
Die Clusteranalyse ist ein verbreitetes Standardverfahren in vielen Anwendungsbereichen der Statistik und des Data Minings. Dabei wird oft vergessen, dass die richtige Durchführung, die Anwendung und Interpretation nicht auf den ersten Blick verständlich und greifbar sind. Im folgenden wollen wir Ihnen helfen, sich im Clusternebel zurechtzufinden und Strukturen zu erkennen. Zuerst klären wir die Frage „Was ist eine Clusteranalyse“ und betrachten verschiedene Anwendungsgebiete für eine Clusteranalyse. Anschliessend zeigen wir Schritt für Schritt, wie man eine Clusteranalyse SPSS durchführt und wie man ein Dendrogramm interpretiert. Zuletzt betrachten wir noch die hierarchische Clusteranalyse mit Rapidminer. Bei Fragen hierzu stehen Ihnen unsere Experten gerne zur Verfügung. Nehmen Sie Kontakt mit uns auf! Wir unterstützen gern ihr Data Mining Projekt von der Planung bis zum fertigen Bericht.
Dieser Artikel beantwortet folgende Fragen
- Was ist eine Clusteranalyse?
- Bei welchen Gelegenheiten verwendet man Clusteranalyse?
- Wie funktioniert ein Clustering Algorithmus?
- Wie funktioniert die Berechnung der Clusteranalyse SPSS oder Rapidminer?
- Was versteht man unter einem Dendrogramm?
- Wie interpretiert man das Ergebnis des Clusterings?
Was ist eine Clusteranalyse?
Die Clusteranalyse ist ein exploratives Verfahren, bei dem die Beobachtungen in Gruppen eingeteilt werden. Alle Einheiten, die zu einer Gruppe gehören, sollen dabei untereinander möglichst ähnlich sein. Objekte, die verschiedenen Clustern zugeordnet werden, sollen sich dagegen möglichst deutlich voneinander unterschieden. Bei der Clusteranalyse werden keine statistischen Testungen durchgeführt. Die Einteilung und Auswahl der Gruppen wird stattdessen datenbezogen vorgenommen. Dabei werden keine Gruppen vorgegeben, sondern die Gruppen werden anhand der Muster in den Daten gebildet (Segmentierung). Das ist das wesentliche Unterscheidungsmerkmal zu Klassifikationsverfahren, bei denen die Klassen vom Anwender vorgegeben werden (Sortierung). Dies führt allerdings dazu, dass nach durchgeführter Clusteranalyse die gemeinsamen Eigenschaften eines Clusters beschrieben werden müssen.

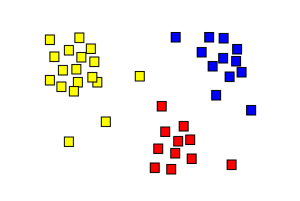
Schauen wir uns dazu das nebenstehende Bild an. Es zeigt eine Ansammlung von Sternen im Weltall. Mit einer Clusteranalyse wird nun beispielsweise die Zahl der Anhäufungen bestimmt und jeder Stern einem dieser Cluster zugeordnet. Im Anschluss an die Gruppierung kann man dann untersuchen, welche Ähnlichkeiten alle Sterne eines Clusters aufweisen.
Clusteranalyse – ein richtiger Allrounder!
Clusteranalysen werden in vielen Bereichen eingesetzt: In der Psychologie werden z.B. Typisierungen von Verhaltensweisen vorgenommen, um eine gezielte Therapie einsetzen zu können. Auch in der Medizin kann eine Differenzierung von Krankheitsbildern nötig sein. Homogene Gruppen können evtl. effektiver behandelt werden. Im Marketing werden Clustering Verfahren zur Marktsegmentierung eingesetzt. Dabei werden geographische Gebiete zu Gruppen mit ähnlichen Absatzmerkmalen zusammengefasst. Neue Produkte können so zunächst auf repräsentativen Märkten eingeführt werden. Im Marketing werden mit Clusteranalysen Segmentierungen vorgenommen, um zielgruppengerecht Produkte anzubieten. Beispielsweise können Personen zu Gruppen zusammengefasst werden, die zu einem bestimmten Thema eine einheitliche Meinung haben. Auch die Gesichtserkennung auf Fotos basiert auf Clusteringalgorithmen.
Clusteranalyse Schritt für Schritt
Die Clusteranalyse wird vielfach als das wichtigste und bedeutendste Verfahren im Bereich des klassischen unüberwachten maschinellen Lernens angesehen. Beginnend mit wenigen Festlegungen werden auf Basis der Daten durch den Algorithmus Gruppen gefunden und gebildet. Welche Festlegungen Sie vorab machen müssen, sehen sie im folgenden Schritt für Schritt.
Eine Clusteranalyse besteht aus vier Teilbereichen:
1. Bestimmung des Unterschieds
Zunächst unterscheidet man zwei Arten, Abstände zu beschreiben: als Distanz oder als Ähnlichkeit. Hat ein Distanzmass den Wert Null, so bedeutet dies maximale Ähnlichkeit. Die Differenzierung der beiden Sichtweisen wird an folgendem Diagramm deutlich:
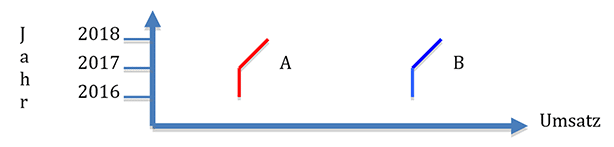
Die Umsatzprofile beider Unternehmen sind gleich, ein Ähnlichkeitsmass liefert daher einen hohen Wert. Unternehmen A und B haben hinsichtlich der absoluten Umsatzzahlen einen grossen Abstand, ein Distanzmass zeigt daher einen kleinen Wert.
Im ersten Schritt werden zwischen jeweils zwei Beobachtungen die Unterschiede (Distanzen) oder Ähnlichkeiten mit geeigneten Masszahlen berechnet. Die Auswahl des Distanzmasses muss dabei vor Beginn der Analyse festgelegt werden. Entscheidend für die Auswahl ist das Skalenniveau der Variablen. Übliche Distanzmasse sind beispielsweise die euklidische Distanz (L2 Norm) bei metrischen Variablen oder der M-Koeffizient bei dichotomen Merkmalen. Als Ähnlichkeitsmass kann man bei stetigen Variablen den Q-Korrelationskoeffizienten verwenden. Bei kategoriellen Merkmalen kann man dagegen den Tanimoto Index einsetzen. Einen detaillierten Überblick über Distanz- und Ähnlichkeitsmasse finden sie in weiterführenden Artikeln.
2. Zusammenfassung der Gruppen (Fusionierung)
Im zweiten Schritt werden die Beobachtungen zu Gruppen zusammengefasst. Massgebend für die Zusammenfassung ist dabei das unter Punkt 1 berechnete Distanz oder Ähnlichkeitsmass. Bei der Zusammenfassung in Gruppen unterscheidet man verschiedene Verfahren:
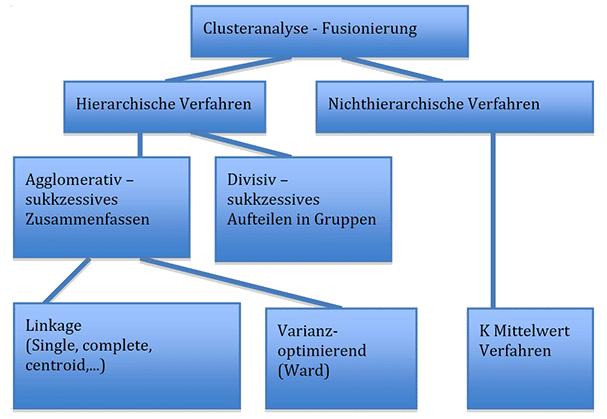
Eine hierarchische Clusteranalyse ist eine Familie von Verfahren, dessen Ergebnis eine Clusterhierarchie ist. Eine hierarchische Clusteranalyse liefert viele Partitionierungen. Der Anwender muss entscheiden, welche Unterteilung am besten für die Anwendung geeignet ist.
Bei hierarchischen Verfahren unterscheidet man zwischen agglomerativen und divisiven Verfahren. Letztere Verfahren gehen zuerst von einem grossen, alle Beobachtungen umfassenden Cluster aus. Dieser Cluster wird dann im weiteren Verlauf in kleinere Gruppen zerteilt. Bei agglomerativen Verfahren bildet anfangs jede Beobachtung einen eigenen Cluster. Im weiteren Verlauf werden diese dann schrittweise zu grösseren Gruppen verbunden. Unter „linkage“ versteht man dabei die Art der Verknüpfung.
Bei nicht-hierarchischen Verfahren wird die Anzahl der Cluster hingegen vorgegeben. Die Daten werden solange zu den Clustern zugeordnet, bis die Varianz innerhalb der Cluster minimal ist.
3. Festlegung der Clusterzahl
Die hierarchische Clusteranalyse weist allen Beobachtungen Clustern zu. Diese werden dann wiederum zu grösseren Clustern fusioniert. Sowohl divisive als auch agglomerative Algorithmen bilden eine Vielzahl von möglichen Gruppenzuteilungen. Im dritten Schritt muss der Anwender schliesslich eine optimale Clusterzahl auswählen. Ein Dendrogramm hilft bei der Entscheidungsfindung.
4. Interpretation und Überprüfung der Güte
Nach der Festlegung der Clusteranzahl müssen die Ergebnisse interpretiert werden. Dafür betrachtet man erneut die Eingabevariablen der Clusteranalyse. Diese Variablen werden z.B. mit Kennzahlen (Mittelwert, Standardabweichung) oder graphisch (Boxplots) zwischen den Clustergruppen verglichen und Unterschiede herausgearbeitet.
Clusteranalyse Beispiel: Mitarbeiterbefragung
Im Folgenden wollen wir eine hierarchische Clusteranalyse SPSS bzw. mit Rapidminer durchführen.
Für dieses Beispiel verwenden wir einen Datensatz aus dem Buch “Multivariate statistische Methoden” von Prof. Litz. Dieser Datensatz enthält Daten aus einer Mitarbeiterbefragung. 50 Mitarbeiter haben auf einer Likert-Skala ihre Meinung zu Personalentscheidungen, Anschaffung an Arbeitsmittel, Arbeitsverteilung, Arbeitsausführung und Arbeitsprozess Abläufen angegeben. Ausserdem wurde das Geschlecht, hierarchischer Status im Betrieb, Ausbildung, Partizipationsprofil und Partizipationspotential erfasst.
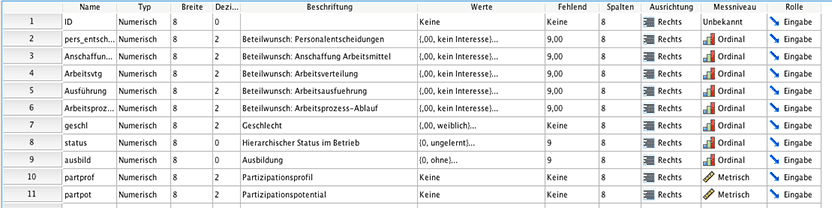
Mit einer Clusteranalyse SPSS sollen nun die Mitarbeiter in Gruppen eingeteilt werden. Die aktiven Variablen, nach denen die Cluster gebildet werden sind Personalentscheidung, Anschaffung an Arbeitsmittel, Arbeitsverteilung, Arbeitsausführung, Arbeitsprozess Ablauf. Aktive Variablen sollten untereinander nicht zu stark miteinander korreliert sein, um mit der Clusterbildung einen möglichst breiten Bereich abzudecken.
Nähere Informationen zur Auswertung ihrer Mitarbeiterbefragung finden Sie auf unseren Serviceseiten. Spezielle Themen wie etwa eine Checkliste für eine erfolgreiche Mitarbeiterbefragung finden Sie in unserem Blog.
Clusteranalyse Beispiel: Hierarchische Clusteranalyse SPSS
Die hierarchische Clusteranalyse wird in SPSS im Menü über Analysieren – Klassifizieren – Hierarchische Cluster aufgerufen. In das Variablenfenster werden die aktiven Variablen eingegeben, die Fallbeschriftung kann anhand der ID stattfinden.
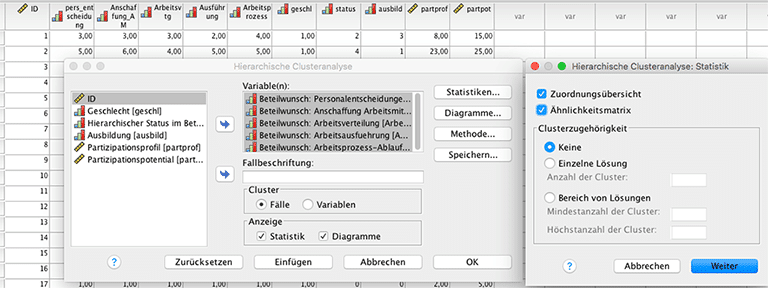
Über das Untermenü Methode kann man die Art der Clusterzusammenführung sowie das Distanz bzw. Ähnlichkeitsmass wählen. Im Untermenü Diagramme sollte Dendrogramm ausgewählt werden, um die Anzahl der Cluster im nachhinein bestimmen zu können.

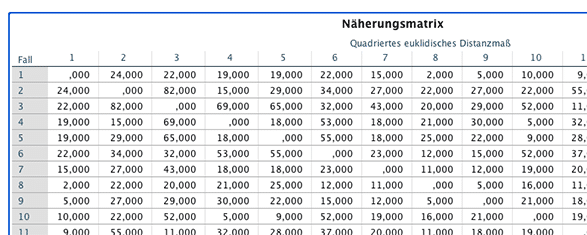
Die Ausgabe enthält zunächst eine Zusammenfassung der Analyse. Anschliessend wird eine grosse Tabelle angegeben, in der die Abstände (hier quadrierte euklidische Distanz) jedes Datenpunktes zu jedem anderen zu sehen sind.
In der folgenden Tabelle ist die Zuordnungsübersicht zu sehen. Zunächst ist bei agglomerativen hierarchischen Verfahren jede Beobachtung ein Cluster. Im ersten Schritt werden die zwei zueinander ähnlichsten Punkte, hier Beobachtung 3 und 17 zu einem Cluster zusammengefügt. Erst in Schritt 7 wird zu diesen beiden Beobachtungen ID 45 hinzugefügt.
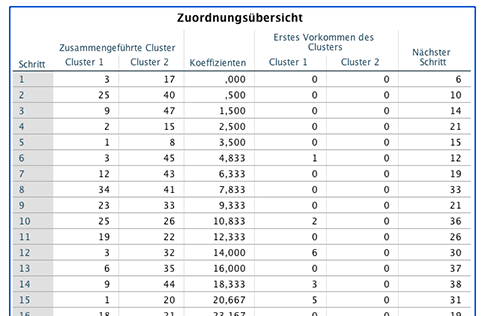
Die Spalte Koeffizienten zeigt ein Mass für die „Uneinheitlichkeit“ innerhalb eines Clusters an. Diese steigt mit jeder hinzugefügten Beobachtung an. Die Zusammenführung von Beobachtungen wird solange fortgeführt, bis alle Beobachtungen in einem Cluster vereinigt sind. Die Heterogenität ist dabei maximal. Das Dendrogramm veranschaulicht die in der Tabelle dargestellten Zusammenhänge.

Dendrogramm Interpretation: Wie findet man die optimalen Anzahl von Clustern?
Das Dendrogramm kann dazu verwendet werden, die optimale Anzahl von Clustern zu bestimmen. Die Anzahl der Cluster sollten idealerweise auch inhaltliche Überlegungen zum Tragen kommen. Die Fusion verschiedener Beobachtungen oder Cluster wird im Dendrogramm mit einer senkrechten Linie gekennzeichnet. Zunächst ist jeder Datenpunkt ein Cluster, diese werden dann sukzessive zusammengefügt. Auf der x-Achse des Dendrogramms wird die Heterogenität innerhalb der Cluster abgetragen, sie wächst mit zunehmender Clustergrösse an. Sind im Diagramm Bereiche mit langen waagrechten Linien, so zeigt dies einen grossen Anstieg an Heterogenität an. Dies sind mögliche Schnittstellen, um die optimale Anzahl an Clustern festzulegen. In obigem Diagramm sind solche möglichen Schnittstellen bei einem Wert von 5 bzw. 10 auf der x-Achse zu sehen. Dadurch entstehen 2 bzw. 3 Cluster Lösungen.
Ein weiteres Beispiel für eine Clusteranalyse SPSS finden Sie in unserem Glossar.
Clusteranalyse Beispiel: Hierarchische Clusteranalyse Rapidminer
Nun wollen wir uns die Durchführung einer agglomerativen Clusteranalyse in Rapidminer betrachten. Eine kurze Einführung in das Programm finden Sie in unserem Blog.
Der zugehörige Prozess ist im Folgenden abgebildet
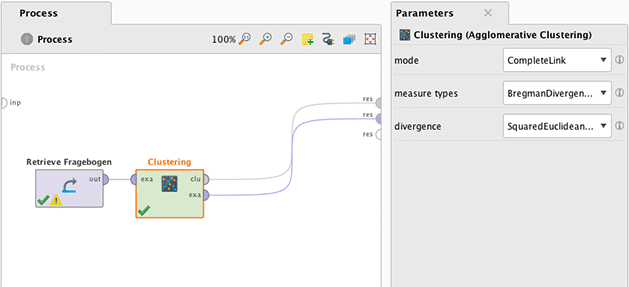
Nach dem Einlesen des Datensatzes wird der Operator Cluster angeschlossen. Als Linkage Verfahren wählen wir complete linkage aus, mir dem Distanzmass quadratische Euklidische Distanz. (Die Verknüpfungsmethode ist damit anders als in der Durchführung mit Clusteranalyse SPSS, um Unterschiede zwischen den Verfahren sehen zu können.)
Führen wir diesen Prozess aus, so erscheint im Ausgabefenster das Dendrogramm.
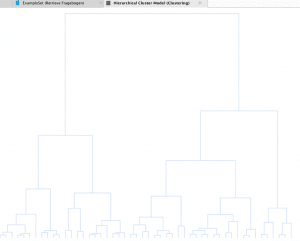
Das Dendrogramm unterscheidet sich vom Dendrogramm aus der Clusteranalyse SPSS. Das liegt daran, dass die Verknüpfung der Cluster anders gewählt wurde.
Darin zeigt sich auch die Schwierigkeit des Clusterings. Es existiert eine grosse Vielzahl an Verfahren, Distanz- und Ähnlichkeitsmassen und Verknüpfungsmethoden. Jede dieser Kombinationen resultiert in anderen Clusterzuordnungen. Dabei gibt es kein richtig oder falsch. Jede Methode hat ihre Berechtigung und Vor- und Nachteile. Eine sinnvolle Clusterzuweisung kann nur mit fachlichem Hintergrundwissen durchgeführt werden.
Interpretation der Clusteranalyse – Was hat das alles zu bedeuten?
Im Anschluss an die Bestimmung der Cluster müssen deskriptiv die Cluster voneinander abgegrenzt werden. Was zeichnet Cluster A aus? Schauen wir uns die Vergehensweise dazu in SPSS an. Wird im Menü hierarchische Clusteranalyse das Untermenü Speichern gewählt, so kann man sich die Clusterzugehörigkeit jeder Beobachtung im Datensatz angeben lassen. Voraussetzung dafür ist aber, dass wie im vorigen Kapitel dargestellt, die Anzahl der Cluster bestimmt wurde. Wir wollen für das Datenbeispiel 3 Cluster erhalten.
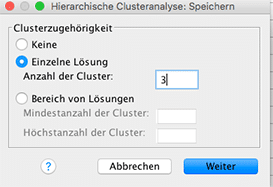
Nach erneuter Ausführung der Clusteranalyse erscheint im Datenblatt eine neue Variable CLU3_1. Anhand dieser Variable können nun die Cluster deskriptiv verglichen werden.
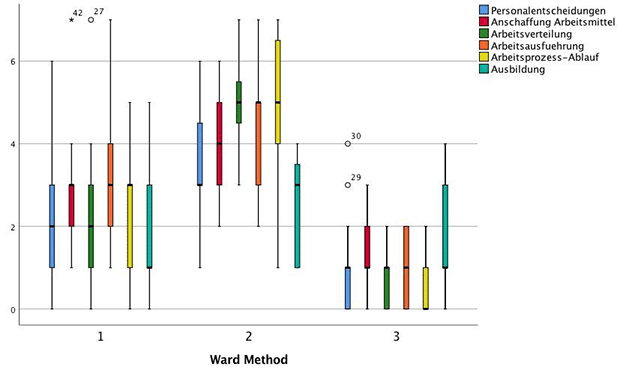
Die Cluster sollen graphisch anhand von Boxplots verglichen werden. Dabei erkennt man, dass Cluster 3 in allen Variablen die niedrigsten Werte zeigt. Beobachtungen, die Cluster 2 zugeordnet werden, haben die höchsten Ausprägungen in den betrachteten Variablen.
Zusammenfassung
Clusteranalyse ist eine etablierte, vielfach eingesetzte Klasse von Verfahren zur Bildung homogener Gruppen. Die verschiedenen Verfahren, Distanz- und Ähnlichkeitsmasse und die Verknüpfung der Cluster untereinander sind zahllos und vielfach unübersichtlich. Dabei gibt es nicht die „richtige“ oder „korrekte“ Clusteranalyse, vielmehr werden die Verfahren oft explorativ eingesetzt und mit Fachwissen geeignete Modelle und Zuweisungen „ausprobiert“. Wenn Sie Unterstützung im Dschungel der methodischen Möglichkeiten benötigen, stehen Ihnen unsere Experten gerne zur Verfügung. Nehmen Sie Kontakt mit uns auf.
Weiterführende Quellen:
Detaillierte Beschreibung hierarchischer und K-means Clusterverfahren