
In diesem Statistik für Dummies – Artikel wollen wir Ihnen die wichtigsten Statistik Grundlagen vermitteln und dabei auf grundlegende Statistik Konzepte, Kennzahlen und Verfahren eingehen. Wir möchten bei Ihnen eine Wissensbasis schaffen, die es Ihnen erlaubt, Ihre statistische Auswertung zu verstehen und durchzuführen. Denn jeder, der mit Statistik arbeitet oder damit konfrontiert wird, muss die grundlegende Systematik einer statistischen Datenanalyse verstehen. Dabei handelt es sich hier um eine Statistik für Dummies – Anleitung, Sie benötigen also keinerlei Vorkenntnisse. Um einen direkten Praxisbezug herzustellen, verwenden wir einen echten Datensatz und analysieren ihn mit der Statistik Software SPSS. Zudem wird Ihnen die statistische Signifikanz und ein beispielhafter Hypothesentest einfach erklärt.
Sie sind unsicher, wie Sie bei Ihrer Datenanalyse vorgehen sollen und welches statistische Verfahren Sie anwenden sollten? Wir helfen Ihnen gerne mit professioneller Unterstützung für Ihre SPSS Auswertung weiter!
Statistik Grundlagen: Deskriptive Statistik mit SPSS
Die Statistik unterteilt sich grob in die drei Bereiche deskriptive, explorative und induktive Statistik. Man beginnt seine Datenanalyse für gewöhnlich mit der deskriptiven (= beschreibenden) Statistik. In der deskriptiven Statistik geht es darum, mit Hilfe von Tabellen, Kennzahlen und Grafiken die Daten übersichtlich darzustellen. Im Anschluss kann man die explorative (= erkundende) oder induktive (= schliessende) Statistik durchführen. Während die explorative Statistik Data-Mining Techniken und andere statistische Verfahren einsetzt, um Daten zu visualisieren und statistische Hypothesen zu erzeugen, fokussiert sich die induktive Statistik auf das Testen von Hypothesen und stützt sich dabei auf die Wahrscheinlichkeitstheorie.
Falls Sie Unterstützung für Ihre statistische Auswertung brauchen, unterstützen wir Sie gerne mit einer massgeschneiderten Statistik Beratung. Unser Expertenteam hat Erfahrung mit der gesamten Bandbreite statistischer Datenanalyse!
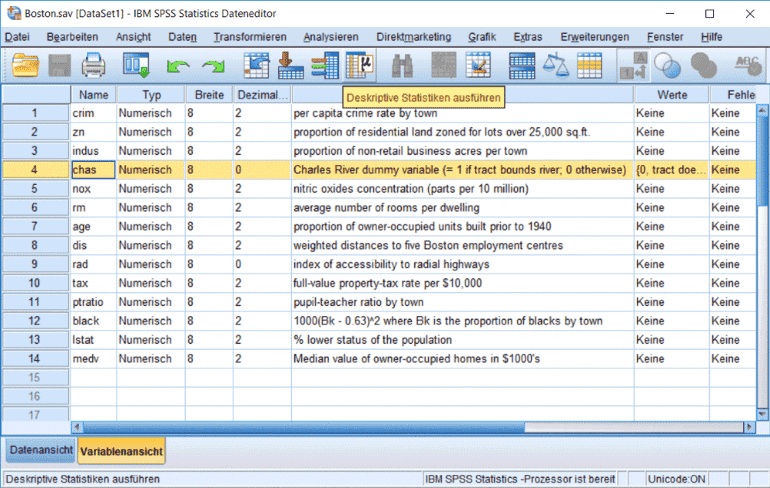
In diesem Abschnitt beschäftigen wir uns zunächst mit der deskriptiven Statistik. Wenn Sie möchten, können Sie unsere Statistik für Dummies – Anleitung direkt an Ihrem Rechner ausprobieren. Wir verwenden für unser Tutorial den Boston Housing Datensatz, welcher Forschungsergebnisse über den Immobilienmarket in Boston beinhaltet. Die online verfügbaren Informationen haben wir bereits in einen SPSS Datensatz zusammengefügt, den Sie hier herunterladen können. Starten Sie SPSS und klicken auf das gelbe Ordnersymbol oben links. Navigieren Sie zum Verzeichnis, in welchem Sie die Datei „Boston.sav“ abgespeichert haben und öffnen diese (Abb. 1). Unten links haben Sie die Wahl zwischen der Variablenansicht und der Datenansicht. In der Variablenansicht (Abb. 2) sehen Sie die Eigenschaften der 14 Variablen. Der „Name“ identifiziert die Variablen mit einer Länge von höchstens 8 Zeichen. Platz für eine ausführliche Beschreibung der Variablen liefert die Spalte „Beschreibung“. Das Messniveau ist ein Mass für den Informationsgehalt der Variablen und bestimmt mit darüber, welche statistischen Verfahren möglich sind. Das nominale Skalenniveau hat das niedrigste Informationsniveau. In unserem Datensatz kommt es bei der Dummy-Variable „chas“ vor. In SPSS haben üblicherweise alle Variablen (bis auf Textfelder) einen numerischen Datentyp und so ist auch diese Dummy-Variable mit 0 und 1 codiert. Die Bedeutung dieser Codierung (Grundstück am Fluss oder nicht) ist bei den „Wertelabels“ aufgeführt. Die Erreichbarkeit zum Zentrum in der Variable „rad“ ist ordinal skaliert auf einer Skala zwischen 1 und 8 und die restlichen Variablen sind metrisch skaliert.
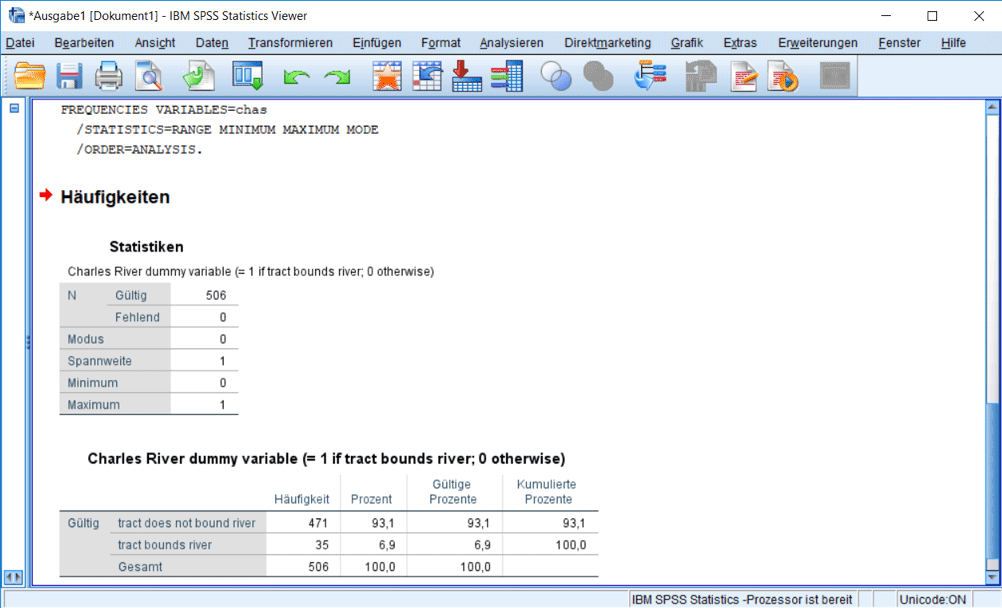
Zu den wichtigsten Statistik Grundlagen zählt die Berechnung von statistischen Kennzahlen wie Mittelwert, Modus, Median, Standardabweichung und Varianz. Klicken Sie in der Variablenansicht auf die vierte Zeile und fordern Sie die deskriptiven Statistiken der Variable „chas“ mit einem Klick auf das entsprechende Symbol in der Symbolleiste an (Abb. 2). Im Ausgabefenster (Abb. 3) wird nun oben die Befehlssyntax angezeigt und darunter werden die deskriptiven Statistiken tabelliert. In der unteren Tabelle werden die absoluten und in Prozent die relativen Häufigkeiten für die beiden Kategorien „am Fluss“ und „nicht am Fluss“ angezeigt. In der oberen Tabelle kann man den Modus 0 („nicht am Fluss“) ablesen. Der Modus ist der häufigste Wert und der einzige mögliche Lageparameter bei nominalem Skalenniveau.
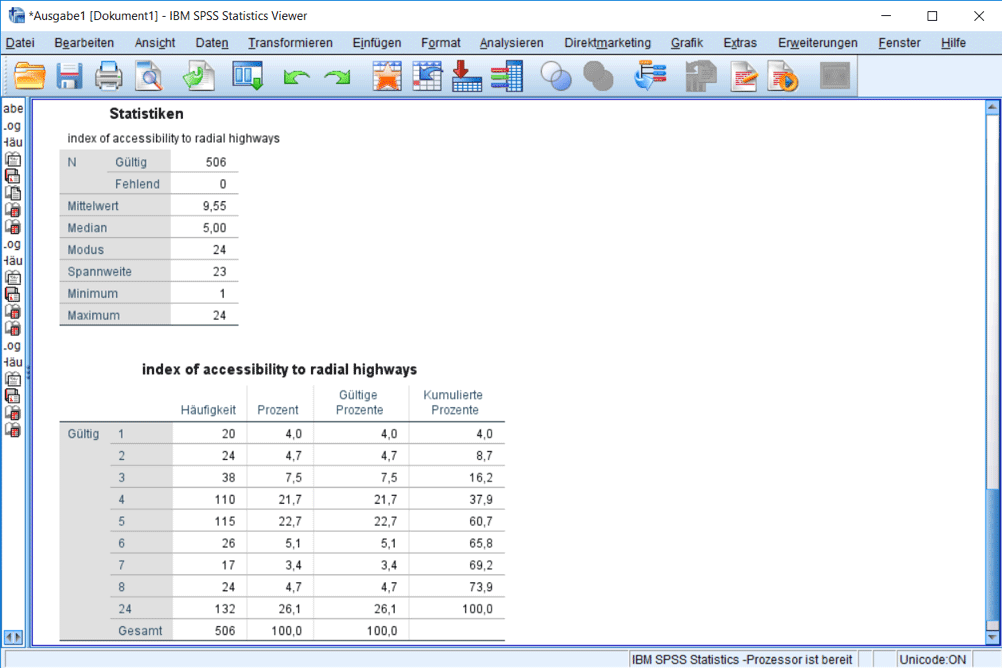
Wenn Sie die deskriptiven Statistiken zur Variable „rad“ anfordern (Abb. 4), erscheint zusätzlich der Median. Denn diese Variable ist ordinal skaliert und somit können Sie den Median berechnen. Der Median ist der Wert in der Mitte des Datenspektrums. Bei den Werten 2, 3, 5, 7, 11, 13, 17 lautet der Median beispielsweise 7, weil jeweils drei Werte kleiner und grösser sind als 7. In unserem Beispiel ist der Median 5. Wenn Sie den Mittelwert berechnen möchten, auch Durchschnitt genannt, müssen Sie alle Werte summieren und das Ergebnis durch die Anzahl der Werte dividieren. In diesem Fall ergibt dies einen Mittelwert von 9.55. Neben den Lageparametern gibt es auch Streuungsmasse wie die Standardabweichung und die Varianz. Die Standardabweichung ist die mittlere Abweichung der Werte von ihrem Mittelwert und die Varianz ist die mittlere quadratische Abweichung. Diese Kennzahlen sind allerdings nur bei metrisch skalierten Variablen sinnvoll.
Hypothesentest einfach erklärt: Verschiedene Verfahren richtig nutzen
In diesem Abschnitt wird Ihnen das Prinzip Hypothesentest einfach erklärt. In der Statistik stellt man eine Hypothese auf (genauer: ein Hypothesenpaar) und trifft anhand vorliegender Beobachtungen (zum Beispiel Messwerte oder Umfrageergebnisse) und mathematischer Berechnungen eine Entscheidung über die Gültigkeit oder Ungültigkeit dieser Hypothese.
Die Durchführung eines Hypothesentests kann man sich vorstellen wie ein Gerichtsverfahren. Angenommen, ein Angeklagter wird beschuldigt einen Mord begangen zu haben. Zunächst geht das Gericht von der Unschuld des Angeklagten aus (Nullhypothese). Anhand von Indizien, Zeugenaussagen und Gutachten trifft der Richter die Entscheidung darüber, ob es zu einer Verurteilung kommt. Die Nullhypothese lautet „Der Angeklagte ist unschuldig“ und falls die Beweislage nicht eindeutig ist, geht der Richter von der Unschuldsvermutung aus. Er behält die Nullhypothese also bei. Ist der Richter jedoch aufgrund der vielen Indizien von der Schuld des Angeklagten überzeugt, verurteilt er ihn. Statistiker bezeichnen dies als Ablehnung der Nullhypothese. Es wird also die Alternativhypothese „Der Angeklagte ist schuldig“ angenommen. Egal welches Urteil der Richter fällt, in beiden Situationen kann es zu einem Fehlurteil kommen. Falls der Richter einen Unschuldigen verurteilt, begeht er einen Fehler erster Art. Diese Fehlentscheidung wird als die gravierendere betrachtet, daher auch der Spruch „Im Zweifel für den Angeklagten“. Spricht er einen Schuldigen frei, handelt es sich um den Fehler zweiter Art. Die Wahrscheinlichkeit einen schuldigen Angeklagten aufgrund der Indizien korrekterweise zu verurteilen wird auch Güte bzw. Power genannt. Dieser Wert sollte möglichst hoch sein.
Die Auswahl an statistischen Tests ist gewaltig und es fällt nicht immer leicht, für jede Situation einen passenden Test zu finden. Hier eine Übersicht über die verschiedenen Arten statistischer Tests:
- Tests auf Lageparameter (Mittelwert, Median)
- Tests auf Streuung
- Tests auf Zusammenhangs- und Assoziationsparameter
- Anpassungs- und Verteilungstests
- Tests in der Regressions- und Zeitreihenanalyse
- Sonstige Tests
Im folgenden Abschnitt werden wir drei Tests durchführen, davon zwei Tests auf Lageparameter und einen auf Streuung.
Statistik für Dummies – SPSS Hypothesentests und statistische Signifikanz richtig interpretieren
Wir möchten herausfinden, ob das numerische Verhältnis von Schülern und Lehrern an der Schule sich im Mittel unterscheidet, je nachdem ob die Schüler am Fluss wohnen oder nicht (Alternativhypothese). Wir wollen hierfür einen t-Test verwenden und müssen als Voraussetzung an dieses Verfahren erst überprüfen, ob die Variable „ptratio“ in beiden Gruppen der Variable „chas“ normalverteilt ist. Die Normalverteilung ist die bekannte glockenförmige Kurve. Erstellen Sie hierfür wie in Abbildung 5 dargestellt zwei Boxplots.
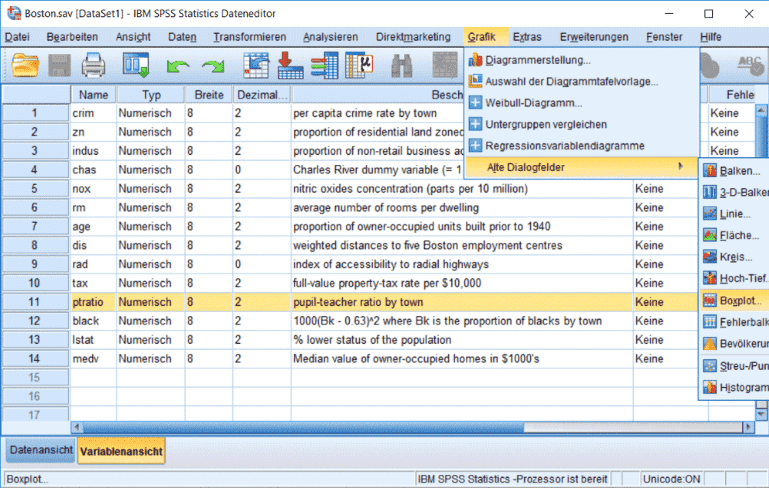
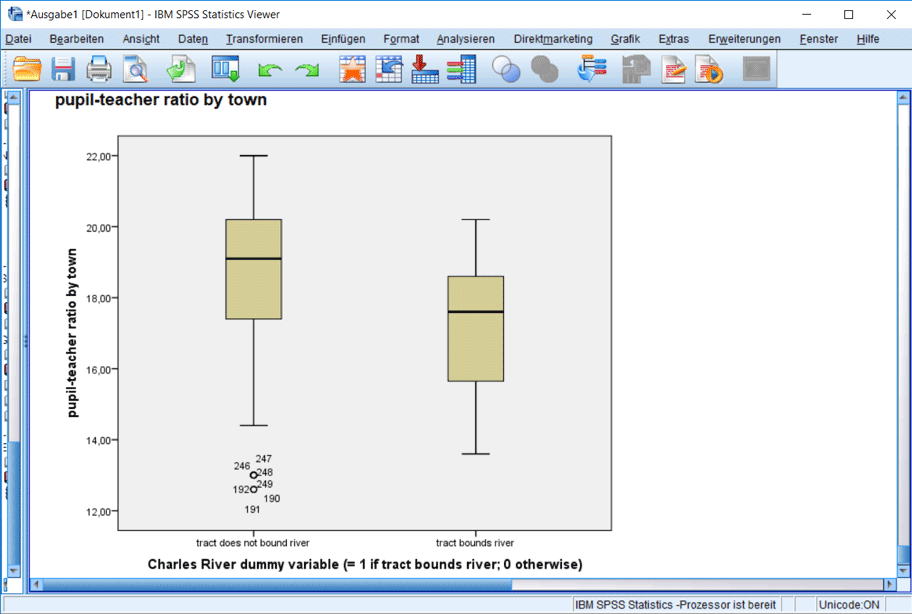
Ziehen Sie die Variable „ptratio“ in das Feld „Variable“ und „chas“ auf die Kategorieachse (Abb. 6) und bestätigen sie mit „OK“. In Abbildung 7 können Sie die Verteilungen der beiden Untergruppen erkennen. Man kann direkt erkennen, dass die Klassengrösse in der Gruppe „am Fluss“ im Mittel kleiner ist. Allerdings sind die Abstände zwischen der mittleren waagerechten Linie (Median) und der unteren kleinen waagerechten Linie in beiden Gruppen grösser als der nach oben und die mittleren waagerechten Linien befinden sich relativ weit oben in der Box. Die Verteilungen sind also asymmetrisch. Ausserdem sind unter der linken Box Ausreisser zu erkennen. Das alles spricht eher gegen die Normalverteilung. Wir werden zur Verdeutlichung nun zusätzlich noch den t-Test berechnen.
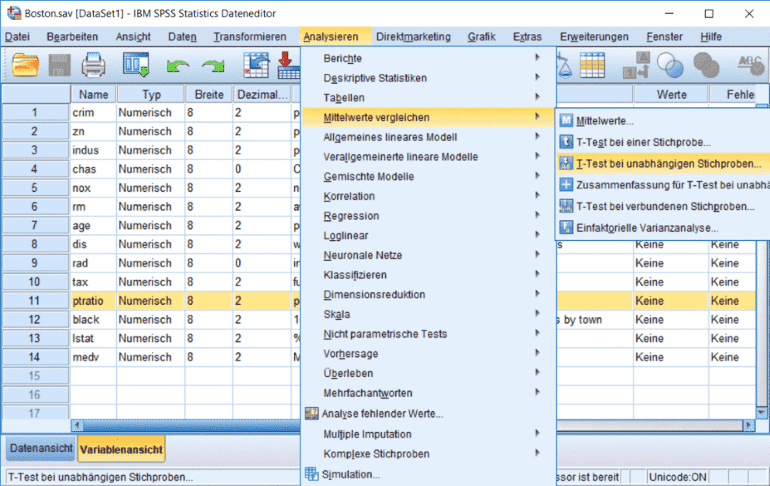
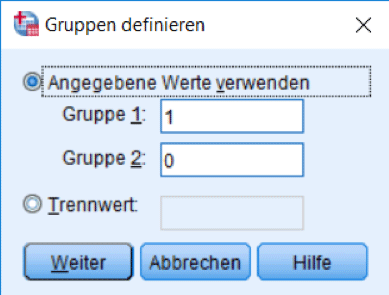
Wählen Sie wie in Abbildung 8 nun aus dem Menü den t-Test für unabhängige Stichproben durch. Verwenden Sie wie in Abbildung 9 als Testvariable „ptratio“ und als Gruppierungsvariable „chas“. Definieren Sie die Gruppen wie in Abbildung 10, denn unsere Dummy-Variable ist so codiert.
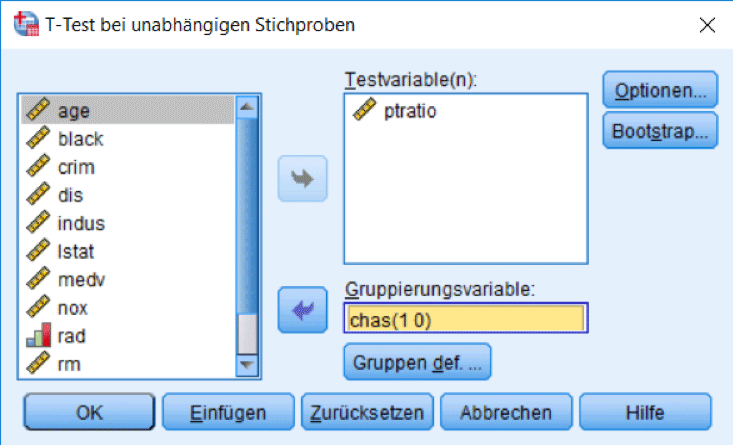
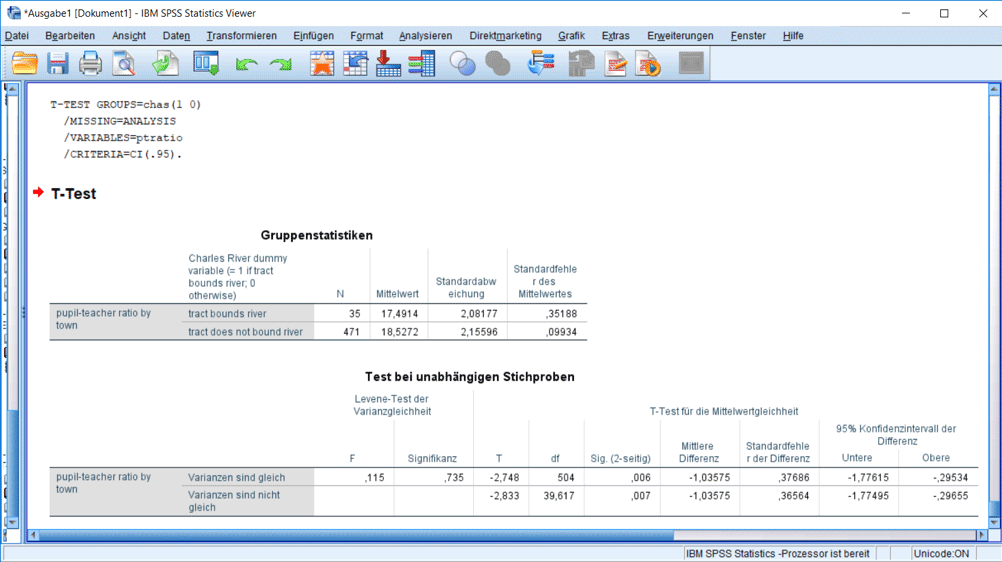
Nach der Bestätigung können Sie die Testergebnisse im Ausgabefenster (Abb. 11) sehen. Zunächst erscheinen die deskriptiven Gruppenstatistiken. Die Gruppe „am Fluss“ ist wesentlich kleiner als die andere und die Klassengrösse ist im Mittel kleiner. Doch besitzt der Unterschied auch eine statistische Signifikanz? Als Voraussetzung für den t-Test muss die Standardabweichung in beiden Gruppen etwa gleich gross sein. Das können wir mit Blick auf die obere Tabelle bestätigen. Das wird zusätzlich noch mit der Signifikanz des Levene-Tests bestätigt, welche 0.735 beträgt und damit deutlich über 0.05 liegt (Varianzgleichheit wird also nicht abgelehnt). Der t-Test selbst gibt die p-Werte 0.006 und 0.007 aus, welche deutlich kleiner als 0.05 sind. Damit lehnen wir die Nullhypothese ab, es gibt also einen signifikanten Unterschied zwischen den beiden Gruppen. Die Klassen von Schülern, welche am Fluss wohnen, sind im Mittel um 1.03575 Schüler kleiner und dieser Unterschied ist signifikant.
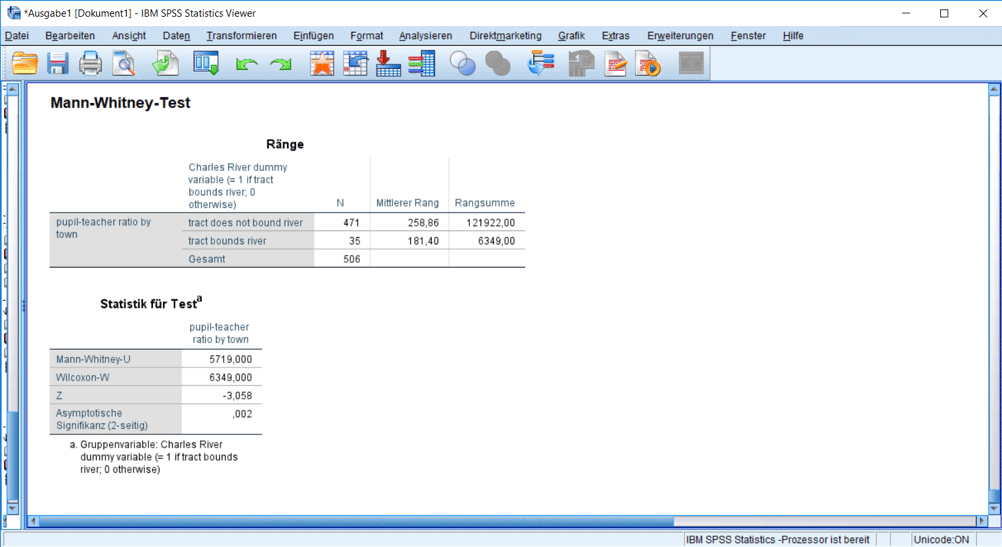
Wenn wie in unserem Beispiel die Daten nicht normalverteilt sind, sollte man eigentlich auf einen robusten Test wie den Mann-Whitney-Test ausweichen. Dieser vergleicht die Mediane statt der Mittelwerte und benötigt nur ordinal skalierte Variablen.
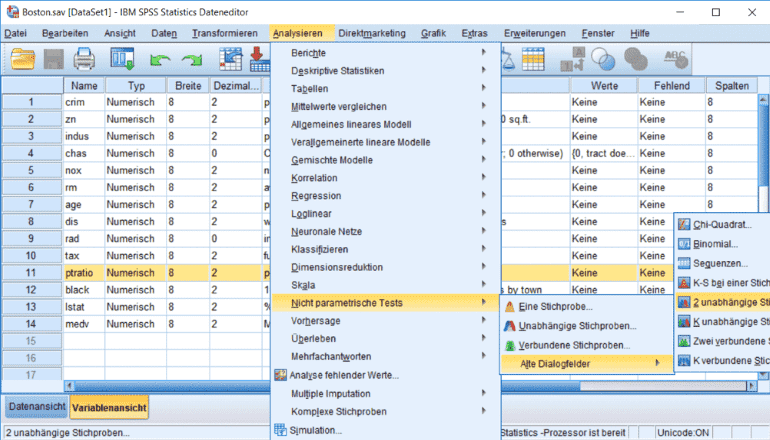
Rufen Sie das entsprechende Menü wie in Abbildung 12 dargestellt auf und wählen Sie die gleichen Einstellungen wie zuvor beim t-Test.
Die statistische Signifikanz bei diesem Test beträgt 0.002 und damit ist der Unterschied zwischen den Gruppen auch nach diesem Test signifikant.
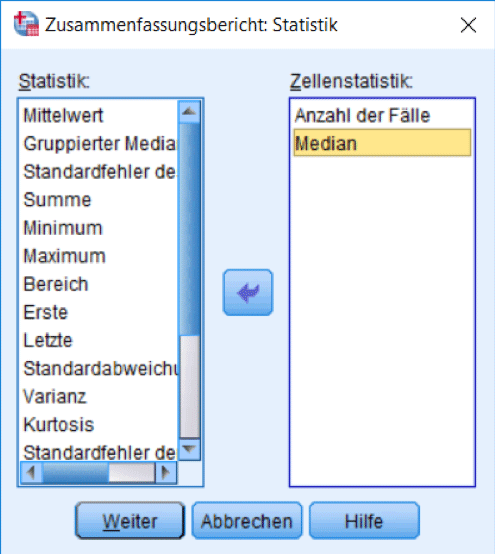
Leider zeigen die Statistiken in Abbildung 13 keine Mediane an. Wählen Sie daher aus dem Menü Analysieren → Berichte → Fallzusammenfassungen und fügen Sie als Statistik den Median hinzu (Abb. 14).
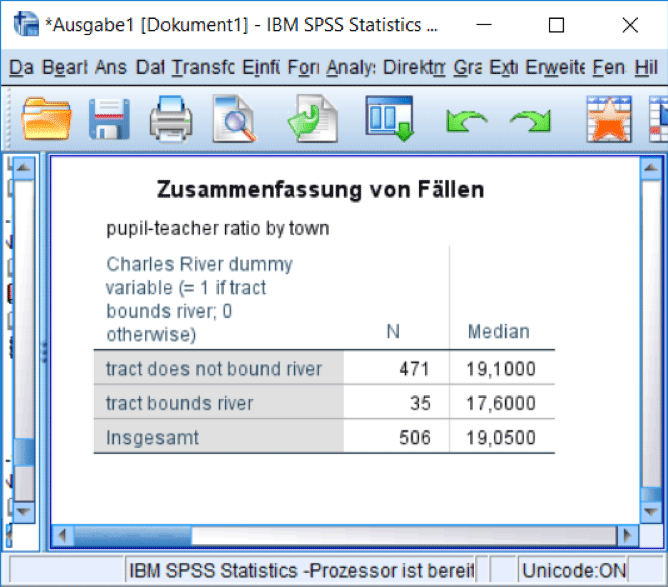
Nach Bestätigung mit „Weiter“ und „OK“ sehen können Sie die Mediane in den Subgruppen und insgesamt miteinander vergleichen. Der Unterschied der Mediane in den Subgruppen beträgt 1,5 und ist damit etwas höher als der der Mittelwerte (Abb. 15).
SPSS Tutorial (Video)
Nun haben Sie bereits einen ersten Überblick über die Datenanalyse mit SPSS erhalten. Eine zusätzliche Einführung zur statistischen Analyse mit SPSS erhalten Sie ausserdem in unserer Videoreihe “SPSS Tutorial”.

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von Vimeo.
Mehr erfahren
Zusammenfassung
In diesem Artikel haben wir Ihnen die zentralen Statistik Grundlagen und einen Hypothesentest einfach erklärt und sind dabei auf grundlegende Statistik Konzepte, Kennzahlen und Verfahren eingegangen. Wir haben den Unterschied zwischen deskriptiver, explorativer und induktiver Statistik erläutert und eine praktische Anleitung zur Umsetzung in einer Statistik Software zur Verfügung gestellt.
Wir hoffen, Ihnen mit dieser Statistik für Dummies – Einführung mit SPSS weiter geholfen zu haben und Sie nun befähigt sind, einfache Datenauswertungen selbständig erledigen und statistische Analysen besser verstehen zu können. Falls Sie allerdings mit komplizierteren statistischen Themen zu tun haben und eine statistische Beratung oder eine SPSS Schulung benötigen, freuen sich unsere Statistik Experten darauf, ihre professionelle Hilfe für statistische Auswertung anzubieten.