
Neben grafischen und numerischen Analysen für unterschiedlich skalierte Variablen bietet sich die Möglichkeit, eine Diskriminanzanalyse in SPSS für Paarungen von unabhängigen metrischen Variablen und einer abhängigen kategorialen (nominal oder ordinal skalierten) Variable durchzuführen.
So kann beispielsweise ermittelt werden, wie sich Alter und Einkommen eines Befragten auf seine Bonität auswirken.
Im Folgenden wird zunächst auf die mathematischen Grundlagen einer Diskriminanzanalyse eingegangen, im Anschluss werden der Ablauf einer Diskriminanzanalyse SPSS anhand eines Beispiels anwendend erklärt und die Ergebnisse interpretiert und bewertet.
Sollten Sie Unterstützung bei Ihrer Analyse mit SPSS benötigen, helfen unsere Statistiker Ihnen gerne weiter. Nutzen Sie einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Die Diskriminanzanalyse generell
Bei der Diskriminanzanalyse wird angenommen, dass zwei oder mehr metrische Variablen in einem funktionalen Zusammenhang zu einer kategorialen (nominal oder ordinal skaliert) Variable stehen, wobei zwischen abhängigen Variablen (meist mit Y bezeichnet) und unabhängigen Variablen (mit X bezeichnet) unterschieden wird.
Es handelt sich somit um eine multivariate Methode auf Basis einer Klassifikationsanalyse und besitzt Ähnlichkeiten mit der logistischen Regression. Dabei wird angenommen, dass sich Y als d(X) für eine Diskriminanzfunktion D beschreiben lässt – diese Funktion anhand von Beobachtungsdaten zu schätzen wird als Diskriminanzanalyse bezeichnet.

In SPSS ist dazu der lineare Ansatz implementiert, der von einer Unabhängigkeit der erklärenden metrisch skalierten Variablen ausgeht. Die so genannte Diskriminanzfunktion, die der Schätzung der Regressionsfunktion sehr ähnlich ist, lautet:
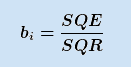
Die Koeffizienten b werden ähnlich der Varianzanalyse mit Hilfe der quadratischen Summen der beobachteten Gruppen ermittelt – es gilt dabei
.
SQE bezeichnet die Quadratsumme zwischen den Gruppen, SQR die Quadratsumme innerhalb der Gruppen. Der Startwert b0 wird anhand der Mittelwerte bestimmt.
Die Diskriminanzanalyse SPSS
Die Diskriminanzanalyse SPSS nutzend findet sich unter: „Analysieren → Klassifizieren → Diskriminanzanalye“
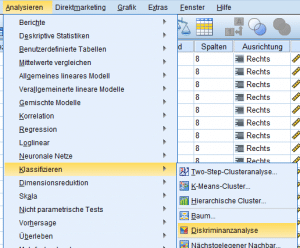
Aus der Liste werden nun die abhängige kategoriale Variable sowie die unabhängigen metrisch skalierten Variablen ausgewählt. Zu beachten ist, dass für die abhängige Variable (Gruppenvariable) die zu betrachtenden Gruppen definiert werden müssen.
Im Beispiel soll untersucht werden, wie sich die wöchentliche Arbeitszeit, die Zufriedenheit innerhalb der Ehe, sowie das Einkommen auf die allgemeine Zufriedenheit auswirken.
Die (kategoriale) Gruppenvariable Zufriedenheit ist mit 1 für zufrieden und 2 für unzufrieden definiert.

In der ausgegebene Tabelle „Kanonische Diskriminanzfunktionskoeffizienten“ einer Diskriminanzanalyse SPSS anwendend werden nun die Koeffizienten der Einflussfaktoren sowie der konstante Startwert angegeben.
Demnach lässt sich die Zufriedenheit als -2,629 + 1,648 * Zufriedenheit in der Ehe + 0,31 * Arbeitszeit ER + 0,27 * Arbeitszeit SIE – 0,012 * wöchentliche Arbeitszeit – 0,502 * vierteljährliches Einkommen angeben.
Der starke positive Einfluss der Ehe und schwach positive Einfluss der Arbeitszeit ist soweit auch sachlogisch nachvollziehbar, nicht jedoch dass sich das Einkommen negativ auf die Zufriedenheit auswirkt.
Analog zur Regressionsanalyse gilt es die Ergebnisse kritisch zu bewerten und inhaltlich mit Bedacht zu interpretieren: ein statistisch begründeter Zusammenhang impliziert keinesfalls zwangsläufig einen sachlogisch kausalen Zusammenhang.