
Vor einiger Zeit haben wir einen Artikel zu statistischen Funktionen in Excel online gestellt. Da dies Thematik statistischer Datenanalyse für unsere Leser*innen von hohem Interesse ist und wir zudem regelmässig Anfragen zu Datenanalysen in der Programmiersprache R erhalten, wollen wir in diesem Artikel einen Überblick über die wichtigsten Funktionen der R Statistik liefern!
Zögern Sie nicht, uns zu kontaktieren, wenn Sie Fragen zur Datenauswertung und zur Statistik mit R haben. Wenden sie sich einfach an uns für eine Statistik Beratung, unsere professionellen Statistiker helfen Ihnen gerne, Ihr Projekt im Handumdrehen zum Erfolg zu führen!
In diesem Artikel beginnen wir beim Laden der Daten aus einer CSV Datei. Wir lernen Funktionen kennen, mit denen wir uns einen Überblick über die Daten verschaffen können und widmen uns schliesslich den Lagemassen und den Funktionen der deskriptiven R Statistik.
Der Einstieg in die R Statistik
Sollten dies die ersten Schritte mit der Programmiersprache R sein, so muss man erst die Programmierumgebung aufsetzen, bevor man einen Mittelwert in R berechnen kann. Wir haben schon im Artikel R vs. Python daraufhin gewiesen, dass man zuerst den sogenannten Compiler für R installieren muss um anschliessend die IDE RStudio installieren zu können. Dies ist im Detail auf der RStudio Webpage erklärt. Weiterhin empfehlen wir die Nutzung von R Notebooks.
Im ersten Block bei Code lädt man die Daten in R in einen sogenannten Dataframe und schaut sich die ersten sechs Zeilen mithilfe des head() Befehls an. Die verwendeten Daten sind am Ende des Artikels wie immer verlinkt. Die Daten lagen hier in Form einer .csv Datei vor. Sollte ein anderes Dateiformat vorliegen, so kann man in unserem Artikel zu R Data Mining den entsprechenden Befehl finden.
```{r}
data <- read.csv("MFG10YearTerminationData.csv")
head(data)
```Die Ausgabe des Datensatzes enthält insgesamt 18 Spalten, von denen wir hier sechs Stück exemplarisch darstellen. In RStudio können wir alle Spalten betrachten, indem wir die kleinen Pfeile oben rechts im Ausgabebereich benutzen.
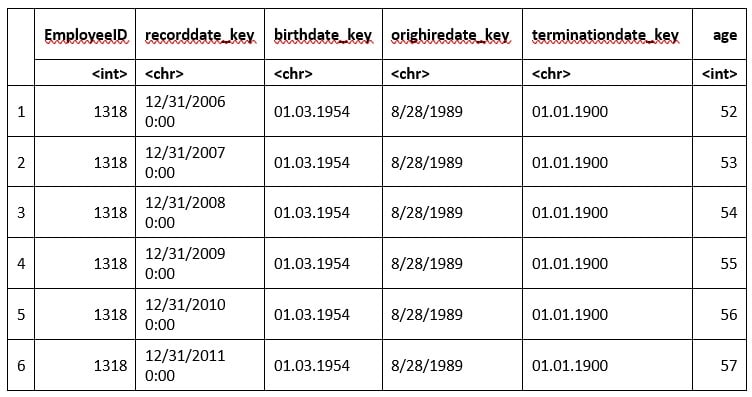
Hier erkennt man schon sehr gut, quasi analog zu Excel, wie die Daten aufgebaut sind. Man bekommt Information darüber, wie die Daten beschaffen sind (hier sind es chr für Character und int für Integerwerte). Ein praktisches Tool in der R Statistik ist der summary() Befehl. Wendet man diesen an, so errechnet er verschiedene statistische Lagemasse für alle Spalten des Dataframes. Wir zeigen hier auszugsweise drei Beispiele.
EmployeeID
Min. :1318
1st Qu.:3360
Median :5031
Mean :4859
3rd Qu.:6335
Max. :8336
recorddate_key
Length:49653
Class :character
Mode :character
age
Min. :19.00
1st Qu.:31.00
Median :42.00
Mean :42.08
3rd Qu.:53.00
Max. :65.00
Natürlich machen die Lageparamter für die EmployeeID wenig Sinn, aber beim Alter der Angestellten hilft uns das freilich, die statistische Auswertung mit R zu planen. Für Daten des Typs Character wird ausserdem die Menge aller Einträge angegeben.
Schnelle Grafiken: Häufig reicht ein Blick!
Ruckzuck kann man sich mithilfe der nativen Funktionen plot(x, y) und hist(x) einen tatsächlichen Überblick darüber verschaffen, wie die Daten liegen. Im folgenden zwei Beispiele mit den verwendeten Befehlen jeweils in der Bildbeschreibung.
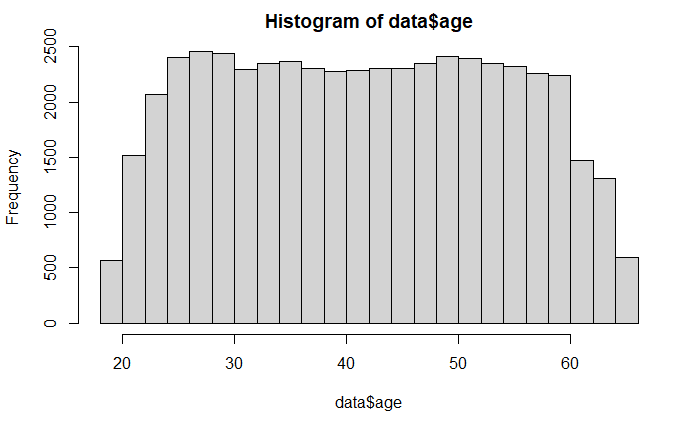
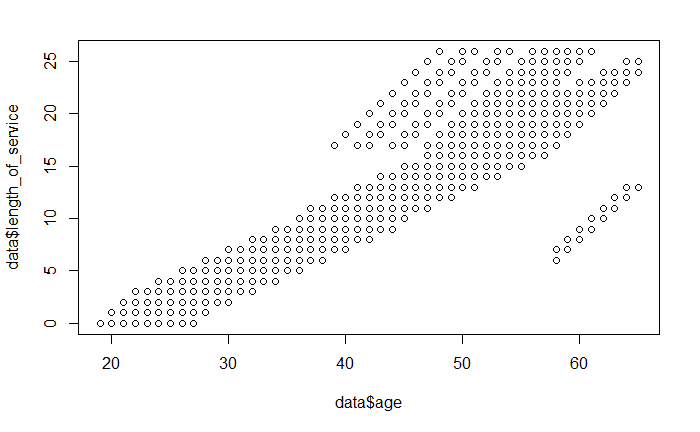
Der Vorteil von R Statistik zeigt sich hier darin, dass man diese Grafiken mit einer einzelnen Code-Zeile erstellen kann. Möchte man zum Beispiel aufwändigere Darstellungen für eine Veröffentlichung erstellen, so hilft die Verwendung des Grafik-Pakets ggplot2. Die konkrete Anwendung zeigen wir im Blogartikel ggplot2: Grafiken in R.
Excels ZÄHLENWENN und SUMMEWENN bei Statistik mit R
In unserem Artikel zu Statistik mit Excel haben wir auch die praktische SUMMEWENN()-Formel erläuetert. Um diese Funktion in R nachzubauen, schauen wir uns erstmal die klassische SUMME() an. In R heisst die Funktion sum() und wird beispielsweise auf eine Spalte im Dataframe angewendet. Möchte man wissen, wie viele Jahre insgesamt alle Angestellten in der obigen Tabelle gearbeitet haben, gibt man wie folgt ein:
```{r}
sum(data$length_of_service)
```
Als Ausgabe erhält man daraufhin 518.109 (Jahre). Möchte man aber beispielsweise nur die Dienstjahre aller Frauen zählen, so benötigen wir noch die Informationen über das Geschlecht. Mit folgendem Code erhalten wir eine Auflistung aller verschiedener Geschlechter in der entsprechenden Spalte und deren Anzahl:
```{r}
table(data$gender_short)
```Die Ausgabe zeigt, dass es 25.898 Frauen gibt:
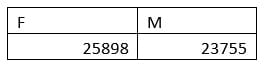
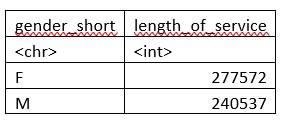
Um nun die Dienstjahre aller Frauen zu zählen, nutzen wir die Funktion aggregate(), diese steht für vereinigen. Der Funktion übergibt man zuerst die Spalte, über die die Summe gezogen werden soll, dann die Spalte, welche die Summierungsbedingung enthält. Anschliessend muss noch der Dataframe definiert werden sowie die Funktion, die genutzt werden soll (hier sum()).
```{r}
aggregate(length_of_service ~ gender_short, data=data, sum)
```Das Ergebnis ist eine Tabelle, wo in der Spalte für die Dienstjahre die Summe der Dienstjahre steht:
Lageparameter finden: Den Mittelwert in R berechnen und weitere Funktionen
Die Funktion für den Mittelwert in R Statistik lautet ganz einfach mean() und lässt sich auf eine Spalte im Dataframe anwenden:
```{r}
mean(data$age)
```
Das Ergebnis lautet 42.07703 (Jahre). Analog zu oben wollen wir nun mittels der Funktion aggregate() den Mittelwert in R berechnen nach Geschlecht. Und anschliessend auch die jeweilige Standardabweichung mithilfe der Funktion sd():
```{r}
aggregate(age ~ gender_short, data=data, mean)
aggregate(age ~ gender_short, data=data, sd)
```Die Ergebnistabellen lauten:
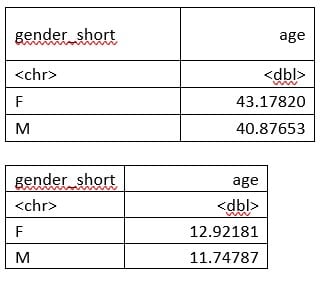
Hier sei angemerkt, dass sd() den Denominator 1/(N-1) verwendet, also die Stichprobenstandardabweichung. Man kann natürlich nicht nur den Mittelwert in R berechnen, sondern es gibt noch eine Fülle weiterer Standardfunktionen:

Fazit
Das breite Aufgabenspektrum der Statistik mit R fängt hier freilich erst an! Über Korrelationsanalysen, T-Tests, Anovas bis hin zu komplizierten Regressionen in R ist quasi alles möglich. Es würde allerdings den Rahmen dieses Überblickartikels sprengen, auf diese Möglichkeiten im Detail einzugehen.
Wenn Sie weitere konkrete Frage zu diesem Thema haben, helfen wir Ihnen gerne in einem individuellen Coaching weiter! Stellen Sie hierzu eine unverbindliche Kontaktanfrage, auch die telefonische Erstberatung ist kostenfrei!