

“With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.” (Nature 427). John von Neumann spielt mit diesem Spruch darauf an, dass man mit genügend Parameter und einem komplexen Modell jede Art von Daten genau beschreiben kann. Und genau darin liegt das Problem bei statistischer Modellierung. Ein Modell soll nicht nur die Daten gut beschreiben, es muss auch übertragbar und anwendbar bleiben. Beschreibt das Modell die erhobenen Daten in jeder Einzelheit, dann ist meist keine Verallgemeinerung auf die Realität möglich. Dieser Effekt wird als Overfitting bezeichnet. Overfitting ist insbesondere im Data Mining (Overfitting Machine Learning und Overfitting Neural Network) und bei Regressionsmodellen ein häufiges Problem. Underfitting bezeichnet dahingegen Modelle, die weder Daten noch die Realität genau genug beschreiben.
Im Folgenden geben wir Ihnen einen Einblick in die komplexen Prozesse der Modellbildung. Wir erklären zuerst, was Overfitting und Underfitting bedeutet. Unsere Experten geben anschliessend Tipps, wie Overfitting vermieden werden kann.
Overfitting ist ein tief greifendes Problem. Unsere Statistik-Beratung unterstützt Sie gerne individuell. Unsere Experten stehen hierfür zur Verfügung. Nehmen Sie Kontakt mit uns auf! Wir freuen uns auf Ihre Problemstellung.
Diesem Artikel beantwortet folgende Fragen zu Overfitting:
- Modellbildung: Was ist zu beachten?
- Was versteht man unter einer Generalisierung?
- Was versteht man unter Overfitting?
- Welche Masszahlen gibt es zur Beurteilung von Overfitting?
- Gibt es auch Underfitting?
- Beispiel Big Data: Was bedeutet Overfitting Machine Learning?
- Vermeidung Overfitting Neural Network – Welche Tipps gibt es?
Statistische Modellierung
Das Ziel vieler statistischer Auswertungen besteht darin, mit Modellen die Wirklichkeit zu beschreiben. Die Modelle sollen sowohl einfach verständlich und anwendbar sein. Auf der anderen Seite sollen die Modelle natürlich auch die Wirklichkeit möglichst gut beschreiben.
Diese Aufgabe vernünftig und zielführend zu lösen, ist bei jeder Fragestellung eine neue, fordernde Aufgabe, die einzig in den Händen des Statistikers liegt.
Die Bildung eines vernünftigen, sinnvoll anwendbaren Modells ist mit der Arbeit eines Schneiders vergleichbar: Der Schneider versucht, mit Stoff ein gut passendes, adäquates Outfit zu erzeugen. Genauso versucht man in der Modellbildung, die Daten mit einem gut passenden, adäquaten Modell „auszustatten“ – zu „fitten“.
Generalisierung im Machine Learning
Bei Kleidung ist durch eine Anprobe leicht zu überprüfen, ob ein gewünschtes Kleidungsstück passt. Um zu beurteilen, wie gut ein statistisches Modell die Daten beschreibt (Performance), gibt es eine Vielzahl von Masszahlen zur Modellgüte. Anhand dieser Masszahlen lassen sich Aussagen machen, wie gut das Modell die Daten beschreibt.
Auch in der Entwicklung von Kleidung ist es wichtig, dass die entworfene Kleidung möglichst vielen Kunden passt. Konfektionskleidung soll nicht nur den (Mass-)Modellen passen, anhand deren die Masse genommen wurden. Die Kleidung soll allen potenziellen Kunden passen!
Ebenso soll ein statistisches Modell nicht nur die beobachtete Stichprobe gut beschreiben. Es muss auch gut anwendbar sein für unbekannte, neue Daten (Prognose). Um diese Übertragbarkeit des Modells zu beurteilen, werden Validierungsverfahren eingesetzt.
Validierungsverfahren, z.B. Kreuzvalidierung oder x-fach Validierung finden im Data Mining vielfach Anwendung. Dabei wird der gesamte Datensatz in Trainingsdaten und Testdaten aufgeteilt. Die Trainingsdaten verwendet man zur Entwicklung eines Modells . Das geschätzte Modell wendet man anschliessend auf den Testdatensatz an. Somit kann man schliesslich die Performance des Modells beurteilen.
Mithilfe der Validierungsverfahren lassen sich Aussagen machen, wie gut das Modell mit unbekannten Daten aus der gleichen Grundgesamtheit zu Recht kommt. Dieses Konzept nennt man Generalisierung: Die Übertragung statistischer Modelle auf reale Daten.
Bei der Generalisierung gibt es zwei schwerwiegende Problem: Underfitting und Overfitting.
Underfitting
Um passende Kleidung für möglichst viele Kunden zu schneidern, kommt ein Schneider auf die Idee, zeltähnliche Umhänge zu produzieren. Dieses Kleidungsstück passt allen Leuten, ob gross, ob klein, dick oder dünn. Die Passform ist allerdings für alle Kunden sehr schlecht: Bei schlanken Leute flattert das Zelt, beleibte Menschen habe nicht genug Bewegungsfreiheit. Das Kleidungsstück unterstreicht in keiner Weise die körperlichen Eigenheiten der potenziellen Kunden. Dieses Vorgehen bezeichnet man als Underfitting: Ein Modell bzw. Kleidungsstück, das einfach und universell anwendbar ist, allerdings alle Daten bzw. Kunden nur unzureichend beschreibt oder „fitted“.
Im statistischen Kontext beschreibt Underfitting, dass die Einflussvariablen die Zielvariable nicht hinreichend gut beschreiben. Das statistische Modell für die Beschreibung der Daten ist zu einfach (z.B. lineares Modell, nur eine Einflussvariable). Das Modell sagt die Zielvariable dann nicht gut genug vorher. Die Masszahlen für die Modellgüte sind zu niedrig. Die Modellgüte erreicht keine hinreichend hohen Werte. Sinnvolle Vorhersagen sind somit nicht durchführbar.
Hierfür gibt es meist zwei wesentliche Gründe:
- Das Modell, d.h. der funktionale Zusammenhang bzw. im Data Mining der gewählte Algorithmus passt nicht.
- Wesentliche Einflussfaktoren wurden nicht berücksichtigt.
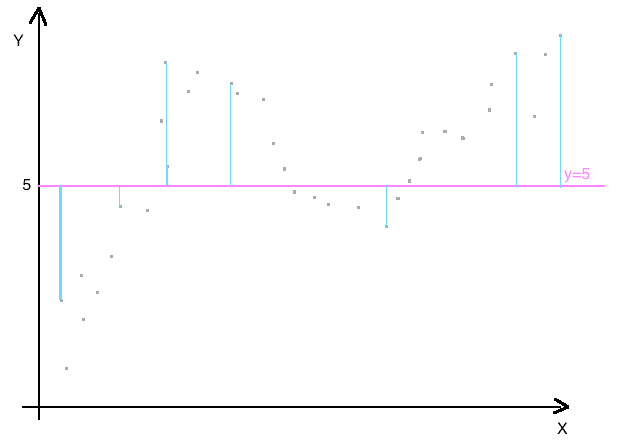
Overfitting
Das zweite Problem bei der Herstellung von Konfektionskleidung besteht darin, dass die Kleidung zu sehr an die Probanden angepasst ist, anhand derer im Atelier Mass genommen wurde. Die Kleidung passt perfekt für die Probanden und unterstreicht perfekt die Körperform der vermessenen Personen. Schlüpft eine andere Person in diese Kleidung, wird sie hier zu eng sein und dort zu weit, insgesamt also einer anderen Person nicht passen.
In der Statistik spricht man von Overfitting (oder Überanpassung), wenn das Modell auf die Trainingsdaten spezialisiert ist. Im Trainingsdatensatz erzielt man dann eine sehr hohe Modellgüte. Bei Anwendung auf Testdaten ergeben sich deutlich niedrigere Werte für die Modellgüte. Das Modell ist an die Trainingsdaten übermässig angepasst, eine Übertragung des Modells auf die Grundgesamtheit (Generalisierung) ist dadurch nicht möglich.
Folgende Faktoren begünstigen ein Overfitting:
- Geringe Anzahl von Beobachtungen in der Trainingsmenge im Vergleich zu den Einflussvariablen. Insbesondere im Data Mining ist Overfitting Neural Network meist auf diesen Punkt zurückzuführen. Bei vielschichtigen neuronalen Netzen werden tausende von Parametern geschätzt!
- Verzerrung (Bias) bei der Auswahl der Stichprobe aus der Grundgesamtheit
- Spezielles Overfitting Machine Learning entsteht dadurch, dass die Modelle zu sehr trainiert werden. Durch wiederholtes Aufsplitten des gleichen Datensatzes in Trainings- und Testdaten werden die Modelle immer besser hinsichtlich der Modellgüte. Wird zu viel trainiert, beschreiben die Modelle allerdings nur mehr die Trainingsdaten, eine Übertragung auf die Grundgesamtheit misslingt.
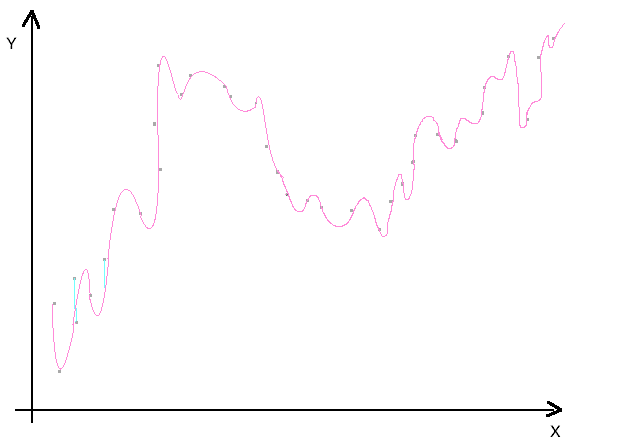
Der Spagat zwischen Overfitting und Underfitting
Die Kunst der Modellierung besteht darin, ein optimales Modell zu finden, dass weder auf Overfitting noch auf Underfitting beruht. Diesen Punkt zu finden, ist jedes Mal eine grosse Herausforderung. Erfahrung, Hintergrundwissen, Fachkompetenz und viel Fingerspitzengefühl sind wesentliche Eigenschaften, die einem Analysten helfen, ein gutes, stabiles und anwendbares Modell zu finden.
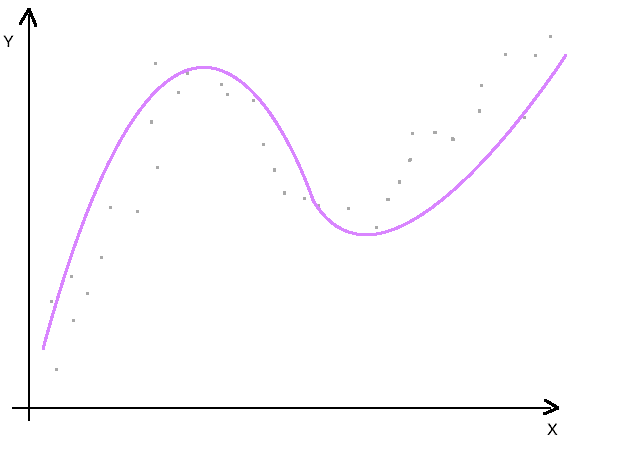
In der modernen Statistik stellt Overfitting eine grosse Herausforderung dar. Meist liegen bereits sehr viele verschiedene Variablen vor, zusätzliche Variablen können durch einfache Umformungen berechnet werden. Auf der anderen Seite sind Auswertungen zeitlich limitiert. Die Ergebnisse sollten am besten schon gestern vorliegen. Dadurch ist die Anzahl an Beobachtungen meist relativ gering. Die Rekrutierung neuer Beobachtungszeiten kostet Zeit. Diese Konstellation: wenig Beobachtungen, viele Variable birgt die Gefahr von Overfitting bereits in sich.
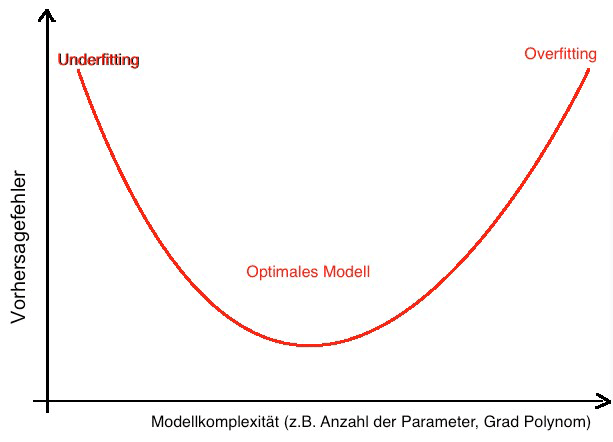
Unsere Profi-Tipps: Wie kann Overfitting verhindert werden?
- Einplanung eines genügend grossen Zeitfensters: Zeit für eine unverzerrte und repräsentative Stichprobenziehung. Zeit benötigt man auch, um genügend viele Beobachtungen für die Modellbildung zu sammeln: Als Faustregel benötigt man pro stetiger Einflussvariable mindestens 10 Beobachtungseinheiten, bei kategorialen Merkmalen 10 Beobachtungen pro Ausprägung. Wir unterstützen Sie gerne bei einer professionellen Fallzahlplanung.
- Sachbezogene Vorüberlegungen: Welche Variablen sind relevant? Gibt es bereits nachgewiesene Zusammenhänge? Welche funktionalen Zusammenhänge sind fachlich gerechtfertigt?
- Ein Schritt nach dem anderen: Auch wenn Computerprogramme dazu verleiten: Zunächst erfolgt die Beschreibung der Stichprobe anschliessend werden bivariate Zusammenhänge und Abhängigkeiten der Variablen untereinander untersucht. Erst dann können multiple Modelle sinnvoll beschrieben werden.
- Aufteilung des Datensatzes in Test- und Trainingsdatensatz: So besteht die Möglichkeit, die Modellgüte an Daten zu überprüfen, die nicht zur Schätzung der Modellparameter verwendet werden. Ist die Modellgüte im Trainingsdatensatz wesentlich höher als im Testdatensatz, so ist Overfitting gegeben.
- Resampling Methoden, wie die k-fache Kreuzvalidierung bieten eine weitere Möglichkeit, das Modell an unbekannten Daten zu erproben. Overfitting Machine Learning kann so oft aufgedeckt werden.
- Werden Modelle iterativ geschätzt, z. B. im Machine Learning, so kann ein vorzeitiges Stoppen des Algorithmus einem Overfitting entgegenwirken. Meist ist dies durch Festlegung der gewünschten Genauigkeit möglich (z. B. bei RapidMiner).
- Es gibt einige Methoden, die eine Vereinfachung der Modelle erzwingen und so Overfitting entgegenwirken können. So können Entscheidungsbäume beispielsweise beschnitten werden (Pruning). Dadurch kann man die Grösse des Baumes regulieren. Beschneidung führt zu kleineren Bäumen, die weniger auf die Trainingsdaten spezialisiert sind. Bei Regressionsmodellen können Strafterme eingeführt werden, die die Anzahl an Variablen und deren Wechselwirkungen berücksichtigen. Overfitting neural network kann verhindert werden, indem die Dropout Technik angewendet wird. Dabei wird jeweils eine Beobachtung zufällig aus dem Algorithmus ausgeschlossen. Dadurch werden alle weiteren Verbindungen der Knoten beeinflusst. Nach wiederholter Anwendung können anschliessend die Einzelmodelle wieder zu einem stabilen Model zusammengefügt werden.
Zusammenfassung:
Gerade im Data Mining stellt Overfitting ein grosses Problem dar. Die gefundenen Modelle sind spezialisiert auf die Trainingsdaten. Dadurch ist eine Übertragbarkeit auf die Grundgesamtheit nur mehr eingeschränkt und mit grossen Fehlern möglich. Wir haben Ihnen einige Methoden vorgestellt, mit denen Overfitting (z.B. Overfitting Neural Network) effektiv vermieden werden kann. Gerne beraten wir sie anhand Ihrer Problemstellung ganz konkret, welche Schritte notwendig sind, um ein stabiles Modell zu entwickeln. Nehmen Sie Kontakt mit uns auf. Wir freuen uns auf Ihre Herausforderung.