte können für jede Variable in der Variablenansicht festgelegt werden. Klicken Sie hierzu auf den entsprechenden Eintrag in der Spalte „Fehlend“.

Schritt 4: Korrekte Variablen-Formate festlegen
Wenn Sie die Variablentypen nicht korrekt definieren, kann die Analyse später nicht korrekt ausgeführt werden. Den Variablentyp für jede Variable können Sie in der Variablenansicht bei Klick auf die Spalte „Typ“ festlegen. Die wichtigsten Typen sind numerisch, Zeichenfolge und Datum. Für gewöhnlich erkennt SPSS den Variablentyp automatisch korrekt, aber insbesondere bei Variablen mit Datum ist es gelegentlich nötig den Typen manuell zu korrigieren.
Schritt 5: Numerische Codes für kategorische Variablen
Am Ende der Datenaufbereitung sollten alle Ihre kategorischen Variablen in numerischer Form vorliegen. Sonst können Sie diese Variablen nicht in der Analyse mit einbeziehen.
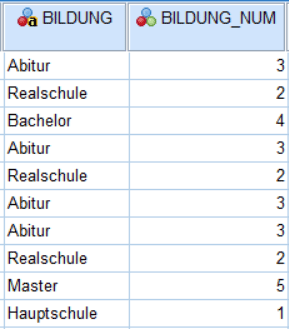
Wenn manche Ihrer kategorischen Variablen die Kategorien als Zeichenfolge enthalten, müssen Sie diese erst noch in die numerische Form umwandeln. Dies erledigen Sie ganz einfach mit dem „automatisch umcodieren“-Befehl (zu finden im Menüpunkt „Transformieren“).
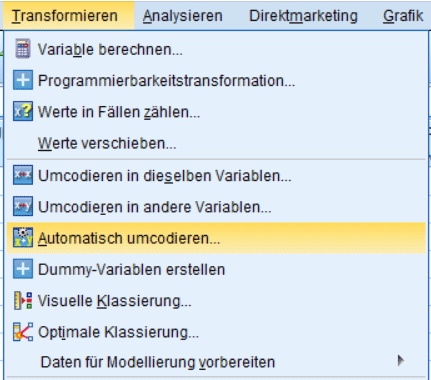
Im folgenden Menü müssen Sie alle kategorischen Variablen mit Zeichenfolgen dem Fenster rechts hinzufügen. Für jede dieser Variable müssen Sie dann einen Namen für die neue umcodierte Variable festlegen. Setzen Sie dann einen Haken für „leere Zeichenfolgewerte als benutzerdefiniert fehlend behandeln“. Die restlichen Voreinstellungen können Sie so übernehmen.
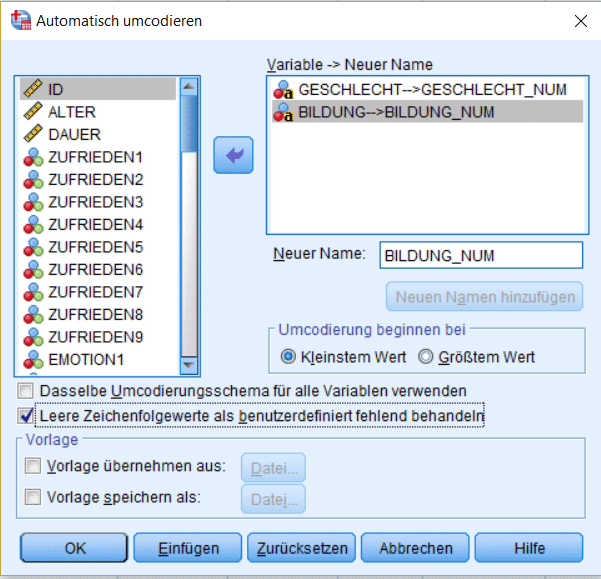
Schritt 6: Variablencodes für kategorische Variablen beschriften
Ihre kategorischen Variablen sollten nun in numerischer Form vorliegen. Damit aber die Bedeutung der Codes eindeutig dokumentiert ist, sollten Sie nun Ihre Variablencodes beschriften. Ansonsten kann die Bedeutung der numerischen Codes später unklar sein. Dies können Sie mit einem Klick auf die Spalte „Werte“ in der Variablenansicht tun.

Fügen Sie dann für alle Werte der Variablen eine Beschriftung hinzu.
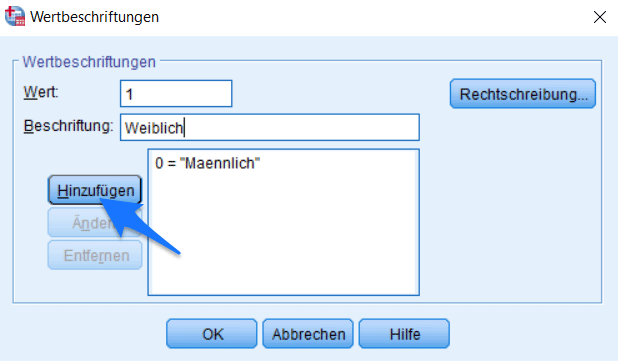
Schritt 7: In SPSS Daten importieren – Datensatz abspeichern
Sie haben nun Ihre Rohdaten erfolgreich aufbereitet und für die Analyse vorbereitet. Wir empfehlen Ihnen, Ihre Rohdaten nicht zu überschreiben. Somit können Sie Ihre Arbeitsschritte immer rückgängig machen. Speichern Sie Ihren aufbereiteten Datensatz daher am besten in einer eigenen Datei ab.
In SPSS Daten importieren: Fazit
Sie kennen nun die notwendigen Schritte um Daten für die Auswertung von Fragebögen in SPSS aufzubereiten. Sie können nun SPSS Daten importieren und diese für die Analyse vorbereiten. Sorgfältige Datenaufbereitung ist essenziell für gutes Datenmanagement und führt zu einer enormen Zeit- und Arbeitsersparnis während der Analyse. Für weitere Fragen oder einer tiefergehenden Beratung zu Datenmanagement stehen Ihnen die Experten von Novustat selbstverständlich jederzeit zur Verfügung.
Zum Schluss möchten wir Ihnen noch eine Checkliste mit auf den Weg geben, mit der Sie kontrollieren können, ob sie alle Schritte für die Datenaufbereitung erledigt haben.
| ☐ | Alle Daten wurden erfolgreich eingelesen |
| ☐ | Alle Variablen eindeutig benannt und beschriftet |
| ☐ | Benutzerdefinierte fehlenden Werte definiert (wo notwendig) |
| ☐ | Alle Variablentypen korrekt eingestellt |
| ☐ | Alle kategorischen Variablen sind numerisch codiert |
| ☐ | Alle Variablencodes sind beschriftet |
| ☐ | Aufbereiteter Datensatz abgespeichert in eigener Datei |
Weiterführende Quellen
Data Cleaning: Detecting, Diagnosing, and Editing Data Abnormalities
https://library.virginia.edu/data/reshaping-data-from-wide-to-long/
https://statistik-dresden.de/datenaufbereitung-fur-abhangige-stichproben-long-und-wide-format/