
Skalenfragen, auch als Ratingfragen bekannt, sind ein zentrales Instrument in wissenschaftlichen Umfragen, insbesondere in der Medizin und Psychologie. Sie ermöglichen es, subjektive Einschätzungen wie Patientenzufriedenheit, Symptomschwere oder Therapieerfolge zu quantifizieren und liefern so wertvolle Umfragedaten für die Forschung. Ein kritischer Aspekt liegt dabei in der Rangordnung der Antworten, die differenzierte Einblicke in individuelle Prioritäten und Bewertungen gibt. Doch die korrekte Analyse dieser Daten erfordert methodische Sorgfalt, von der Planung des Fragebogens bis zur Interpretation der Rücklaufquote. um fundierte Aussagen treffen zu können.
Sie planen eine Studie mit Ratingfragen? Sie möchten Ihre Ratingfragen auswerten? Sprechen Sie uns an! Gemeinsam gestalten wir Ihren Erfolg. Eine strukturierte Auswertung von Skalenfragen mit Rangordnung ist essenziell für valide Ergebnisse. Von der Datenaufbereitung über deskriptive Statistik bis hin zu inferenzstatistischen Tests müssen methodische Standards eingehalten werden. Novustat ist Ihr erfahrener Partner für datengestützte Forschung von der Entwicklung geeigneter Skalen, methodisch sauberer Datenerhebung bis zur finalen Datenanalyse. So lassen sich belastbare Erkenntnisse gewinnen, die fundierte wissenschaftliche Entscheidungen unterstützen.
Sie möchten Ihre Umfragedaten professionell auswerten, Ihre Rücklaufquote steigern oder Skalenfragen analysieren? Unsere erfahrenen Statistiker entwickeln mit Ihnen massgeschneiderte Lösungen: von der Fragebogen-Optimierung bis zur finalen Ratingfragen-Auswertung. Lassen Sie sich jetzt unverbindlich beraten und senden Sie uns Ihre Anfrage!
Schritt 1 – Auswertung von Skalenfragen: Wahl der richtigen Ratingfragen/Skalenfragen
Skalenfragen bestehen aus einer vordefinierten Skala, auf der Befragte ihre Einschätzung abgeben. Je nach Fragestellung und Untersuchungsziel kommen unterschiedliche Skalentypen zum Einsatz:
Arten von Skalenfragen
- Likert-Skala: Eine Skala mit fünf oder mehr abgestuften Antwortmöglichkeiten. Diese Skala misst Einstellungen über Kategorien wie „trifft nicht zu“ bis „trifft voll zu“.
- Numerische Ratingskala (NRS): Eine Skala mit Zahlenwerten, häufig von 1 bis 10, die eine einfache quantitative Bewertung ermöglicht. Ideal für quantitative Umfragedaten (z. B. Schmerzintensität).
- Visuelle Analogskala (VAS): Eine kontinuierliche Skala ohne feste Antwortoptionen, bei der Befragte ihre Einschätzung auf einer Linie markieren. Besonders verbreitet ist diese Methode in der medizinischen Forschung, um subjektive Empfindungen wie Schmerz oder Stress zu messen.
- Rangordnungsskalen: Hierbei werden Elemente in eine Rangfolge gebracht, anstatt eine numerische Bewertung zu erhalten. Diese Methode ist besonders sinnvoll, wenn es darum geht, Prioritäten oder subjektive Wichtigkeiten einzelner Aspekte zu analysieren.
Die Wahl der Skala beeinflusst die statistischen Analysemethoden erheblich. Während metrische Skalen eine direkte Berechnung von Mittelwerten erlauben, müssen Rangordnungsskalen mit spezifischen nicht-parametrischen Verfahren untersucht werden.
Schritt 2 – Auswertung von Skalenfragen: Datenaufbereitung – Qualität der Umfragedaten sichern
Bevor Skalenfragen und Rangordnungen analysiert werden können, ist eine sorgfältige Datenaufbereitung erforderlich. Eine fehlerhafte oder unvollständige Datenbasis kann zu verzerrten Ergebnissen führen und die Aussagekraft der Analyse erheblich beeinträchtigen.
Fehlende Werte identifizieren und behandeln
In nahezu jeder empirischen Studie treten fehlende Werte auf, sei es durch unvollständige Beantwortung von Fragebögen oder Datenverluste. Der Umgang mit diesen Lücken hängt von der Art und dem Umfang der fehlenden Daten ab. Bei niedriger Rücklaufquote oder unvollständigen Fragebögen können zum Beispiel Imputationsverfahren notwendig sein.
- Einzelfall-Ausschluss: Falls nur wenige Datenpunkte fehlen, kann ein Ausschluss einzelner unvollständiger Datensätze vertretbar sein.
- Listwise Deletion: Bei grösseren Stichproben können Fälle mit fehlenden Werten aus der Analyse ausgeschlossen werden, wenn dadurch keine systematische Verzerrung entsteht.
- Imputation: Fehlende Werte werden durch plausible Schätzwerte ersetzt, z. B. mittels Mittelwertersatz oder moderner Verfahren wie der multiplen Imputation, um die Informationsverluste zu minimieren.
Kodierung der Antwortoptionen
Für die statistische Analyse müssen verbale Antworten in numerische Werte kodiert werden. Dies ermöglicht Berechnungen und Vergleiche zwischen verschiedenen Gruppen. Je nach Skalentyp erfolgt die Kodierung unterschiedlich:
- Likert-Skalen: Häufig werden fünf oder siebenstufige Skalen numerisch abgebildet (z. B. „stimme gar nicht zu“ = 1 bis „stimme voll zu“ = 5).
- Rangordnungsskalen: Hier werden die Rangplätze numerisch kodiert (z. B. „wichtigste Priorität“ = 1, „zweite Priorität“ = 2 etc.).
- Dichotome Skalen (Ja/Nein-Fragen): Antworten werden meist als 0 (Nein) und 1 (Ja) kodiert.
Eine einheitliche Kodierung ist essenziell, um Fehler in der Analyse zu vermeiden.
Normalitätsprüfung der Verteilung
Viele statistische Verfahren setzen eine normalverteilte Datenstruktur voraus. Daher sollte geprüft werden, ob die Antwortverteilung einer Normalverteilung entspricht. Dies kann durch folgende Methoden erfolgen:
- Visuelle Kontrolle: Histogramme und Q-Q-Plots helfen, Abweichungen von der Normalverteilung zu erkennen.
- Shapiro-Wilk-Test: Ein statistischer Test, der für kleinere Stichproben gut geeignet ist und prüft, ob die Daten normalverteilt sind.
- Kolmogorov-Smirnov-Test: Ein weiteres Verfahren zur Überprüfung der Normalverteilung, insbesondere bei grösseren Stichproben.
Falls die Daten keine Normalverteilung aufweisen, sollten nicht-parametrische Tests, z. B. Kruskal-Wallis-Test statt ANOVA, verwendet werden.
Umgang mit Rangordnungen
Da Rangordnungsskalen keine absoluten Werte, sondern relative Prioritäten widerspiegeln, müssen sie mit spezifischen Methoden ausgewertet werden:
- Spearman-Rangkorrelation: Misst den Zusammenhang zwischen zwei Rangreihen, unabhängig von der Verteilung der Daten.
- Kendall’s Tau: Eignet sich besonders für kleinere Stichproben zur Messung der Übereinstimmung zwischen Ranglisten.
- Kruskal-Wallis-Test: Nicht-parametrischer Test zur Analyse von Gruppenunterschieden bei ordinal skalierten Daten.
Eine sorgfältige Vorbereitung der Daten ist entscheidend für eine valide Interpretation der Skalenfragen und gewährleistet eine fundierte wissenschaftliche Analyse.
Schritt 3 – Auswertung von Skalenfragen: Deskriptive Statistik – Umfragedaten strukturieren
Nach der Datenaufbereitung bildet die deskriptive Statistik die Grundlage für eine erste strukturierte Analyse der erhobenen Daten. Sie ermöglicht es, zentrale Tendenzen, Streuungen und Zusammenhänge zu identifizieren und gibt damit einen Überblick über die Verteilung der Antworten. Besonders bei Skalenfragen mit Rangordnung sind spezifische Kennwerte erforderlich, um eine präzise Interpretation zu ermöglichen.
Berechnung zentraler Kennwerte
Folgende statistische Masse sind besonders relevant:
| Kennwert | Beschreibung |
| Mittelwert | Der Durchschnitt aller Antworten einer Skalenfrage. Dieser Wert ist besonders nützlich für metrische Skalen, aber bei ordinalen Skalen (z. B. Likert-Skalen) nur eingeschränkt interpretierbar. |
| Median | Der zentrale Wert der Verteilung, bei dem 50 % der Werte darüber und 50 % darunter liegen. Besonders sinnvoll bei verzerrten oder nicht-normalverteilten Daten. |
| Standardabweichung | Ein Mass für die Streuung der Antworten. Eine hohe Standardabweichung zeigt eine grosse Variabilität innerhalb der Antworten an, während eine niedrige Standardabweichung auf homogene Antworten hinweist. |
| Häufigkeitsverteilung | Gibt an, wie oft eine bestimmte Antwortkategorie gewählt wurde. Dies kann in absoluten Zahlen oder prozentual dargestellt werden. Häufigkeitsverteilungen sind essenziell für die Analyse von Likert-Skalen oder Ratingskalen. |
| Rangkorrelation (Spearman oder Kendall’s Tau) | Misst die Stärke und Richtung des Zusammenhangs zwischen zwei Rangordnungsvariablen. Dies ist besonders wichtig, wenn es darum geht, Prioritäten oder subjektive Wichtigkeiten einzelner Aspekte zu vergleichen. |
Anwendungsbeispiele und Interpretation der Kennwerte
1. Interpretation des Mittelwerts und der Standardabweichung
Angenommen, eine Umfrage zur Patientenzufriedenheit mit der postoperativen Schmerztherapie wurde durchgeführt, wobei eine Skala von 1 (sehr unzufrieden) bis 5 (sehr zufrieden) verwendet wurde.
Beispielhafte Werte:
- Mittelwert der Bewertungen: 3,8
- Standardabweichung: 1,3
Interpretation:
- Ein Mittelwert von 3,8 zeigt eine tendenziell positive Bewertung, allerdings nicht ausschliesslich sehr hohe Werte.
- Die Standardabweichung von 1,3 signalisiert eine gewisse Streuung: Während einige Patienten sehr zufrieden waren, gab es auch weniger positive Bewertungen.
2. Häufigkeitsverteilung zur Analyse von Trends
Die Häufigkeitsverteilung zeigt, wie oft bestimmte Werte gewählt wurden.
| Bewertung | Anzahl der Patienten | Prozentualer Anteil |
| 1 (sehr unzufrieden) | 5 | 10 % |
| 2 | 7 | 14 % |
| 3 | 12 | 24 % |
| 4 | 15 | 30 % |
| 5 (sehr zufrieden) | 11 | 22 % |
Interpretation:
- Die meisten Patienten vergaben eine Bewertung von 4, was auf eine grundsätzlich positive Wahrnehmung hindeutet.
- 10 % der Befragten gaben die niedrigste Bewertung (1), was auf eine gewisse Unzufriedenheit hinweist.
- Eine detaillierte Analyse könnte nun prüfen, welche Faktoren mit den niedrigeren Bewertungen korrelieren.
3. Rangkorrelation zur Untersuchung von Zusammenhängen
Falls zusätzlich Rangordnungsfragen gestellt wurden, kann mit der Rangkorrelation analysiert werden, wie eng bestimmte Prioritäten miteinander zusammenhängen.
Beispiel:
- Frage: Welche Aspekte der Behandlung sind für Sie am wichtigsten?
- Ergebnis: Patienten ordnen Schmerzreduktion meist auf Platz 1, während Freundlichkeit des Personals und Wartezeiten auf Platz 2 oder 3 variieren.
- Spearman-Rangkorrelation: Zeigt, ob Patienten, die Schmerzreduktion hoch priorisieren, auch andere Faktoren ähnlich einstufen.
Die Berechnung und Interpretation zentraler Kennwerte sind entscheidend für die erste Analyse von Skalenfragen und Rangordnungen. Sie geben einen Überblick über die Verteilung der Antworten, identifizieren Trends und legen die Basis für weiterführende statistische Verfahren. In den folgenden Schritten kann auf diesen Ergebnissen aufgebaut werden, um detailliertere Zusammenhänge zu untersuchen und inferenzstatistische Analysen durchzuführen.
Schritt 4 – Auswertung von Skalenfragen: Reliabilitäts- und Validitätsprüfung – Qualitätssicherung der Skalenbewertung
Die statistische Auswertung von Skalenfragen erfordert nicht nur eine korrekte Berechnung zentraler Kennwerte, sondern aucheine Überprüfung, ob die verwendeten Skalen tatsächlich zuverlässige und valide Ergebnisse liefern. Dies stellt sicher, dass die erhobenen Daten eine hohe Aussagekraft haben und in der Forschung oder Praxis belastbare Schlüsse gezogen werden können.
Reliabilitätsprüfung: Wie zuverlässig misst die Skala?
Die Reliabilität beschreibt die Zuverlässigkeit einer Skala, also die Konsistenz der Messwerte. Eine hohe Reliabilität bedeutet, dass eine Skala unter gleichen Bedingungen immer wieder ähnliche Ergebnisse liefert.
Zentrale Methoden zur Überprüfung der Reliabilität:
| Methode | Beschreibung |
| Cronbachs Alpha | Bestimmt die interne Konsistenz einer Skala. Ein Wert über 0,7 gilt als akzeptabel, Werte über 0,8 als gut und Werte über 0,9 als sehr gut. |
| Test-Retest-Reliabilität | Prüft, ob die gleichen Personen bei wiederholter Befragung mit derselben Skala ähnliche Antworten geben. |
| Split-Half-Reliabilität | Die Skala wird in zwei Hälften geteilt, und es wird überprüft, ob beide Hälften ähnliche Ergebnisse liefern. |
Beispiel:
Eine Umfrage zur Patientenzufriedenheit mit einer 5-Punkte-Likert-Skala ergab einen Cronbachs-Alpha-Wert von 0,82, was auf eine hohe interne Konsistenz hinweist. Dies bedeutet, dass die Skala als zuverlässiges Messinstrument angesehen werden kann.
Validitätsprüfung: Misst die Skala wirklich das, was sie messen soll?
Während die Reliabilität die Zuverlässigkeit einer Skala beschreibt, geht es bei der Validität um die Gültigkeit der Messung. Eine Skala sollte tatsächlich das messen, was sie vorgibt zu erfassen.
Arten der Validitätsprüfung:
| Validitätsart | Beschreibung |
| Inhaltsvalidität | Prüft, ob die Fragen der Skala das gesamte Konzept abdecken (z. B. umfasst eine Skala zur Patientenzufriedenheit alle relevanten Aspekte wie Wartezeiten, Behandlung, Kommunikation). |
| Konstruktvalidität | Zeigt, ob die Skala mit theoretisch verwandten Konzepten korreliert (z. B. sollte eine Skala zur Angstbewertung mit einer Depressionsskala mässig korrelieren). |
| Kriteriumsvalidität | Testet, ob die Skala mit einem externen Kriterium übereinstimmt (z. B. korreliert eine Skala zur Schmerzbewertung mit objektiven medizinischen Indikatoren wie Medikamentenverbrauch). |
Beispiel:
Eine Skala zur Messung von Stresssymptomen sollte mit einer etablierten Skala für Burnout korrelieren (hohe Konstruktvalidität). Falls jedoch Personen mit niedrigen Stresswerten gleichzeitig hohe Burnout-Werte aufweisen, könnte dies auf eine mangelnde Validität der Stressskala hinweisen.
Spezifische Methoden für Rangordnungsdaten
Bei Rangordnungen ist die Überprüfung der Konsistenz besonders wichtig, da kleine Veränderungen in der Bewertung grosse Auswirkungen auf die Interpretation haben können.
- Kendall’s Tau: Misst die Übereinstimmung zwischen zwei Rangordnungsvariablen. Ein hoher Wert zeigt, dass die Rangfolge stabil bleibt und nicht zufällig schwankt.
- Spearman-Rangkorrelation: Überprüft die Korrelation zwischen ordinalen Skalenfragen und kann zur Validitätsprüfung herangezogen werden.
Beispiel:
Eine Umfrage zu den wichtigsten Aspekten der Krankenhausversorgung zeigt, dass Schmerzreduktion und freundliches Personal in fast allen Fällen die obersten Plätze belegen. Die Berechnung von Kendall’s Tau ergibt einen Wert von 0,85, was eine hohe Übereinstimmung der Rangordnungen zwischen verschiedenen Gruppen bestätigt.
Die Qualität einer Skalenmessung steht und fällt mit ihrer Reliabilität und Validität. Eine Skala mit hoher interner Konsistenz, stabilen Ergebnissen und klar definiertem Messbereich bietet die Grundlage für wissenschaftlich fundierte und praxisrelevante Aussagen. Durch gezielte statistische Prüfverfahren kann sichergestellt werden, dass die gewonnenen Erkenntnisse belastbar und interpretierbar sind.
Schritt 5 – Auswertung von Skalenfragen: Inferenzstatistische Analysen – Hypothesen testen und Zusammenhänge in Umfragedaten erkennen
Neben der deskriptiven Analyse, die eine erste Übersicht über die Datenstruktur liefert, sind inferenzstatistische Methoden essenziell, um fundierte Schlussfolgerungen aus Skalenfragen und Rangordnungen zu ziehen. Diese Hypothesen Tests helfen dabei, Unterschiede zwischen Gruppen zu identifizieren oder Zusammenhänge zwischen Variablen zu analysieren.
Vergleich von Gruppen – Unterschiede statistisch prüfen
Häufig werden Skalenfragen genutzt, um zwei oder mehrere Gruppen miteinander zu vergleichen. Die Wahl des geeigneten Tests hängt von der Skalennatur und der Verteilung der Daten ab.
| Testverfahren | Anwendungsbereich | Voraussetzungen | Beispiel |
| T-Test | Vergleich zweier Gruppen mit metrischen Daten | Normalverteilung der Daten in beiden Gruppen | Vergleich der Schmerzintensität vor und nach einer Therapie |
| Mann-Whitney-U-Test | Vergleich zweier Gruppen mit ordinalen oder nicht normalverteilten metrischen Daten | Keine Normalverteilung erforderlich | Patientenzufriedenheit bei zwei unterschiedlichen Behandlungsarten |
| ANOVA (Varianzanalyse) | Vergleich von drei oder mehr Gruppen mit metrischen Daten | Normalverteilung und gleiche Varianzen in den Gruppen | Vergleich der Wirksamkeit von drei verschiedenen Schmerzmedikamenten |
| Kruskal-Wallis-Test | Vergleich von drei oder mehr Gruppen mit ordinalen oder nicht normalverteilten metrischen Daten | Keine Normalverteilung erforderlich | Vergleich der Rangordnung von Behandlungsprioritäten zwischen verschiedenen Altersgruppen |
Beispiel – Anwendung eines T-Tests
Eine Studie untersucht, ob sich die durchschnittliche Schmerzbewertung (Skala 1–10) vor und nach einer Behandlung signifikant unterscheidet.
- Hypothese: Die Schmerzbewertung nach der Behandlung ist signifikant niedriger.
- T-Test-Berechnung in Excel:
- Vor der Behandlung: 6,5 ± 1,2
- Nach der Behandlung: 3,8 ± 1,0
- Formel: =T.TEST(A1:A30, B1:B30, 2, 1)
- p-Wert < 0,05 → Der Unterschied ist signifikant.
Analyse von Zusammenhängen – Korrelationen zwischen Variablen
Neben dem Vergleich von Gruppen können Zusammenhänge bzw. Korrelationen zwischen zwei oder mehr Variablen untersucht werden. Dies ist besonders bei Skalenfragen relevant, um Wechselwirkungen zwischen Einschätzungen oder Verhaltensweisen zu analysieren.
| Korrelationsverfahren | Anwendungsbereich | Interpretation | Beispiel |
| Pearson-Korrelation | Zusammenhang zwischen zwei metrischen Variablen | Werte von -1 bis +1, wobei +1 eine perfekte positive Korrelation bedeutet | Zusammenhang zwischen Medikamentendosis und Schmerzreduktion |
| Spearman-Rangkorrelation | Zusammenhang zwischen zwei ordinalen Variablen oder nicht normalverteilten metrischen Variablen | Misst die Stärke der monotonen Beziehung | Zusammenhang zwischen Patientenzufriedenheit und Wartezeit |
| Kendall’s Tau | Zusammenhang zwischen zwei Rangordnungsvariablen | Stärkere Betonung der Übereinstimmung in Rangordnungen als Spearman | Korrelation zwischen den Rangfolgen von Behandlungspräferenzen verschiedener Patienten |
Beispiel – Anwendung der Spearman-Rangkorrelation
In einer Patientenbefragung wurden zwei Ranglisten erfasst:
- Wichtigkeit von Behandlungsaspekten (z. B. Schmerzreduktion, Freundlichkeit des Personals)
- Zufriedenheit mit diesen Aspekten
Die Spearman-Korrelation wird berechnet, um zu prüfen, ob die subjektive Wichtigkeit mit der tatsächlichen Zufriedenheit übereinstimmt.
- Excel-Formel: =CORREL(RANK.AVG(A1:A30), RANK.AVG(B1:B30))
- Ergebnis: rho = 0,72 → Starker positiver Zusammenhang, d. h. Aspekte, die Patienten für wichtig halten, korrelieren stark mit deren Zufriedenheit.
Durch den gezielten Einsatz statistischer Tests lassen sich aus Skalenfragen belastbare Erkenntnisse gewinnen. Während Gruppenvergleiche Unterschiede zwischen verschiedenen Patientengruppen oder Behandlungsmethoden aufzeigen, helfen Korrelationen dabei, Zusammenhänge zwischen subjektiven Einschätzungen und objektiven Kriterien zu identifizieren. Die korrekte Wahl des statistischen Verfahrens ist entscheidend für valide und aussagekräftige Forschungsergebnisse.
Schritt 6 – Auswertung von Skalenfragen: Anwendung in der Medizin
Die Analyse von Skalenfragen spielt in der medizinischen Forschung eine wesentliche Rolle, insbesondere bei der Erhebung von Patientenzufriedenheit. Ein typisches Beispiel ist die Bewertung der postoperativen Schmerztherapie sowie die Rangordnung der wichtigsten Behandlungsaspekte durch die Patienten.
Beispielhafte Fragestellung und Studiendesign
Fragestellung:
- Wie zufrieden sind Patienten mit der postoperativen Schmerzbehandlung auf einer Skala von 1 bis 5?
- Welche Aspekte der Behandlung halten sie für besonders wichtig?
Die erste Frage wird mittels einer Likert-Skala (1 = sehr unzufrieden, 5 = sehr zufrieden) erfasst. Zusätzlich geben die Patienten an, welche Behandlungsaspekte sie in eine Rangordnung nach Wichtigkeit bringen würden (z. B. Schmerzreduktion, Freundlichkeit des Personals, Wartezeiten).
Fiktive Datenerhebung
Eine kleine Stichprobe von fünf Patienten gibt Bewertungen und Rangordnungen an:
| Patient | Bewertung der Schmerztherapie (1–5) | Rangordnung der wichtigsten Behandlungsaspekte |
| P1 | 5 | 1. Schmerzreduktion, 2. Freundlichkeit des Personals, 3. Wartezeiten |
| P2 | 3 | 1. Freundlichkeit des Personals, 2. Wartezeiten, 3. Schmerzreduktion |
| P3 | 4 | 1. Schmerzreduktion, 2. Wartezeiten, 3. Freundlichkeit des Personals |
| P4 | 2 | 1. Wartezeiten, 2. Schmerzreduktion, 3. Freundlichkeit des Personals |
| P5 | 5 | 1. Schmerzreduktion, 2. Freundlichkeit des Personals, 3. Wartezeiten |
Deskriptive Analyse: Berechnung zentraler Kennwerte
Mithilfe von Excel oder einer Statistiksoftware wie SPSS oder R können dann zentrale Kennwerte berechnet werden:
| Kennwert | Formel in Excel | Ergebnis |
| Mittelwert (Durchschnittliche Zufriedenheit) | =MITTELWERT(B2:B6) | 3,8 |
| Standardabweichung (Streuung der Bewertungen) | =STABW(B2:B6) | 1,3 |
- Der Mittelwert von 3,8 zeigt eine insgesamt positive, aber nicht durchgehend hohe Zufriedenheit.
- Die Standardabweichung von 1,3 weist darauf hin, dass es grosse Unterschiede in den Bewertungen der Schmerztherapie gibt.
Inferentielle Analyse: Zusammenhang zwischen Zufriedenheit und Rangordnung
Um zu überprüfen, ob ein Zusammenhang zwischen der Bewertung der Schmerztherapie und der Priorisierung der Behandlungsaspekte besteht, kann die Spearman-Rangkorrelation berechnet werden.
Hypothese:
- Patienten, die die Schmerztherapie höher bewerten, setzen „Schmerzreduktion“ auch an die erste Stelle in ihrer Rangordnung.
Excel-Berechnung:
- Die Ränge für Schmerzreduktion werden isoliert betrachtet:
- P1: Rang 1, P2: Rang 3, P3: Rang 1, P4: Rang 2, P5: Rang 1
- Berechnung der Spearman-Rangkorrelation mit der Formel:
=CORREL(RANG.AVG(B2:B6), RANG.AVG(D2:D6))
- Ergibt ein ρ (rho) = 0,72, was auf einen starken positiven Zusammenhang hinweist.
Interpretation der Ergebnisse
- Ein ρ-Wert von 0,72 zeigt, dass Patienten mit einer hohen Zufriedenheit mit der Schmerztherapie tendenziell auch die „Schmerzreduktion“ als wichtigsten Faktor einstufen.
- Patienten mit einer geringeren Zufriedenheit (z. B. P4 mit Bewertung 2) setzen hingegen andere Aspekte wie Wartezeiten auf Platz 1.
Skalenfragen: Bedeutung für die medizinische Praxis
Diese Analyse zeigt, wie sich die Bewertung einer medizinischen Behandlung mit der subjektiven Gewichtung einzelner Aspekte verbindet. Für die Praxis bedeutet dies:
Verbesserungspotenzial erkennen: Eine geringe Bewertung könnte durch andere Faktoren als die reine Schmerzreduktion beeinflusst sein (z. B. Wartezeiten oder Personalfreundlichkeit).
Gezielte Massnahmen ableiten: Wenn Wartezeiten stark mit Unzufriedenheit korrelieren, sollten diese in Zukunft minimiert werden, um die allgemeine Patientenzufriedenheit zu steigern.
Datenbasierte Entscheidungen treffen: Die Analyse hilft medizinischen Einrichtungen, ihre Patientenversorgung strategisch zu verbessern, indem sie versteht, welche Aspekte für Patienten am wichtigsten sind.
Diese Methodik kann auf eine grössere Stichprobe ausgeweitet werden, um repräsentativere Ergebnisse zu erhalten und genauere Ableitungen für klinische Entscheidungen zu treffen.
Schritt 7 – Auswertung von Skalenfragen: Visualisierung der Ergebnisse – Auswertung verständlich darstellen
Die Präsentation der Daten ist essenziell für eine verständliche Interpretation und Auswertung von Skalenfragen der gewonnenen Erkenntnisse. In Excel lassen sich Balkendiagramme, Boxplots oder Histogramme nutzen, um Verteilungen und Gruppenvergleiche darzustellen. Rangordnungen können in Heatmaps oder geordneten Balkendiagrammen visualisiert werden. Dies ermöglicht, Prioritäten innerhalb einer Patientengruppe differenziert darzustellen.
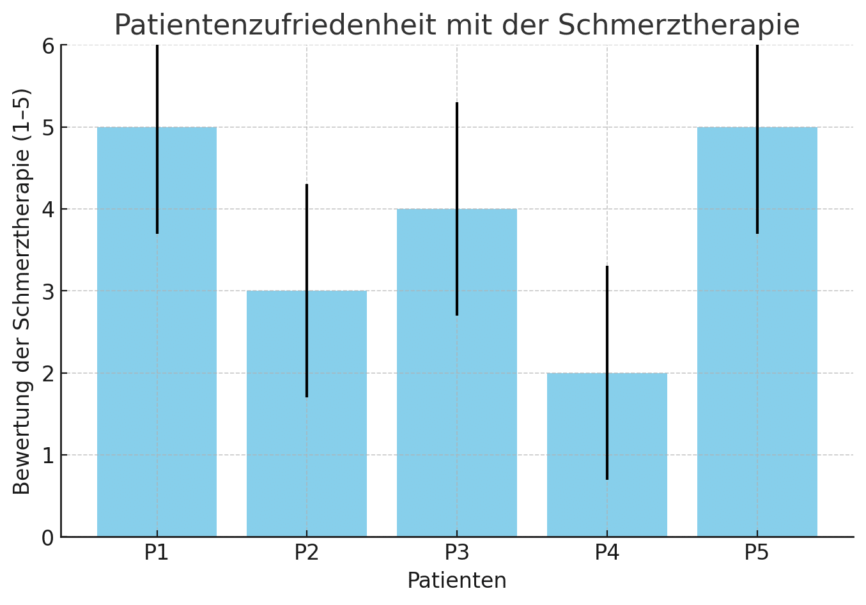
Das Balkendiagramm visualisiert die Bewertung der Schmerztherapie durch fünf Patienten in Kategorien von 1 bis 5. Dabei stellt jeder Balken die individuelle Bewertung eines Patienten dar. Die Werte wurden auf Basis einer Skalenfrage erhoben, bei der die Patienten angeben sollten, wie zufrieden sie mit der postoperativen Schmerzbehandlung sind. Die Skala reicht von 1 (sehr unzufrieden) bis 5 (sehr zufrieden).
Aufbau der Grafik
- X-Achse: Hier sind die fünf Patienten (P1 bis P5) aufgetragen. Jeder Patient gibt eine individuelle Bewertung ab.
- Y-Achse: Sie zeigt die Bewertungsskala von 1 bis 5. Jeder Balken repräsentiert den jeweiligen Wert, den ein Patient für die Schmerztherapie vergeben hat.
- Balken: Die Höhe der Balken gibt die jeweilige Bewertung eines Patienten wieder. Beispielsweise hat Patient P1 eine Bewertung von 5 abgegeben, während P4 nur eine Bewertung von 2 gegeben hat.
Fehlerbalken
Diese schwarze Linie ist ein Fehlerbalken, der die Standardabweichung darstellt. Die Standardabweichung gibt an, wie stark die Bewertungen der Patienten um den Mittelwert schwanken. Ein langer Fehlerbalken bedeutet eine hohe Streuung, also starke Unterschiede in den Bewertungen. Ein kurzer Fehlerbalken zeigt an, dass die Werte relativ nah beieinanderliegen.
In diesem Beispiel zeigt der Fehlerbalken, dass es gewisse Abweichungen in den Bewertungen gibt, aber die Mehrzahl der Patienten sich im oberen Bewertungsbereich (4–5) befindet. Dennoch gibt es einen Patienten mit einer sehr niedrigen Bewertung (2), was eine hohe Schwankung in der Zufriedenheit verdeutlicht.
Interpretation der Ergebnisse
- Allgemeine Tendenz: Die Mehrheit der Patienten bewertet die Schmerztherapie positiv (Mittelwert: 3,8), aber es gibt eine gewisse Variabilität.
- Einzelne Unzufriedenheit: Die Bewertung von Patient P4 (2) zeigt, dass nicht alle Patienten zufrieden sind. Dies könnte auf individuelle Unterschiede oder Probleme in der Schmerzbehandlung hinweisen.
- Nutzen der Fehlerbalken: Diese helfen Forschern zu beurteilen, ob es eine starke Varianz in der Zufriedenheit gibt und ob die Bewertung einer Person möglicherweise ein Ausreisser ist.
Das Balkendiagramm mit Fehlerbalken ist eine effektive Methode, um die Verteilung und die Streuung von Skalenfragen darzustellen. Insbesondere in medizinischen Studien hilft es, Unterschiede zwischen Patienten zu identifizieren und mögliche Optimierungsbereiche in der Behandlung zu erkennen.
Wie Sie die Rücklaufquote steigern: Praxistipps für aussagekräftige Umfragedaten
Warum die Rücklaufquote so wichtig ist
Eine hohe Quote (ideal: >70 %) erhöht nicht nur die Repräsentativität der Umfragedaten, sondern reduziert auch den Aufwand für die Nachbearbeitung fehlender Werte. Beispiel: Bei einer Rücklaufquote von 30 % müssen Sie mit starken Verzerrungen rechnen, da möglicherweise nur eine bestimmte Bevölkerungsgruppe (z. B. besonders motivierte Patienten) antwortet. Nutzen Sie unsere Expertise, um Ihren Fragebogen und Versandprozess zu optimieren. Wir analysieren Ihre Zielgruppe, entwickeln ansprechende Einladungstexte und setzen Tools ein, die die Rücklaufquote automatisch tracken: für valide Daten von Anfang an.
Die Rücklaufquote, also der Anteil der ausgefüllten Fragebögen im Verhältnis zur Gesamtzahl der Versandten, ist ein zentraler Erfolgsfaktor für die Validität Ihrer Umfrage. Eine niedrige Quote kann zu verzerrten Ergebnissen führen, da nicht alle Zielgruppen gleichermassen repräsentiert sind. Mit diesen Strategien erhöhen Sie die Rücklaufquote und sichern die Qualität Ihrer Daten:
Zielgruppengerechte Ansprache
- Personalisieren Sie Einladungstexte (z. B. „Sehr geehrte Frau Müller, Ihre Meinung ist uns wichtig!“).
- Erklären Sie den Nutzen der Umfrage für Teilnehmer (z. B. „Ihre Antworten helfen, die Patientenversorgung zu verbessern“).
Fragebogen optimieren
- Halten Sie den Fragebogen kurz (max. 10–15 Minuten Bearbeitungszeit).
- Verwenden Sie klare Kategorien und vermeiden Sie doppelte Negationen (z. B. „Ich bin nicht unzufrieden“).
Anreize schaffen
- Bieten Sie Identitives wie Gutscheine, Teilnahme an Verlosungen oder Zusammenfassungen der Ergebnisse an.
- Beispiel: „Als Dankeschön erhalten Sie einen 10-€-gutschein oder exklusive Einblicke in die Studienergebnisse.“
Erinnerungen senden
- Setzen Sie strategische Follow-ups ein:
- 1. Erinnerung nach 7 Tagen,
- 2. Erinnerung nach 14 Tagen mit verkürzter Deadline.
- Formulieren Sie freundlich und wertschätzend: „Wir möchten Sie herzlich bitten, noch fehlende Fragen zu ergänzen.“
Technische Hürden minimieren
- Stellen Sie sicher, dass der Fragebogen auf allen Endgeräten (Smartphone, Tablet, PC) gut bedienbar ist.
- Testen Sie Links und Buttons vor dem Versand – nichts frustriert mehr als abgebrochene Umfragen wegen technischer Fehler.