
Im Alltag begegnen uns täglich zahlreiche Statistiken in den Medien. Doch die Zahlen werden oftmals, ob absichtlich oder unabsichtlich, irreführend dargestellt und falsch interpretiert. In diesem Artikel möchten wir Ihnen mögliche Fehlerquellen und Beeinflussungsmöglichkeiten bewusstmachen und erklären, wie Sie diese vermeiden. Wir stellen Ihnen typische Fallstricke in der Statistik vor, die bei unerfahrenen Anwendern schnell zu Fehlern führen, woraus verzerrte (biased) Ergebnisse resultieren können, und die Sie daher für Ihre statistische Analyse im Hinterkopf behalten sollten. Wir erklären Ihnen, wie Sie ohne einen Bias Statistik betreiben können und was der entscheidende Unterschied zwischen Korrelation und Kausalität ist. Des weiteren werden Sie erfahren, warum interne Validität und externe Validität so wichtig sind.
Welche Fragen werten in diesem Artikel beantwortet?
- Worauf kommt es bei der Datenqualität für die statistische Analyse an?
- Wie lässt sich eine Verzerrung (englisch: bias) vermeiden?
- Welche Arten von Stichproben gibt es?
- Wie werden Sie durch die Darstellungsweise von Datengrafiken manipuliert?
- Was ist der Unterschied zwischen Korrelation und Kausalität?
- Wie können Sie interne und externe Validität sicherstellen?
Statistische Analyse: Korrelation und Kausalität – ein zentraler Unterschied
In diesem Abschnitt stellen wir Ihnen beliebte Fehlerquellen und Gefahren für die Validität vor. Winston Churchill wird oftmals folgendes Zitat zugeschrieben: „Traue keiner Statistik die du nicht selbst gefälscht hast!“. Und wie können Sie eine Statistik am besten fälschen? Indem Sie bei den Grundlagen jeder statistischen Analyse anfangen – bei den Daten. Durch das Fälschen von Daten können Sie jede beliebige statistische Hypothese beweisen. Daher stellen wir Ihnen nun Qualitätskriterien für eine gute Datenqualität vor:
- Korrektheit: Die Daten müssen mit der Realität übereinstimmen.
- Konsistenz: Ein Datensatz darf in sich und zu anderen Datensätzen keine Widersprüche aufweisen.
- Reproduzierbarkeit: Die Entstehung der Daten muss nachvollziehbar und reproduzierbar sein.
- Vollständigkeit: Ein Datensatz muss alle notwendigen Attribute enthalten.
- Genauigkeit: Die Daten müssen in der jeweils geforderten Exaktheit vorliegen (Beispiel: Nachkommastellen).
- Aktualität: Alle Datensätze müssen jeweils dem aktuellen Zustand der abgebildeten Realität entsprechen.
- Redundanzfreiheit: Innerhalb der Datensätze dürfen keine Dubletten vorkommen.
- Relevanz: Der Informationsgehalt von Datensätzen muss den jeweiligen Informationsbedarf erfüllen.
- Einheitlichkeit: Die Informationen eines Datensatzes müssen einheitlich strukturiert sein.
- Eindeutigkeit: Jeder Datensatz muss eindeutig interpretierbar sein.
- Verständlichkeit: Die Datensätze müssen in ihrer Begrifflichkeit und Struktur mit den Vorstellungen der Fachbereiche übereinstimmen.
Bias ist der englische Begriff für Verzerrung und entsteht, wenn Sie eine systematisch Überschätzung oder Unterschätzung eines Faktors in die statistische Analyse einfliessen lassen oder ein falscher Fokus auf die Bestätigung genau einer Hypothese (Confirmation Bias) gesetzt wird. Wenn Sie beispielsweise den Pro-Kopf-Verbrauch von Weissbier in Deutschland schätzen wollen und Sie dazu Menschen auf dem Oktoberfest befragen, wie viel Mass Bier sie getrunken haben, dann werden Sie den Konsum eines Durchschnittsbürgers deutlich überschätzen. Die Stichprobe ist nicht repräsentativ für die Grundgesamtheit, weshalb man auch vom Selektions-Bias spricht. Sie können ohne Bias Statistik Auswertungen erstellen, indem Sie eine zufällige repräsentative Stichprobe ziehen.
Eine Zufallsstichprobe ist also notwendig, wenn Sie ohne nennenswerten Bias Statistik für Ihre Daten berechnen wollen. Man unterscheidet folgende Arten von Zufallsstichproben:
- einstufige und mehrstufige Verfahren (Stufung)
- geschichtete Zufallsstichprobe (Schichtung)
- Cluster Stichprobe (Klumpung)
Selbst wenn Sie bei der Datenerhebung alles richtig machen, eine repräsentative Zufallsstichprobe ziehen und die Regeln für gute Datenqualität einhalten, können Sie die korrekten Daten immer noch irreführend visualisieren. Beim Betrachten von Aktienkursen sind Ihnen sicher schon einmal die abgeschnittenen Füsse der Datengrafik aufgefallen. Um Platz zu sparen, wird der untere Teil der senkrechten Achse abgeschnitten und damit der interessante Teil der Grafik vergrössert. Hierdurch wirkt der Aktienkurs viel dynamischer als er eigentlich ist. Weiter verstärken lässt sich der Effekt, indem Sie die senkrechte Achse strecken und die waagerechte Achse stauchen. Wenn Sie den Abschnitt der waagerechten Achse passend auswählen, können Sie so je nach Wunsch einen stark steigenden oder sinkenden Aktienkurs vorgaukeln. Der Schwindel fällt erst auf beim Betrachten der Achsenbeschriftung, welche Sie aber auch entfernen können.
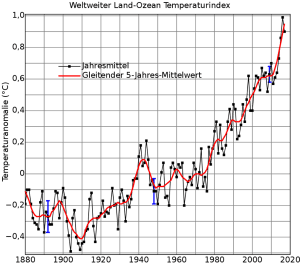
Natürlich können Sie diese Tricks auch auf die statistische Analyse von anderen Arten von Zeitreihen anwenden. Wenn Sie beispielsweise die globale Klimaerwärmung widerlegen möchten, suchen Sie sich eine Phase absteigender globaler Temperaturen (diese kurzfristigen Phasen gibt es trotz langfristiger Klimaerwärmung) und extrapolieren diese. In Abbildung 1 können Sie dafür zum Beispiel den Zeitraum zwischen 1940 und 1975 verwenden, in welchem die Temperaturen insgesamt leicht abgesunken sind, und eine Regressionsgerade mit negativer Steigung einzeichnen. Die Regressionsgerade kann den Temperaturverlauf offensichtlich nur schlecht erklären, denn das Jahresmittel und auch der gleitende 5-Jahres-Mittelwert schwanken stark. Sie können die Schwankungen aber zumindest rein optisch reduzieren, indem Sie die waagerechte Achse strecken und die senkrechte Achse stauchen. Wer nur den so bearbeiteten Ausschnitt der Grafik vor sich liegen hat, kann den Eindruck gewinnen, die Klimaerwärmung finde gar nicht statt. Wer aber die komplette Grafik sieht, kann auf einen Blick erkennen, dass das Klima sich (bis auf ein paar Ausnahmen) immer schneller erwärmt hat und die globale Durchschnittstemperatur heute um 1°C höher ist gegenüber der Basisperiode.
Möchten Sie stattdessen lieber einen kausalen Zusammenhang erfinden, der gar nicht existiert? Nehmen wir einmal an, Sie möchten durchsetzen, dass im Biologieunterricht den Schülern beigebracht wird, Störche würden Babys bringen. Um Ihre Hypothese zu beweisen, zählen Sie für die statistische Analyse die Anzahl an Störchen und Babys in verschiedenen Landkreisen. Mit der Korrelation können Sie den Grad des linearen Zusammenhangs zwischen den Variablen berechnen. In der Tat werden Sie eine positive Korrelation feststellen. Das heisst, je mehr Störche ein Landkreis hat, umso mehr Babys gibt es dort. Mit der Korrelation haben Sie aber nur einen indirekten Zusammenhang nachgewiesen. Tatsächlich hängen beide Variablen mit der Ländlichkeit zusammen. Ländliche Regionen bieten Störchen und Familien mit Kindern gleichermassen gute Lebensbedingungen. Dagegen sind die Grossstädte eher von Singles bevölkert und Störche finden dort weniger Natur vor. Es handelt sich bei dem Zusammenhang zwischen Störchen und Babys also nur um eine Scheinkausalität.
Zu den oben aufgeführten Methoden haben wir Ihnen einige typische Fehlerquellen tabelliert:
| Methode | Mögliche Fehlerquellen |
| Stichprobe | Keine Zufallsstichprobe; keine Repräsentativität |
| Datengrafik | Irreführende Visualisierung |
| Datenqualität | Gefälschte, fehlerhafte oder unpassende Daten |
| Scheinkausalität | Verwechslung von Korrelation und Kausalität |
| Interne Validität | Störvariablen wurden nicht berücksichtigt |
| Externe Validität | Künstliche Laborbedingungen |
Wie Sie die externe und interne Validität sicherstellen
Für seriöse Forschungsergebnisse muss ein hoher Grad an interner und externer Validität sichergestellt werden.
Eine Schlussfolgerung ist intern valid, falls Alternativerklärungen weitestgehend ausgeschlossen werden können. Die Schlussfolgerung muss also in sich stimmig sein. Die Theorie mit den Störchen und Babys ist beispielsweise nicht intern valid, da der Zusammenhang zwischen Störchen und Babys über die Ländlichkeit vermittelt wird. Um interne Validität zu gewährleisten, sollten Störvariablen kontrolliert und Randomisierungen der Versuchsgruppen durchgeführt werden.
Eine Schlussfolgerung ist extern valid, falls sich die Studienergebnisse auf die Grundgesamtheit verallgemeinern lassen. Zudem sollten sich die Resultate auch auf andere Orte, Zeiten und Situationen übertragen lassen und nicht ausserhalb des Labors ihre Gültigkeit verlieren. Die Berechnung des Pro-Kopf-Verbrauchs von Weissbier in Deutschland in diesem Artikel war zum Beispiel extern nicht valid, weil die auf dem Oktoberfest durchgeführte Stichprobe nicht repräsentativ für die Grundgesamtheit der volljährigen Bevölkerung Deutschlands ist. Um externe Validität zu gewährleisten, sollten Sie sich immer die Frage stellen, ob die Gruppe der Probanden repräsentativ für die Grundgesamtheit ist.
Bei klinischen und epidemiologischen Studien sind hierbei die Einschluss- und Ausschlusskriterien zu berücksichtigen. An der Studie teilnehmende Probanden müssen sämtliche Einschlusskriterien erfüllen. Trifft dagegen mindestens ein Ausschlusskriterium zu, wird der entsprechende Proband von der Studie ausgeschlossen und dessen Messwerte gehen nicht in die statistische Analyse ein. Ergebnisse klinischer Studien können nur auf Patientengruppen übertragen werden, welche vergleichbar sind mit den Probanden. Wenn in der klinischen Studie beispielsweise nur junge Frauen mit Krebs im Anfangsstadium behandelt wurden, können ältere Männer mit Krebs im Endstadium sich nicht unbedingt eine Heilung mit der durchgeführten Therapie erhoffen, auch wenn diese in der klinischen Studie erfolgreich verlief.
Bei Befragungen ist eine hohe Rücklaufquote anzustreben, es sollte also ein grosser Teil aller Befragten den Fragebogen ausfüllen und zurückschicken. Insbesondere bei fehlenden Daten vom Typ „Missing not at random“ erhalten Sie sonst verzerrte Ergebnisse. Wenn Sie beispielsweise eine Umfrage zum Thema Depression durchführen, könnten schwer depressive Personen aufgrund ihrer Krankheit den Fragebogen mit höherer Wahrscheinlichkeit nicht ausfüllen als leicht depressive. Die Non-Responder-Wahrscheinlichkeit hängt somit von der zu untersuchenden Variable ab, wodurch dann das Vorkommen und der Schweregrad von Depressionen in der Bevölkerung unterschätzt wird.
Zusammenfassung
In diesem Artikel haben Sie typische Fallstricke in der Statistik kennen gelernt. Die Gründe für falsche oder manipulierte statistische Analyse sind vielfältig. Viele Wissenschaftler fälschen ihre Forschungsergebnisse, weil positive Resultate mehr Anerkennung und Geld nach sich ziehen als negative. Also werden Daten gefälscht oder solange statistische Hypothesen getestet, bis man das gewünschte positive Resultat erhält. Oder die an sich wahren Zahlen werden mit allerlei statistischen Tricks so dargestellt, dass sie das Gegenteil von dem behaupten, was eigentlich stimmt. Aber auch ehrliche Menschen können unbeabsichtigterweise zu falschen Schlüssen und Fehlinterpretationen kommen. Damit Sie nicht zu den Leuten gehören, die in die Fallen der Statistik-Irrtümer tappen, wissen Sie durch die Lektüre des Artikels nun, worauf bei der Erstellung von Statistiken zu achten ist: Eine gute Datenqualität, die richtige Stichprobenmethodik für eine unverzerrte Schätzung, das Vermeiden zu intensiver Bearbeitungen beziehungsweise der Entfernung von Informationen bei Datengrafiken, das Hinterfragen angeblicher kausaler Zusammenhänge und die Einhaltung von interner und externer Validität.
Falls Sie sicherstellen wollen, dass es bei Ihrem Statistik-Projekt zu keinen Verzerrungen kommt, fragen Sie doch einfach die Statistiker von Novustat um Rat. Unsere Experten können Sie statistisch beraten und dabei helfen, populäre Statistik-Irrtümer zu vermeiden. Und vergessen Sie bei der Datenanalyse nie: Traue keiner Statistik die du nicht selbst gefälscht hast!
Weiterführende Links
[1] https://www.methoden-psychologie.de/korrelation_kausalitaet.html