
Paneldaten sind häufig Thema bei statistischen Datenanalysen. Allerdings stossen wir hier an komplexe Anforderungen im Rahmen der Datenaufbereitung. Das Format, in dem Daten im Panel Design üblicherweise organisiert sind, enthält die notwendigen Informationen nicht (wie zumeist gewohnt) reihenweise, sondern spaltenweise. Mit Spalten zu arbeiten, erfordert jedoch ein weitergehende (Programmier)Kenntnisse im jeweiligen Statistik-Programm. Mit diesem Beitrag wollen wir anhand von Stata zeigen, dass die dafür notwendigen Lösungsschritte schnell erlernt werden können. Und konkrete Beispiele machen deutlich, dass es sich auch lohnt.
Sie benötigen Unterstützung bei der Datenaufbereitung in Stata oder einem anderen Programm? Wenden sie sich hierzu an uns und unsere Expertinnen und Experten für eine Statistik Beratung! Auch im Bezug auf anderen Themen können Sie von unserer professionellen Stata Hilfe profitieren.
Was ist ein Panel?
In mehreren Beiträgen haben wir bereits gezeigt, wie man mit Paneldaten arbeitet, zum Beispiel bei gemischten Modellen und ANOVA mit Messwiederholung. Was ist nun aber ein Panel konkret? – Kurzum, Paneldaten beinhalten für jede Erhebungseinheit (zum Beispiel Personen) mehrere Messungen zu unterschiedlichen Messzeitpunkten. Somit unterscheiden sie sich auch wie folgt von anderen Datenformaten:
- Gepoolter Querschnitt enthält nur eine Messung pro Erhebungseinheit, Einzelanträge stammen aber aus unterschiedlichen Messzeitpunkten.
- Mehrebenendaten enthalten mehrere Messungen pro Erhebungseinheit. Daten im Panel Design sind somit automatisch Mehrebenendaten, die Messungen sind aber hier zeitlich geordnet. Diese Ordnung gibt es z.B. bei regionalen Mehrebenendaten nicht.
- Reine Zeitreihen beinhalten Messungen zu mehreren Messzeitpunkten, jedoch nur zu einer Erhebungseinheit.
Paneldaten enthalten somit sowohl einen Querschnittsbezug als auch einen zeitlichen Bezug. Die Analysebasis ist dabei nicht die Person, sondern die Messung. Die statistischen Programme folgen gemeinhin der Logik, dass die Daten auf der Analyseebene organisiert sind.
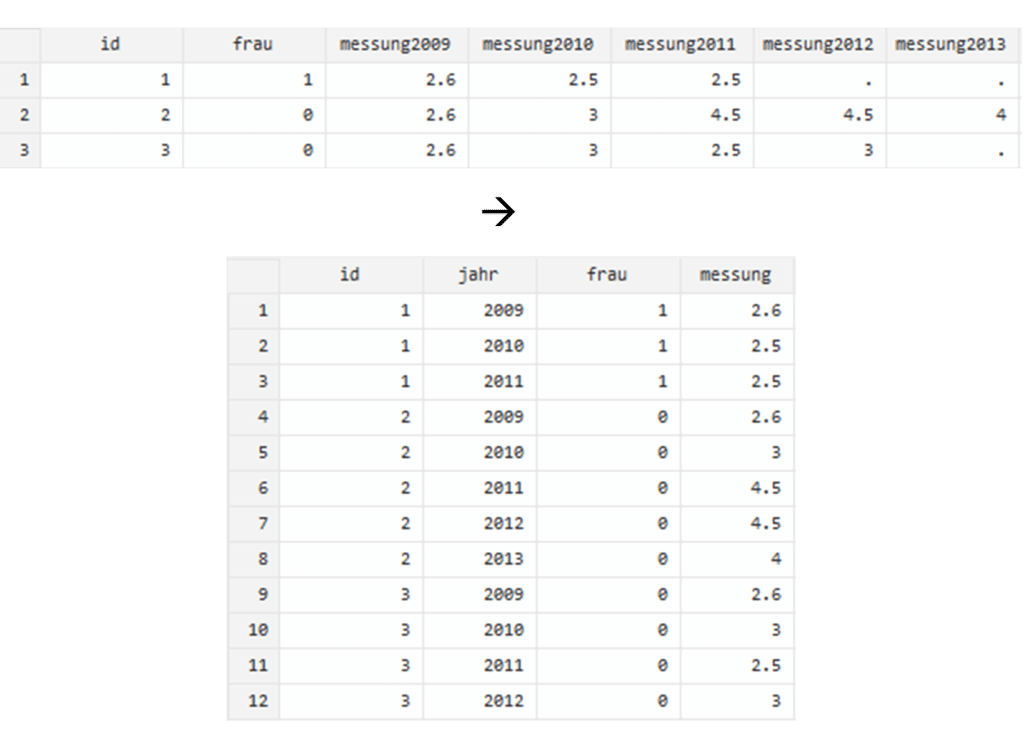
Das bekannte wide-Datenformat, das nur eine Zeile pro Person mit verschiedenen Messungen als eigenen Variablen enthält, eignet sich daher nur bedingt für die Arbeit mit Paneldaten. Diese sollte man am besten im long-Datenformat organisieren. Hier gibt es nur eine gemeinsame Variable für die Messwerte und jede Messung pro Person bildet eine eigene Zeile.
Somit hat jede Person (gekennzeichnet mit jeweils einer eindeutigen ID) eine eigene Spalte an Messwerten. Umsetzung und Vorteile des Long-Datenformats haben wir bereits in einem eigenen Beitrag zu SPSS Dateneingabe im Long Format erklärt.
Im Programm Stata nutzen wir den reshape-Befehl, um die beiden Datenformate ineinander überzuführen, wie nachfolgendes Beispiel zeigt:
reshape long messung, i(id) j(jahr)
drop if messung==.
Arbeit mit Paneldaten in Stata: _N, _n, bys
Stata hinterlegt und aktualisiert laufend sogenannte Systemvariablen (immer beginnend mit einem Unterstrich). So kann man mit _b[VAR] immer auf den Koeffizienten der Variable VAR aus dem jeweils letzten Modell zurückgreifen.
Für das Datenmanagement sind aber die Systemvariablen _N und _n wichtig. Die erstere zählt die Zeilen im Datensatz, während die zweite diese durchnummeriert. In Bezug auf die Gesamtdaten scheint diese Information überflüssig zu sein.
Allerdings kann man mit dem Befehl by sort (oder abgekürzt: bys) einen neuen Bezug vorgeben und die Zeilen innerhalb von Personen getrennt ansprechen. Das erleichtert die Arbeit mit den Paneldaten wesentlich.
Das zeigen wir anhand von drei Beispiel-Lösungen:
Lösung 1: Anträge pro Person zählen und durchnummerieren
Nehmen wir an, wir haben Messungen aus mehreren aufeinanderfolgenden Jahren. Einige Personen haben dabei nicht in allen Jahren an der Untersuchung teilgenommen. Nun wollen wir zählen, wie viele Messungen es pro Person gibt und anschliessend diese durchnummerieren.
Wichtig hierbei ist, dass die Messungen pro Person in zeitlich korrekter Reihenfolge (aufsteigend) geordnet sind. Also sortieren wir den Datensatz nach Personen-ID und Jahren oder bauen diese Bedingung in den Befehl mit ein (einfaches Sortieren, ohne den Bezug herzustellen in Klammern).
bys id (jahr): gen index=_N
bys id (jahr): gen zeile=_n
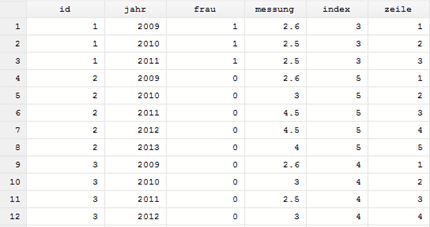
Die gewünschten Informationen sind nun als zusätzliche Variablen hinterlegt.
Lösung 2: Doppelungen bereinigen
Manchmal kommt es beim Zusammenführen von komplexen Datensätzen zu Doppelungen, zum Beispiel wenn bei Personen dieselben Messungen (zu denselben Jahren) mehrmals vorkommen.
Wir könnten dann die Zeilen pro Person-Jahr durchzählen. Hier wird auch das Jahr ein Teil des Bezugs und wir nutzen keine Klammern:
bys id jahr: gen index_jahr=_N
tab index_jahr
Folglich sollte bei keiner Person ein einzelnes Jahr mehr als einmal vorkommen, also index_jahr den Wert von grösser 1 haben. Passiert das, würden wir nur eine Zeile pro Jahr behalten wollen.
Dies kann entweder die erste Zeile sein:
bys id jahr: keep if _n==1oder die letzte Zeile:
bys id jahr: keep if _n==_NLösung 3: bestimmte Zeilen bei Variablenberechnung adressieren
Die Möglichkeit, bestimmte Zeilen in einem Befehl direkt zu adressieren, ist besonders bei der Berechnung von Variablen mit Zeitbezug sehr hilfreich. So kann man damit zum Beispiel sogenannte Delta-Werte bilden, also die Differenz zum vorangehenden Zeitpunkt. Dafür greifen wir auf den Variablenwert in der Zeile, die sich 1 über (=zeitlich früher) der aktuellen Zeile befindet, also _n-1:
bys id (jahr): gen delta_messung = messung- messung[_n-1]Wollen wir beispielsweise wissen, wie sich der Wert im Vergleich zum Ausgangszeitpunkt verändert hat, kann man auch explizit die Differenz zu einer festen Zeile, hier der ersten [1], berechnen:
bys id (jahr): gen diff_start_messung = messung- messung[1]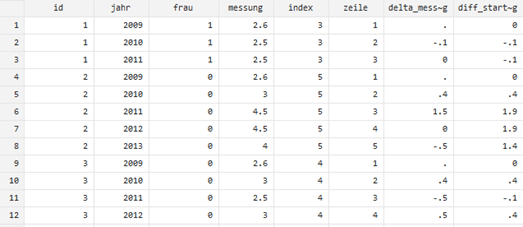
Übrigens lassen sich damit auch Lücken in den Daten finden. Bildet man den Delta-Wert für die Jahre, so sollte er nicht grösser als 1 sein. Wir können sogar eine Indikatorvariable berechnen, die uns die Lücke im Datensatz anzeigt:
bys id (jahr): gen delta_jahr = jahr- jahr[_n-1]
gen gap=0
replace gap=1 if delta_jahr !=1
Fazit
Paneldaten werden üblicherweise im long-Datenformat analysiert, um den korrekten Bezug zu den Untersuchungseinheiten zu erhalten, die bei den Panelanalysen immer die einzelne Messung ist.
Da Statistikprogramme üblicherweise den Zugang über im wide-Datenformat organisierte Daten nutzen, ist der Umstieg auf das Long-Format mitunter ungewohnt und herausfordernd. Und zwar deshalb, weil wir uns im Rahmen der Analyse hier auf der Ebene der einzelnen Zeilen bewegen und nicht primär auf der Variablenebene.
Das Statistikprogramm Stata bietet dafür eine breite Palette an leicht umsetzbaren und intuitiven Lösungen an. Mit diesem Beitrag haben wir einige wichtige Funktionen und Lösungsansätze präsentiert. Für eine professionelle Unterstützung bei der Arbeit mit Stata kontaktieren Sie uns unverbindlich über unser schriftliches Kontaktformular!