
In einem früheren Beitrag haben wir gezeigt, wie sich Daten für eine Panelstudie in Stata einfach und schnell aufbereiten. Im Vergleich zu Stata verfügt SPSS über eine deutlich aufwändigere Syntax-Sprache: Daher wird das Programm wird von vielen besonders im Bereich der Datenaufbereitung als umständlich und wenig nutzerfreundlich empfunden. Mit diesem Beitrag wollen wir einige grundlegende SPSS-Funktionen präsentieren, die die Aufbereitung einer Panelstudie in SPSS ermöglichen. Dadurch lassen sich unnötige Wechsel zwischen Statistikprogrammen für einzelne Schritte bei Paneluntersuchungen vermeiden.
Sie benötigen Unterstützung bei der Datenaufbereitung in SPSS oder einem anderen Statistikprogramm? Wenden sie sich hierzu an uns und unsere Experten für eine Statistik Beratung!
Zur Wiederholung: Was ist ein Panel?
Die Daten für eine Panelstudie beinhalten für jede Erhebungseinheit (zum Beispiel Personen oder Haushalte) mehrere Messungen zu unterschiedlichen Messzeitpunkten. Tipps, wie Paneldaten in Stata einfach aufzubereiten sind, haben wir bereits beschrieben.
Die Analyseeinheiten bei der Arbeit im Panel Design sind nicht diejenigen, an denen die Messung vorgenommen wird (Merkmalsträger), sondern die einzelnen wiederholten Messungen. Aus diesem Grund eignet sich das sogenannte wide-Datenformat nur bedingt für die Arbeit mit Paneldaten, da es nur eine Zeile pro Merkmalsträger mit verschiedenen Messungen als eigene Variable enthält.
Besser ist es, diese im long-Datenformat organisieren. Hier gibt es dann nur eine gemeinsame Variable für die Messwerte und jede Messung bildet eine eigene Zeile.

Die Datenumstrukturierung von wide- zu long-Format kann direkt in SPSS durchgeführt werden. Entweder manuell unter „Daten“ –> „Umstrukturieren“ –> „Umstrukturieren ausgewählter Variablen in Fälle“.
Oder per folgender Syntax:
VARSTOCASES
/MAKE messung FROM messung2009 messung2010 messung2011 messung2012 messung2013
/INDEX = index.
Aus einzelnen Variablen, die die Messungen zu unterschiedlichen Messzeitpunkten beinhalten, bilden wir Zeilen innerhalb der neuen Variable „messung“ und machen die einzelnen Zeitpunkte durch eine Index-Variable kenntlich.
Anders als zum Beispiel bei Stata übernimmt SPSS hier nicht die Nummerierung, die in den ursprünglichen Variablennamen beinhaltet war – in unserem Beispiel die Jahre -, sondern nummeriert die Messzeitpunkte lediglich durch.
Wir können das jedoch leicht wie folgt anpassen:
IF index=1 jahr=2009.
IF index=2 jahr=2010.
IF index=3 jahr=2011.
IF index=4 jahr=2012.
IF index=5 jahr=2013.
EXECUTE.
**Variable “Jahr” bilden**
FORMATS jahr(f4).
**Keine Nachkommastellen**
DELETE VARIABLES index.
**Alte Index-Variable löschen**
Das Ergebnis sieht nun so aus:
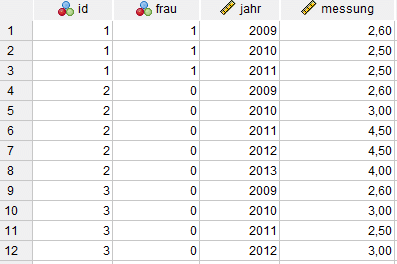
Panelstudie und Paneldaten in SPSS
Ein Paneldatensatz hat zwei unabdingbare Informationen:
- eindeutige Merkmalsträger-ID (hier id)
- die Angabe des Zeitpunkts, die sich ordinal ordnen lässt (Hierarchie, hier: Jahr)
Typische Datenbearbeitungsschritte im Rahmen einer Panelstudie nehmen Bezug auf diese zwei Informationen. Daher Achtung: auf keinen Fall löschen!
Sollte eine ID-Variable in dem Originaldatensatz fehlen, kann sie beim Durchführen des VARSTOCASES-Befehls gebildet werden.
Nachfolgend stellen wir dazu 3 Lösungsansätze vor:
Lösung 1: Anträge pro Person zählen und durchnummerieren
Wir nehmen an, für unsere Panelstudie haben wir Messungen aus unterschiedlichen Jahren. Einige Personen haben dabei nicht in allen Jahren an der Untersuchung teilgenommen (die Jahre mit den fehlenden Angaben werden bei der Umstrukturierung des Datensatzes automatisch ausgelassen).
Nun wollen wir zählen, wie viele Anträge es pro Person gibt und anschliessend diese durchnummerieren. Für das Zählen der Zeilen pro Merkmalsträger benutzen wir den AGGREGATE-Befehl. Dieser kann bei Bedarf auch gruppenspezifische Parameter, z.B. Mittelwerte, berechnen.
AGGREGATE
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=id
/index_total=N.
Das Durchnummerieren der Zeilen ist etwas komplizierter. SPSS enthält zwar die Funktion $CASENUM für die Berechnungen der Variablen, diese kann jedoch nicht ohne Weiteres gruppenspezifisch angewandt werden.
Wir machen Gebrauch von der Funktion LAG, die immer die vorherige Zeile adressiert, und berechnen die Index-Variable mit einem kleinen Trick:
SORT CASES BY id jahr.
COMPUTE index = 1.
IF id = LAG(id) index = LAG(index) + 1.
EXECUTE.
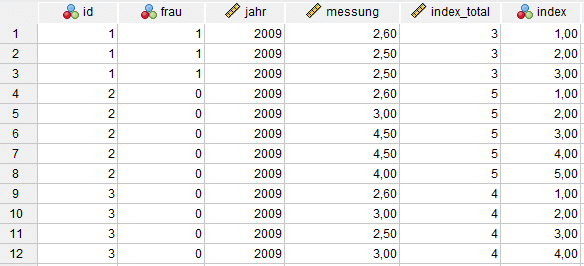
Die gewünschten Informationen sind nun als zusätzliche Variablen hinterlegt. Die SPSS-Funktion, die die nächste Zeile adressiert, lautet übrigens LEAD.
Lösung 2: Zeilen bei Variablenberechnung konkret adressieren
Die Möglichkeit, bestimmte Zeilen in einem Befehl direkt zu adressieren, sind besonders bei der Berechnung von Variablen mit Zeitbezug sehr hilfreich. So kann man damit zum Beispiel sogenannte Delta-Werte bilden, also die Differenz zum vorangehenden Zeitpunkt.
Dafür greifen wir auf den Variablenwert in der Zeile, die sich eins über (=zeitlich früher) der aktuellen Zeile befindet. Die erste Messung bei einer Person müsste dabei logischerweise ein fehlender Wert sein:
COMPUTE lag_messung = lag(messung).
IF index= 1 lag_messung =$SYSMIS.
COMPUTE delta_messung=messung - lag_messung.
EXECUTE.
DELETE VARIABLES lag_messung.
Manchmal will man aber auch wissen, wie sich der Wert im Vergleich zum Ausgangszeitpunkt verändert hat. Dabei hilft wieder der AGGREGATE-Befehl.
Eine der zahlreichen Funktionen erlaubt es, den Wert der ersten Zeile einer Gruppe (bzw. eines Merkmalsträgers) zu identifizieren, den wir dann für weitere Berechnungen verwenden:
AGGREGATE
/OUTFILE=* MODE=ADDVARIABLES
/BREAK=id
/messung_erste=FIRST(messung).
COMPUTE diff_start_messung=messung - messung_erste.
EXECUTE.
DELETE VARIABLES messung_erste.
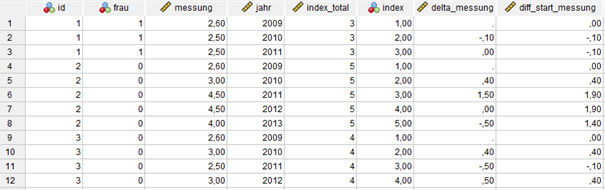
Lösung 3: Doppelungen bereinigen
Manchmal kommt es bei einer Panelstudie beim Zusammenführen von komplexen Datensätzen zu Doppelungen, zum Beispiel wenn bei Personen dieselben Messungen (zu denselben Jahren) mehrmals vorkommen.
Um solche Fälle zu identifizieren, ist der Befehl MATCH FILES nützlich. Eigentlich ist er für das Zusammenführen mehrerer Datensätze gedacht, bietet aber eine Reihe an Funktionen, die man auch sinnvoll in einem Datensatz nutzen kann. So kann beispielsweise die erste Zeile innerhalb einer Gruppe eindeutig gekennzeichnet werden. Nun suchen wir die erste gültige Zeile, und zwar nicht pro Merkmalsträger, sondern pro Merkmalsträger-Jahr. In einem „sauberen“ Datensatz sollte es auch eine einzelne sein. Ist das nicht der Fall, löschen wir alle anderen:
MATCH FILES
/FILE=*
/BY id jahr
/FIRST=id_jahr_first.
SELECT IF id_jahr_first=1.
EXECUTE.
Panelstudie: Fazit
Zusammenfassend lässt sich eine Datenanalyse mit SPSS, Stata, R in unterschiedlicher Weise durchführen. Die Antwort auf die Frage, für welches der Statistikprogramme im Vergleich entscheide ich mich, obliegt freilich immer den Nutzenden.
Wenn Sie sich bei einer Panelstudie für SPSS entscheiden, haben wir Ihnen hier einige Tippe und Tricks vorgestellt.Weil Daten in SPSS üblicherweise mit dem im wide-Format organisiert sind, ist der Umstieg auf long-Format für viele zu Beginn schwierig.
Meistens weiss man nicht, wie man sich zwischen den einzelnen Zeilen anstatt der Variablen bewegen kann. Mit LAG- und LEAD-Funktionen sowie AGGREGATE- und MATCH FILE-Befehlen ist das jedoch auch in SPSS sehr leicht möglich.
Dieser Beitrag hat gezeigt, dass SPSS auch im Bereich der Datenaufbereitung einer Panelstudie deutlich mehr kann, als es auf den ersten Blick erscheint. Die entsprechenden Lösungen wollen nur entdeckt werden.
Sollten Sie Bedarf an einer professionellen Hilfeleistung bei der Arbeit mit SPSS haben, zögern Sie nicht und kontaktieren Sie uns! Nutzen Sie dazu gleich und unverbindlich unser schriftliches Kontaktformular!